DevLake를 활용한 DORA Metrics 지표 수집 및 시각화 도입기

안녕하세요, 비브로스 DevOps 엔지니어 박도준 입니다.
최근 DevOps 팀에서는 개발 효율성과 안정성을 객관적인 지표로 검증하기 위한 다양한 작업들을 수행하고 있습니다.
그중 이번 글에서는 DORA Metrics 도입 사례를 소개하려 합니다. 지표를 어떻게 수집하고 시각화했는지, 그리고 그 과정에서 겪은 이슈들을 어떻게 해결했는지에 대해 공유드리겠습니다.
DORA Metrics 도입 배경
DORA Metrics를 도입한 배경은 아래 두가지입니다.
첫째, 지난 1~2년간은 CI/CD 환경을 자동화하고 안정화하는 데 집중했고, 이제는 그 결과를 객관적인 지표로 검증하고 개선할 수 있는 환경이 필요해졌습니다.
둘째, AI 도구의 빠른 발전과 확산으로 사내에서도 업무 효율 향상을 위해 AI를 적극 활용하고 있습니다.
그러던 중 문득 아래와 같은 궁금증이 생겼습니다.
“AI 도입으로 실제 생산성이 향상되었을까?”
”AI 사용이 안정성에 부정적인 영향을 주지는 않을까?”
위 두 가지 배경은 "측정할 수 없다면, 개�선할 수도 없다"는 피터 드러커의 말처럼 객관적인 지표가 필요했고, 최종적으로 DORA Metrics를 활용한 측정 체계를 도입하게 되었습니다.
DORA Metrics란?
DORA Metrics는 소프트웨어 딜리버리 성과를 정량적으로 측정하기 위한 핵심 지표 체계입니다.
여기서 DORA(DevOps Research and Assessment)는 지난 10년 이상 우수한 소프트웨어 팀과 조직의 성과, 문화, 관행 및 측정 방법을 연구해온 연구 프로젝트입니다.
해당 연구에서 반복적으로 검증된 4가지 핵심 지표를 정의했고, 이를 DORA Four Keys라고 부릅니다. 이 지표는 크게 소프트웨어 변경의 처리량과 안정성 두 가지 항목으로 분류됩니다.
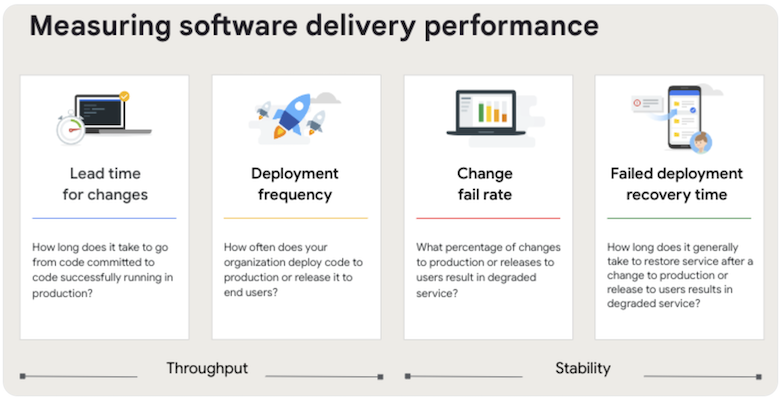
- 변경 리드 타임 (Change Lead Time):** 코드 커밋 또는 변경 사항이 성공적으로 프로덕션에 배포되는 데 걸리는 시간
- 배포 빈도 (Deployment Frequency): 애플리케이션 변경 사항이 프로덕션에 얼마나 자주 배포되는지를 측정
- 변경 실패율 (Change Fail Rate): 프로덕션에 배포된 변경 사항 중 실패를 유발해 핫픽스나 롤백이 필요한 배포의 비율
- 실패한 배포 복구 시간 (Failed Deployment Recovery Time): 프로덕션에서 발생한 실패로부터 복구하는 데 걸리는 시간
환경 구성
도구 선정
DORA Metrics 수집 및 시각화를 위해 다양한 도구를 검토했습니다.
내부 인프라 환경과 운영 방식에 맞춰, 다음과 같은 기준으로 후보 도구들을 비교 분석했습니다.
- 오픈소스 여부 : 비용 최소화 및 커스터마이징 가능성
- 시각화 연동성 : Grafana 등 기존 대시보드와의 통합 여부
- 데이터 연동 범위 : Github, Jira 등 기존 도구와의 통합 가능성
- 설치/운영 제약 : 클라우드 의존성, 설치 복잡도, 유지보수 상태 등
아래는 주요 도구에 대한 비교 표입니다.
| 도구 | 오픈소스 | Grafana 연동 | GitHub 연동 | Jira 연동 | 기타 제약 사항 |
|---|---|---|---|---|---|
| Apache DevLake | ✅ | ✅ | ✅ | ✅ | Docker/Kubernetes 필요 |
| Four Keys (by Google) | ✅ (아카이브됨) | ✅ | ✅ | ❌ (제한적) | GCP 필요, 유지보수 중단 |
| Sleuth | ❌ | ❌ | ✅ | ✅ | 커스터마이징 어려움 |
| Atlassian Compass | ❌ | ✅ | ✅ | ✅ | 서비스형 중심, 확장성 제한 |
위 비교 결과를 바탕으로, Apache DevLake를 최종 선택했습니다.
설치를 위해 Docker/Kubernetes 환경이 필요하다는 제약이 있지만, 이미 내부적으로 EKS 환경을 운영하고 있어 큰 제약이 되지 않았습니다.
DevLake 구성
[DevLake 아키텍처 요약]
DevLake는 다양한 DevOps 도구로부터 데이터를 수집하고 정제한 뒤, 이를 시각화하여 엔지니어링 효율성과 개발자 경험 개선에 도움이 되는 인사이트를 제공하는 오픈소스 플랫폼입니다.
DevLake의 전체 구성은 아래와 같이 이루어져 있습니다.
