MongoDB Timeseries를 활용기

사건의 발단
안녕하세요, 비브로스에서 백엔드 개발을 하고 있는 배정석입니다.
비브로스에는 기존부터 운영하고 있는 로그 관련 서비스를 제공하는 서버가 있었습니다.
이름하야 로-그 서버!
...는 레거시라고 밖에 부를 수 없는 신세가 되어 있었죠.
그래서 이참에 리팩토링하고, 플랫폼화 하여서 다양한 로그들을 수집하고 분석할 수 있게 만들어보자! 라는 얘기가 나오면서 Timeseries DB를 활용해서 만들어보자는 얘기까지 진척되게 됩니다.
그 이후로 여차저차해서 그 일은 제 일이 됩니다.

Timeseries DB가 뭐야?
저는 Timeseries 이름만 들어봤지, 써본 적이 없어서 공부를 시작했습니다.
아래는 제가 Timeseries 를 공부하면서 정리한 내용 중 일부입니다.
정의
- 시계열 데이터를 저장하는 ��데이터베이스
시계열 데이터(Timeseries Data): 일정 시간 간격으로 배치된 데이터셋
특징
- 데이터를 시간을 기준으로 인덱싱하여 보관.
- mongoDB를 기준으로 설명하자면, 버킷 패턴을 내부적으로 구현. ( 시간의 범위에 대한 부분을
granulity로 표현) - 시간에 따라 데이터들이 최적화되어있기 때문에, 시간이 지나도 데이터를 수집하는 속도가 느려지지 않고 빠른 처리 속도를 보여줌.
- mongoDB를 기준으로 설명하자면, 버킷 패턴을 내부적으로 구현. ( 시간의 범위에 대한 부분을
- 과거의 데이터를 시간과 함께 기록용으로 저장하므로 주된 작업은
CREATE와 조회기능인READ UPDATE와DELETE기능은 상당히 제한됨.
시간 순으로 저장한다는게 어떤 것일까?
시계열 데이터가 무엇인지 알아보았고, 이번엔 시계열 데이터를 어떻게 저장하는지에 대해 알아봅시다.
좌: 일반 컬렉션, 우: Timeseries 컬렉션
 |  |
|---|
좌측의 일반 컬렉션과, 우측의 시계열 컬렉션의 데이터 수집/저장 방식을 보면 차이점을 확연하게 알 수 있습니다.
왜 위와 같은 방식이 고안되었는가에 대한 내용은 mongoDB Timeseries의 전신이나 마찬가지인 Bucket Pattern을 보면 알 수 있습니다.
Bucket Pattern
좌: 일반 데이터, 우: Bucket Pattern 이 적용된 데이터
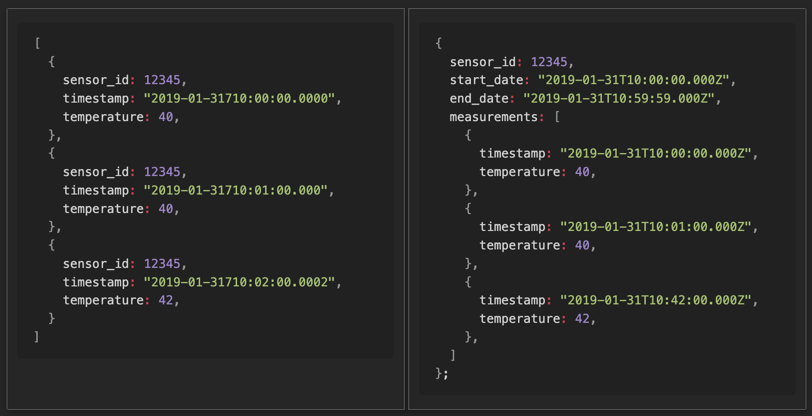
Bucket Pattern은 스키마 디자인 패턴 중의 하나입니다.
일반적으로 데이터를 DB에 적재하게 될 때, 좌측 데이터와 같은 형태로 쌓게 됩니다.
여기서 각 document에 timestamp의 범위를 제한한다고 해봅시다. 이 경우에는 특정 구간의 timestamp && sensor_id 를 기준으로 Index를 만든 것이나 마찬가지가 됩니다.
위 패턴은 효율적으로 1:N 관계를 표현할 수 있었지만, 여럿 불편한 점이 있었습니다.
가령 BSON의 크기 제한인 16mb를 넘어가는 경우에는 별도의 처리를 해줘야 한다던지, 적재한 데이터를 다시 분리해서 가져오는 과정 등이 말이죠.
MongoDB 5.x 부터 내부적으로 Bucket pattern을 구현한 Timeseries collection을 지원하면서 이런 번거로움이 사라졌죠.