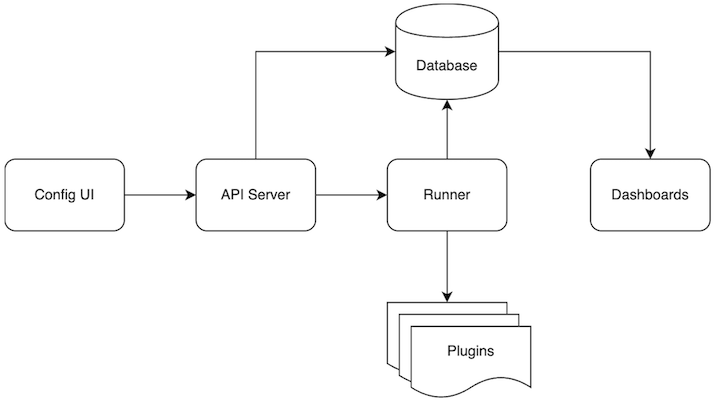
- Config UI
- 블루프린트를 생성·실행·디버깅할 수 있는 웹 UI로, 데이터 소스 위치, 수집 범위, 변환 방식, 동기화 주기 등을 설정합니다.
- API Server
- DevLake의 메인 API 인터페이스로, 설정된 정보를 바탕으로 Runner 및 Dashboard와 통신합니다.
- Runner
- 실제 수집 작업을 실행하는 컴포넌트로, 플러그인을 통해 데이터를 가져옵니다.
- 기본적으로 API Server 안에서 작동하며, 시간 기반 실행도 지원합니다. (beta)
- Database
- 수집된 메타데이터와 사용자 데이터를 저장합니다. (MySQL 및 PostgreSQL 지원)
- Plugins
- GitHub, Jira, Jenkins 등 다양한 DevOps 도구와 연동되는 플러그인을 통해 데이터를 수집·분석할 수 있습니다.
- Dashboards
- Grafana 기반의 대시보드에서 데이터를 시각화하여 인사이트를 제공합니다.
[데이터 처리 구조]
DevLake의 데이터 수집 흐름은 3단계 레이어 구조로 구성되어 있으며, 다양한 도구의 데이터를 통일된 형태로 가공하는 데 유리합니다.
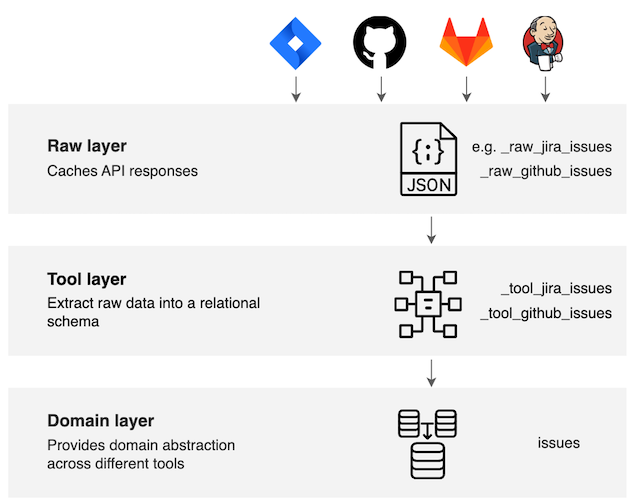
- Raw Layer (원시 레이어)
- DevOps 도구의 API 응답을 JSON 형태로 저장합니다.
- 이는 중복 호출 방지, 캐시 활용, 후처리 편의성을 위한 원시 데이터 저장소 역할을 합니다.
- Tool Layer (도구 레이어)
- Raw 데이터를 DevOps 도구별 스키마에 맞게 가공합니다.
- Domain Layer (도메인 레이어)
- 다양한 도구의 데이터를 공통 도메인 모델로 추상화합니다
- 예를 들어, GitHub PR과 GitLab PR은 tool layer에선 별도 테이블이지만, domain layer에선 하나의 테이블로 통합됩니다.
[핵심 개념 (Key Concepts) 요약]
DevLake를 구성하는 주요 설정 요소들은 다음과 같습니다.
- Data Source : GitHub, GitLab, Jira 등 데이터를 수집할 DevOps 도구
- Data Scope : 데이터 소스에서 수집할 단위 (예: GitHub 레포지토리, Jira 보드)
- Scope Config : 수집 대상에 적용할 데이터 필터 및 변환 규칙
- Project : 수집된 데이터 단위를 그룹화하여 하나의 분석 단위로 정의한 개념 (예: A 서비스 백엔드 개선)
- Blueprint: 어떤 데이터 소스를 언제, 얼마나 자주 수집할지를 정의하는 실행 계획
각 개념에 대한 자세한 설명 및 추가 구성 요소는 공식 문서 참고 바랍니다.
[전체 구조 요약도]
아래는 DevLake 설정 요소 간의 관계를 도식화한 예시입니다.
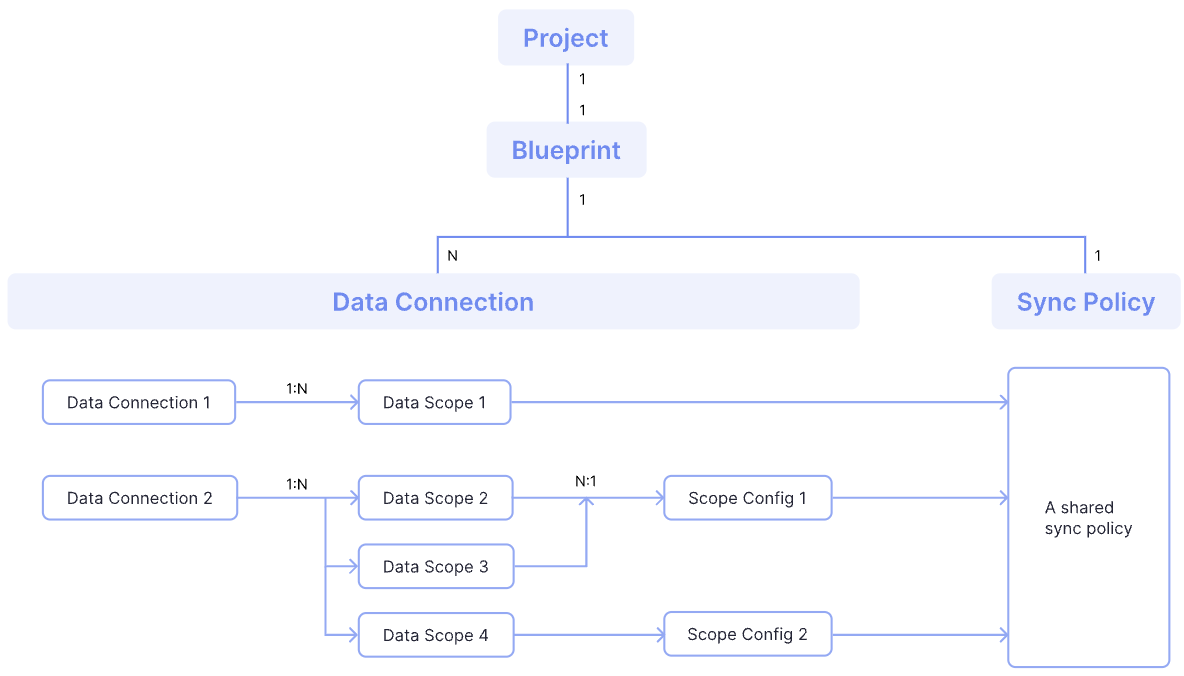
- 하나의 Project는 하나의 Blueprint를 가집니다.
- 하나의 Blueprint는 여러 Data Connection을 가질 수 있습니다.
- 하나의 Data Connection은 여러 Data Scope를 가질 수 있습니다.
- 각 Data Scope는 하나의 Scope Config를 가집니다.
- 모든 Scope는 공통된 Sync Policy를 공유할 수 있습니다.
DevLake 환경 구성
[DevLake 설치 방식]
DevLake는 다음 2가지 방식으로 설치가 가능합니다.
저희 팀은 EKS 환경에서 인프라를 운영 중이였기에, Helm을 이용하여 DevLake를 설치했습니다.
Helm Chart를 통해 DevLake 주요 컴포넌트와 아래 구성 요소들을 함께 구성했습니다.
- DB : DevLake의 메타데이터 저장을 위해 MySQL 사용
- 시각화 : 내부에서 운영 중인 Grafana와 연동하여 대시보드 구성
설치 시, 사용한 버전은 다음과 같습니다.
- DevLake: v1.0.1
- MySQL : v8
- EKS (Kubernetes): v1.32
- Grafana: v11.5.2
버전 간 호환성은 DevLake 공식 문서 기준에 따랐으며, 일부 구성 요소는 환경에 맞게 Helm Chart를 커스터마이징하여 적용했습니다.
자세한 설치 절차와 옵션 값은 DevLake 공식 문서 참고 바랍니다.
최종 구성된 아키텍처는 다음과 같습니다.
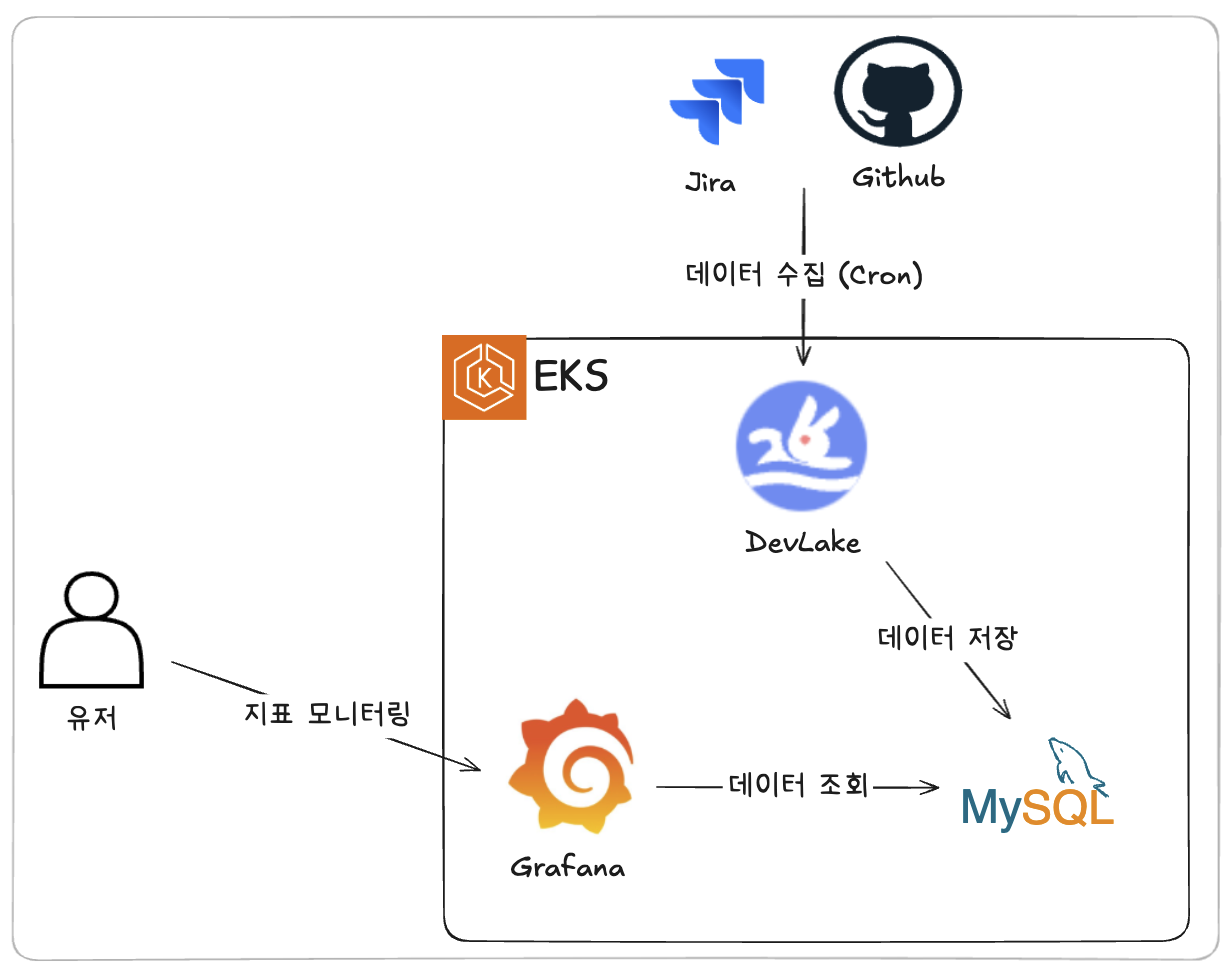
[DevLake 설정]
설치가 완료되면 DevLake UI를 통해 지표 수집을 위한 설정을 진행합니다.