MongoDB 영업사원 아닙니다.
실제 MongoDB는 Timeseries 데이터를 어떻게 저장할까?
이론적인 배경이나 마찬가지인 Bucket Pattern에 대해 알아보았으니, 실제 데이터는 어떻게 저장되는지를 알아봅시다.
아래와 같은 쿼리로 값을 마구잡이로 10 개의 데이터를 넣어보면...
db.getCollection("action-logs").insertOne({
timestamp: new Date(),
data: {
value: Math.random()
},
metadata: {
"id": "1234567890",
"source": "urn:ddocdoc:hospital-admin"
}
});
// system.bucket.action-logs
{
"_id": "65d3eb80b6473e96f1b570c7",
"control": {
"version": 1,
"min": {
"_id": "65d418420498d3b000d19641",
"timestamp": "2024-02-20T00:00:00.000Z",
"data": {
"value": 0.04303943091823581
}
},
"max": {
"_id": "65d418f00498d3b000d1964b",
"timestamp": "2024-02-20T03:13:52.049Z",
"data": {
"value": 0.8827539992979445
}
}
},
"meta": {
"id": "6093b741070ad40011cabbae",
"source": "urn:ddocdoc:hospital-admin"
},
"data": {
"_id": {
"0": "65d418420498d3b000d19641",
"1": "65d418ec0498d3b000d19642",
"2": "65d418ed0498d3b000d19643",
"3": "65d418ee0498d3b000d19644",
"4": "65d418ee0498d3b000d19645",
"5": "65d418ee0498d3b000d19646",
"6": "65d418ee0498d3b000d19647",
"7": "65d418ef0498d3b000d19648",
"8": "65d418ef0498d3b000d19649",
"9": "65d418ef0498d3b000d1964a",
"10": "65d418f00498d3b000d1964b"
},
"timestamp": {
"0": "2024-02-20T03:10:58.414Z",
"1": "2024-02-20T03:13:48.823Z",
"2": "2024-02-20T03:13:49.553Z",
"3": "2024-02-20T03:13:50.025Z",
"4": "2024-02-20T03:13:50.371Z",
"5": "2024-02-20T03:13:50.671Z",
"6": "2024-02-20T03:13:50.952Z",
"7": "2024-02-20T03:13:51.272Z",
"8": "2024-02-20T03:13:51.490Z",
"9": "2024-02-20T03:13:51.738Z",
"10": "2024-02-20T03:13:52.049Z"
},
"data": {
"1": {
"value": 0.6954380762758321
},
"2": {
"value": 0.8276404308193761
},
"3": {
"value": 0.06242745352637269
},
"4": {
"value": 0.548645414603997
},
"5": {
"value": 0.8495674421359376
},
"6": {
"value": 0.04303943091823581
},
"7": {
"value": 0.6313514590828619
},
"8": {
"value": 0.8827539992979445
},
"9": {
"value": 0.1477508498242106
},
"10": {
"value": 0.818804826373378
}
}
}
}
자체적으로 Bucket Pattern을 구현할 것을 볼 수 있습니다!
위 데이터는 system.buckets.[collection_name] 을 까보면 볼 수 있습니다. 조회 권한 달라고 하세요
Bucket 으로 저장된 데이터는 어떻게 다시 파싱해서 가져오는가?
지금까지 내부적으로 버킷 패턴을 이용해 DB 내부에 저장하는 것까지 확인하였습니다.
이제는 버킷 패턴으로 저장된 데이터를 어떻게 내가 넣었던 데이터 포맷으로 다시 받아올 수 있는지를 알아보도록 합시다.
mongoDB는 내부적으로 $_internalUnpackBucket 연산을 통해 bucket화된 doucment를 원래 형태로 파싱해서 가져옵니다.
실행 과정에서 $_internalUnpackBucket가 들어가 있는지 확인해보도록 합시다.
explain() 명령어를 통해 실행 stage를 까 봅시다.
{
stages: [
{
$cursor: {
queryPlanner: {
winningPlan: {
stage: "CLUSTERED_IXSCAN"
}
}
}
},
{
$_internalUnpackBucket: {
"timeField": "timestamp",
...
}
}
]
}
- 위 stage는 두 단계를 거칩니다.
CLUSTERED_IXSCAN (인덱스 스캔)$_internalUnpackBucket (버킷 언팩).
1번은 제가 조회 쿼리를 인덱스를 타게 만들었기 때문에 무시하시면 되고,
2번의 $_internalUnpackBucket이 포함된 것을 확인할 수 있습니다!

우리는 어떻게 TSDB를 사용하고 있나?
이제까지 Timeseries의 동작방식에 대해 살펴봤습니다.