아래 예시에서는 Github을 데이터 소스로 추가해 프로젝트를 생성하는 과정을 예시로 설명합니다.
1️⃣ Data Source 연결
DevLake에서 데이터를 수집하려면 먼저 GitHub, Jira 등 외부 도구와 연결을 설정해야 합니다.
이 단계에서는 각 도구별 인증 정보와 엔드포인트 등을 입력해 연결을 구성합니다.
Connections → GitHub →
Create a New Connection
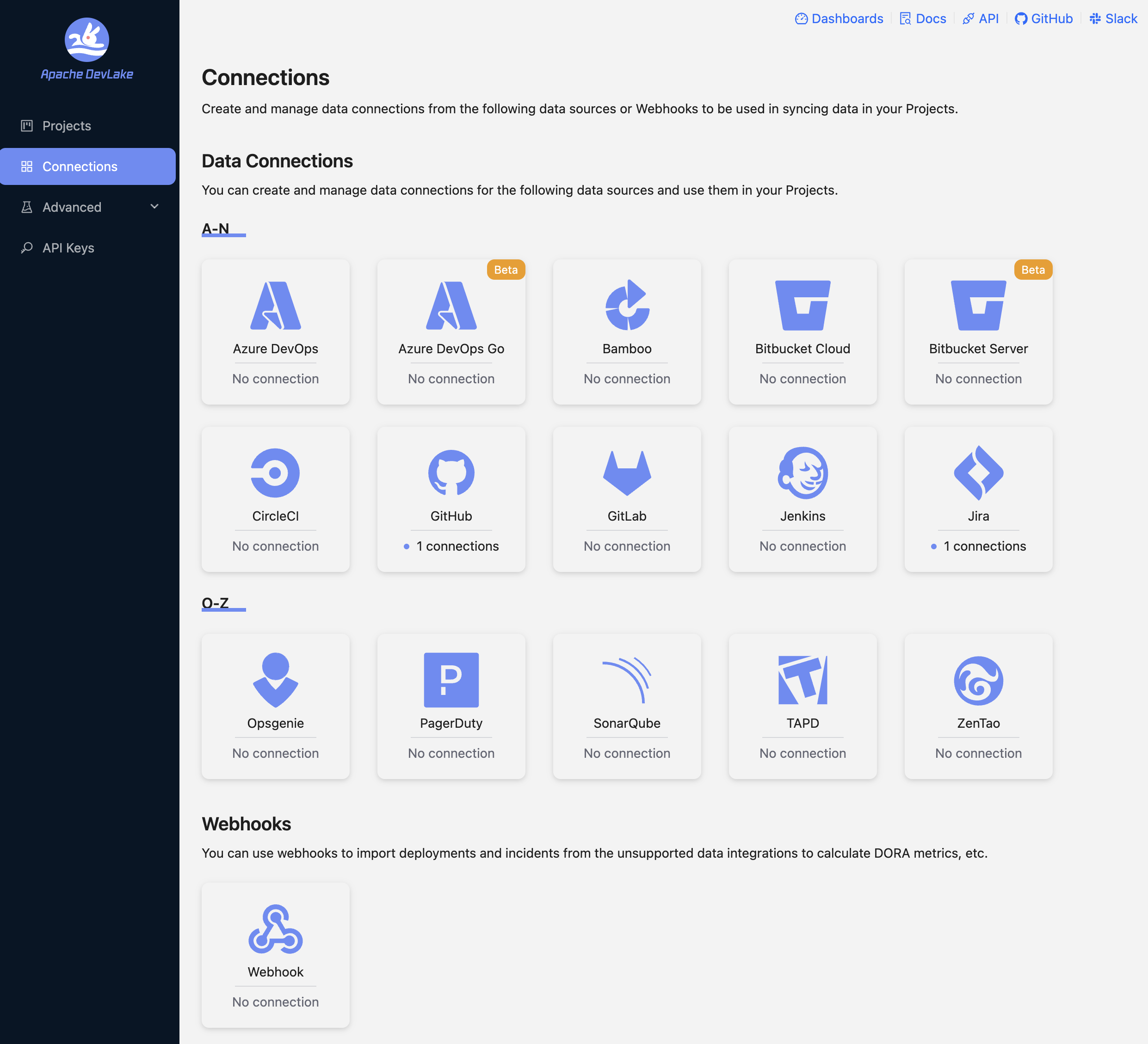
-
추가할 데이터 소스 선택 (Github)
-
인증 정보 입력
- 인증 방식으로 크게 2가지 방식을 지원하지만, 가장 안정적이고 DevLake에서 권장하는 PAT 방식 선택
- 단, PAT 1개당 5,000건/h 요청 제한이 있으므로, 데이터가 많은 경우 여러 개의 토큰을 계정별로 발급받아 사용하는 것을 권장
-
Test Connection 후, 저장
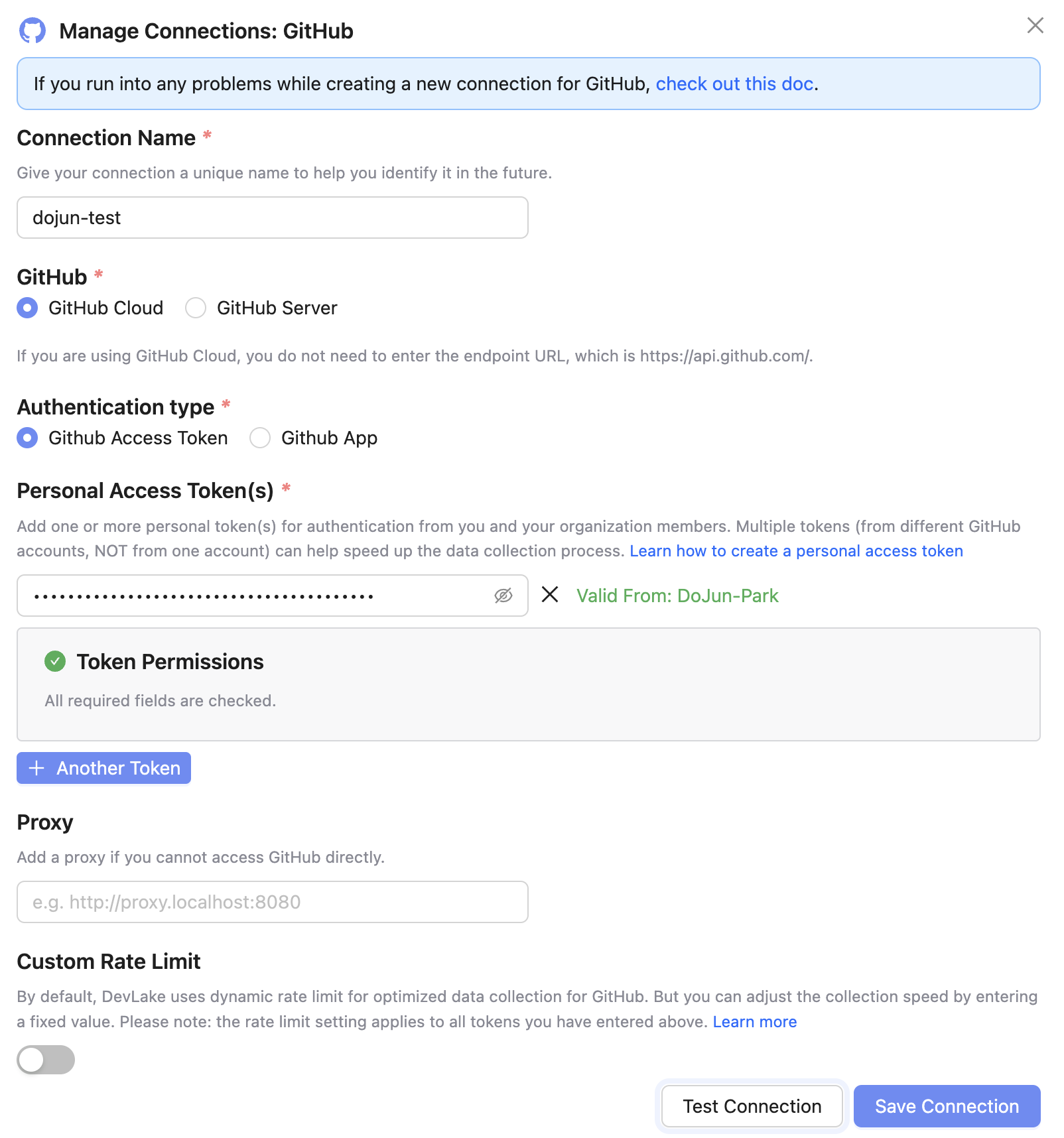
2️⃣ Data Scope 연결
GitHub과 같은 데이터 소스를 연결한 후에는, 수집할 데이터의 범위를 지정해야 합니다.
예를 들어, 특정 조직 내 레포지토리들만 선택하거나 서비스별로 필요한 저장소만 골라서 Scope로 설정할 수 있습니다.
설정한 스코프는 이후 Project 생성 시 연결할 수 있는 단위로 활용됩니다.
Connections → Github → Details →
Add Data Scope
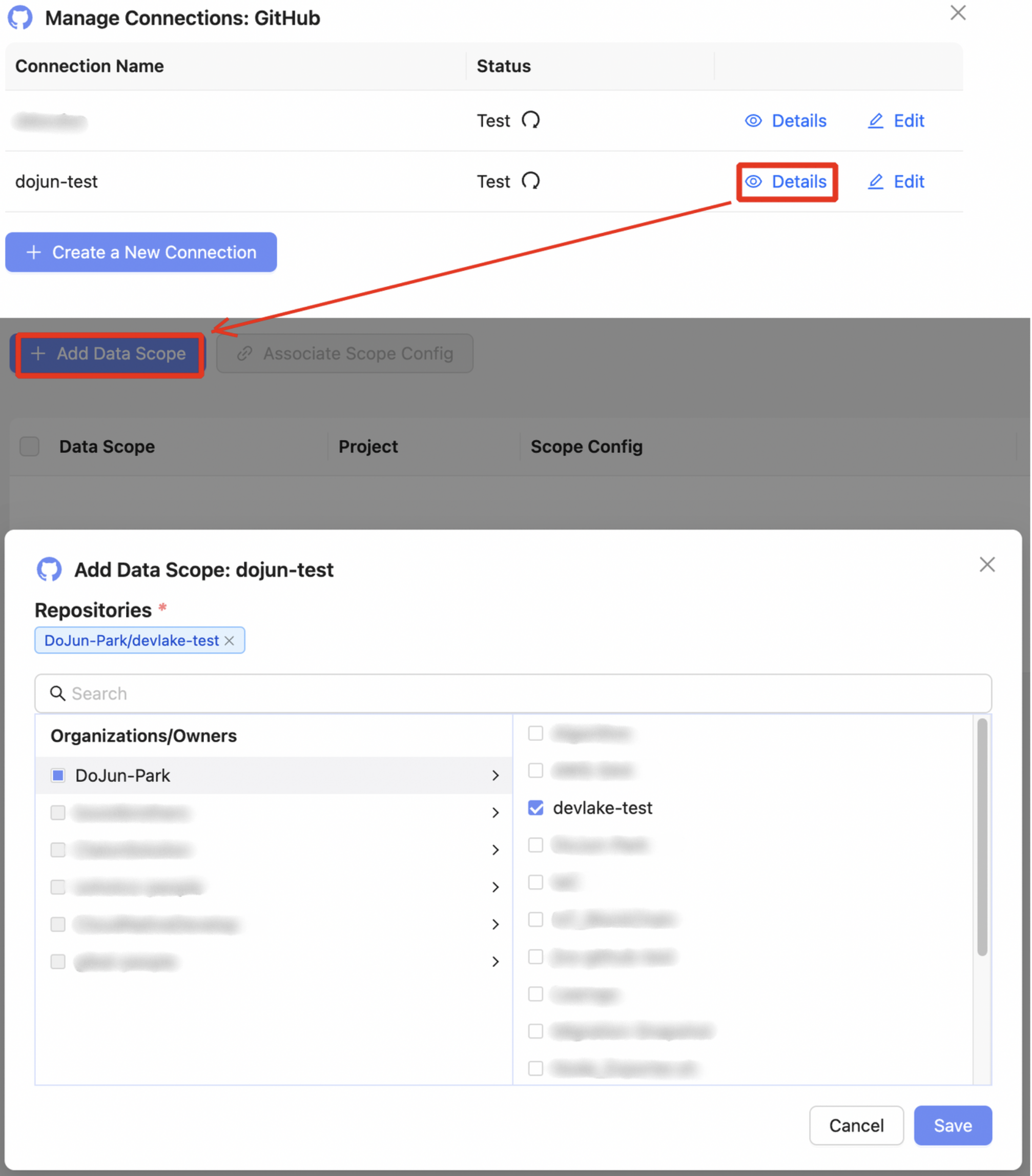
3️⃣ Scope Config 설정 (선택)
Data Scope을 설정한 후에는, 해당 Scope 내 데이터를 어떻게 해석하고 분류할지 결정하는 Scope Config를 추가로 설정할 수 있습니다.