이제부터는 기술적이라기보다는 저희 내부적인 합의에 대한 내용을 간략하게 소개해드리고자 합니다.
저희도 어떻게 하면 더 잘 쓸 수 있는지에 대해 고민하고 있는 단계인지라, "쟤네는 저렇게 쓰고, 저런 고민을 했구나" 정도로 받아들여 주시면 좋을 것 같습니다.
전체적인 도식을 그려보자면 아래와 같습니다.
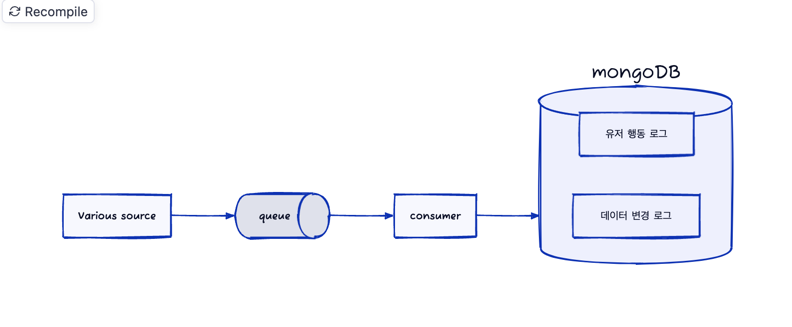
저희는 저장이 필요한 데이터를 크게 두 가지로 분류하였습니다.
유저 행동: 어떤 소스에서 어떤 행동 데이터가 들어왔는지에 대한 내역을 저장데이터 변경: 어떤 컬렉션의 데이터가 변경되는지에 대한 내용을 저장
// 유저 행동
{
...
metadata: {
id: 'action_id',
source: 'urn:source:...'
},
data: {
...
}
}
// 데이터 변경
{
...
metadata: {
id: 'document_id',
collection: 'urn:collection:...'
},
data: {
...
}
}
음... 이 외에도 좀 더 상세한 설명을 하고 싶은데, 이게 다라서 뭐 적을게 없군요.

위의 포맷과 함께 고민했던 내용들
위의 구조만 설명하기는 아쉬워서 추가적으로 어떤 고민들을 했는지 러프하게나마 조금 더 적어봤습니다.
- 데이터 변경 로그를 적재할 때, 만약
mongoDB의 데이터 변경이 아니면 어떻게 하지?- ➡️
urn 규칙을 도입
- ➡️
- 적재할 데이터마다
granulity를 다르게 설정했다면, 디스크 사용량이나 인덱싱이 조금 더 효율적이지 않았을까?- 언젠가 유저 행동, 데이터 변경 등의 추상적인 개념에서 세부적인 데이터로 쪼개서 가져갔으면 좋겠다.
현재로선 그렇게 현실적이지는 않지만...
- 언젠가 유저 행동, 데이터 변경 등의 추상적인 개념에서 세부적인 데이터로 쪼개서 가져갔으면 좋겠다.
ttl은 6개월이면 충분하겠지?secondary Index는 어떻게 쓸까?기본 설정(metaField & timeField)인덱스만 써도 될 것 같은데?
Index를 걸지는 않았는데, data 내부의 특정 값을 조회하고 싶어.이제 와서 인덱스를 걸기엔 데이터가 너무 많이 쌓였음- 꼭 인덱스를 걸지 않았어도,
BUCKET을 먼저 지정해서 가져오면 그 안의 데이터만 까볼테니 성능 저하가 그렇게 크지는 않지 않을까?
- 꼭 인덱스를 걸지 않았어도,
마치며
위에 적은 고민들 외에도 더 많은 고민이 있었지만, 이건 TSDB에 연관된 고민이야! 라고 자신있게 말 할 수 있는 것들을 제외하고는 적지 않았습니다. 왜냐하면 부끄럽기 때문이죠
개인적으로는 event sourcing 패턴과 같이 쓰면 잘 어울릴 것 같다는 생각을 하고 있는데, 언젠가 써 볼 기회가 있으면 좋겠습니다.
제 식대로 정리해봤는데 이 글이 MongoDB Timeseries 도입을 고민하시는 분들께 조금이라도 도움이 되면 좋겠습니다.
감사합니다! 😄
Reference
- Building with Patterns: The Bucket Pattern | MongoDB
- Quote from “[TSDB] 시계열 데이터베이스(TSDB, Time Series Database) 란? - (1/2) - MangKyu's Diary”
- Paginations 1.0: Time Series Collections in five minutes | MongoDB
- [MongoDB] Timeseries Collection에 대한 연구
- MongoDB Windows functions and time-series performance | by Guy Harrison | MongoDB Performance Tuning | Medium