Connections → Github → Details → (Data Scope 선택) →
Associate Scope Config→Add New Scope Config
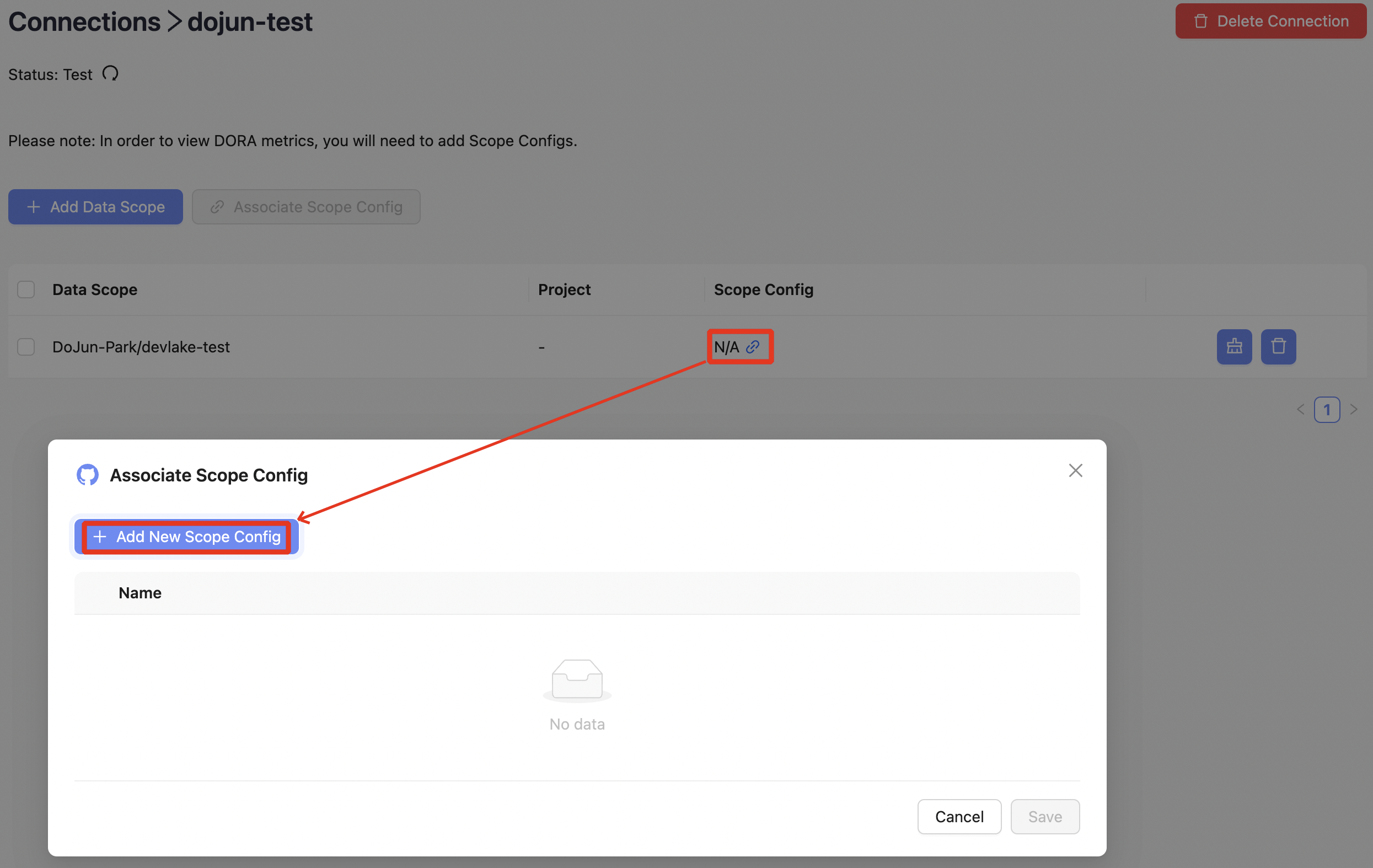
Scope Config는 크게 두 가지로 구성됩니다.
-
엔티티 설정
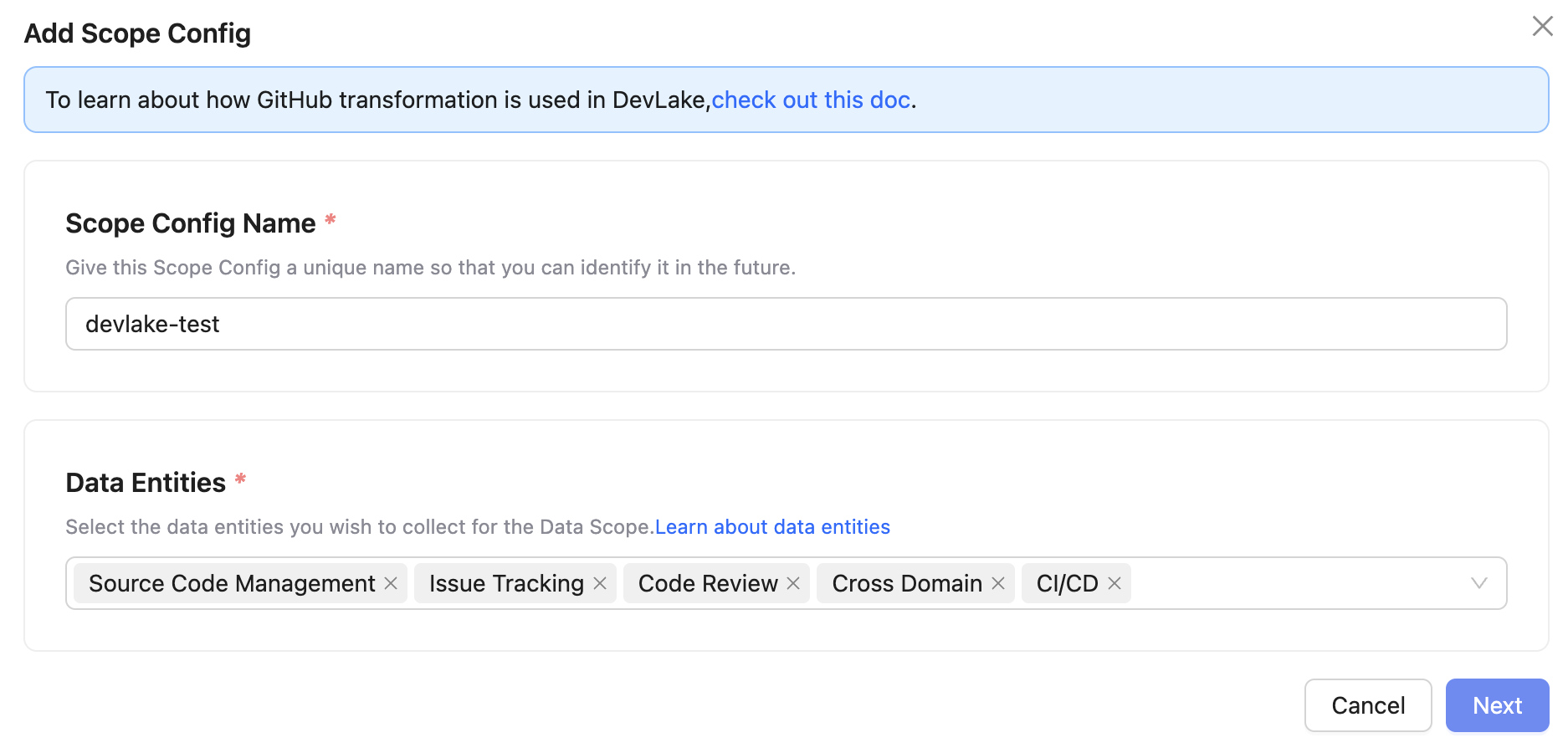
어떤 데이터를 수집할지 항목별로 선택할 수 있습니다.
기본값은 대부분의 항목이 활성화되어 있지만, 원하지 않는 항목은 체크 해제하여 수집 속도를 개선할 수 있습니다.
-
변환 규칙 설정
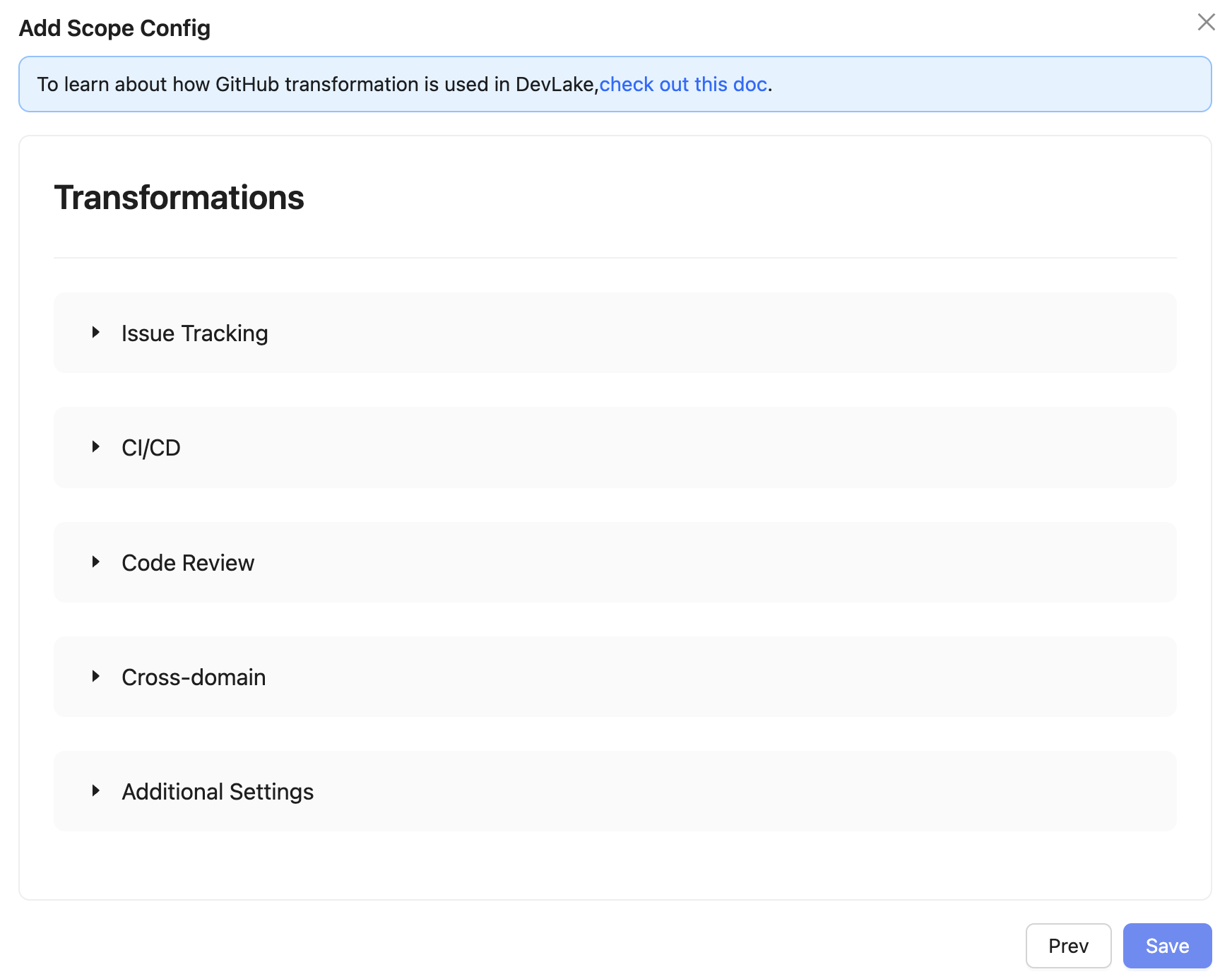
DevLake는 수집한 원시 데이��터를 단순히 보여주는 것이 아니라, 실제 의미에 맞게 변환하여 지표로 가공할 수 있도록 사용자가 직접 변환 규칙(Transformations)을 설정할 수 있습니다.
예) Bug 레이블이 붙은 이슈를 "결함", incident가 포함된 항목은 "장애"로 인식하도록 설정
총 다섯 가지의 변환 항목이 있고, 내부적으로는 다음과 같은 기준으로 Transformations를 설정했습니다.
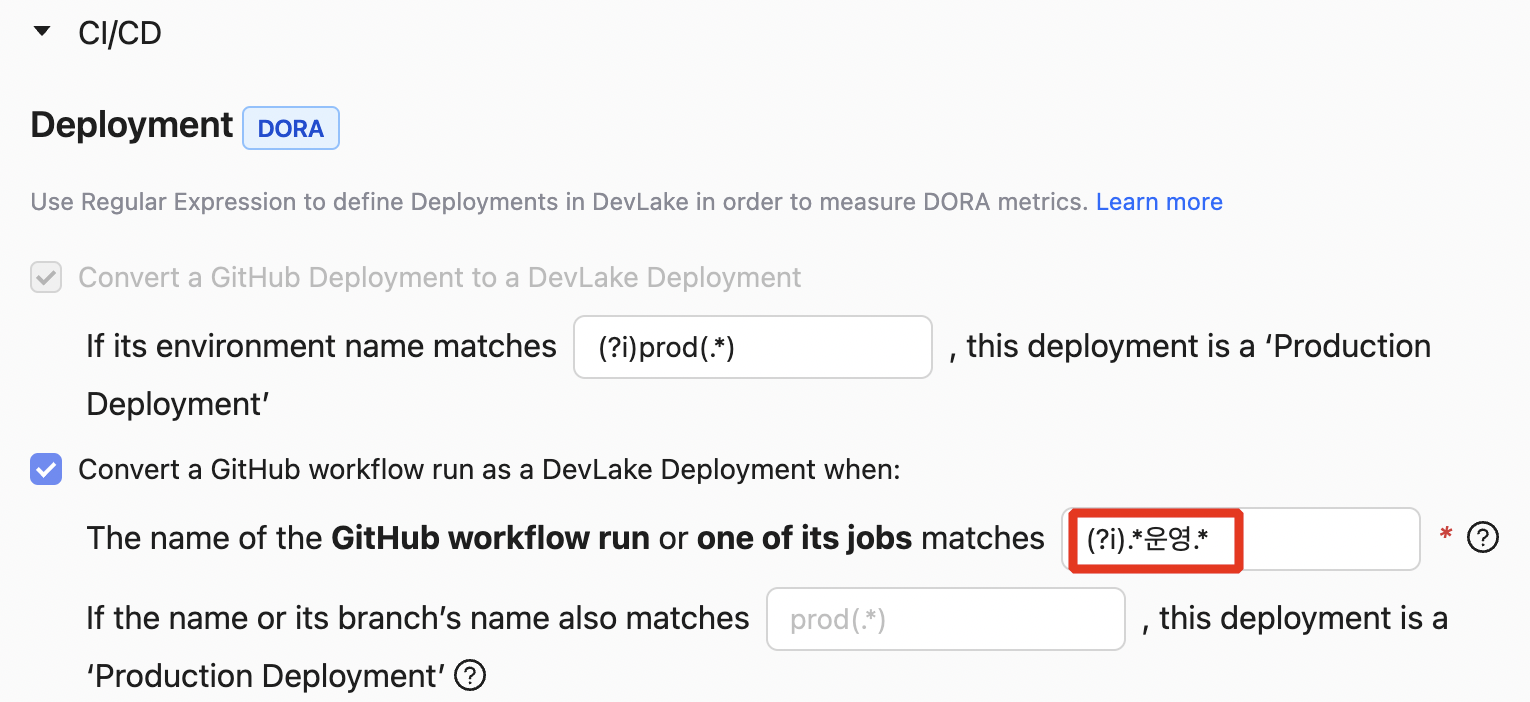
[ CI/CD - 배포 기준 설정 (GitHub Actions 기반) ]
DevLake는 GitHub 환경에서 다음 2가지 기준을 바탕으로 프로덕션 배포 여부를 판단합니다.
- Workflow 이름 또는 job 이름
- 브랜치명
이 중 하나 또는 두가지 모두에 대해 정규표현식을 설정하여, DevLake가 해당 실행이 실제 배포에 해당하는지 판단할 수 있도록 구성합니다.
사내 환경에서는 Workflow 이름 또는 job 이름에 “운영”이 포함된 경우를 프로덕션 배포로 간주하였고, 아래와 같은 정규식을 사용했습니다.
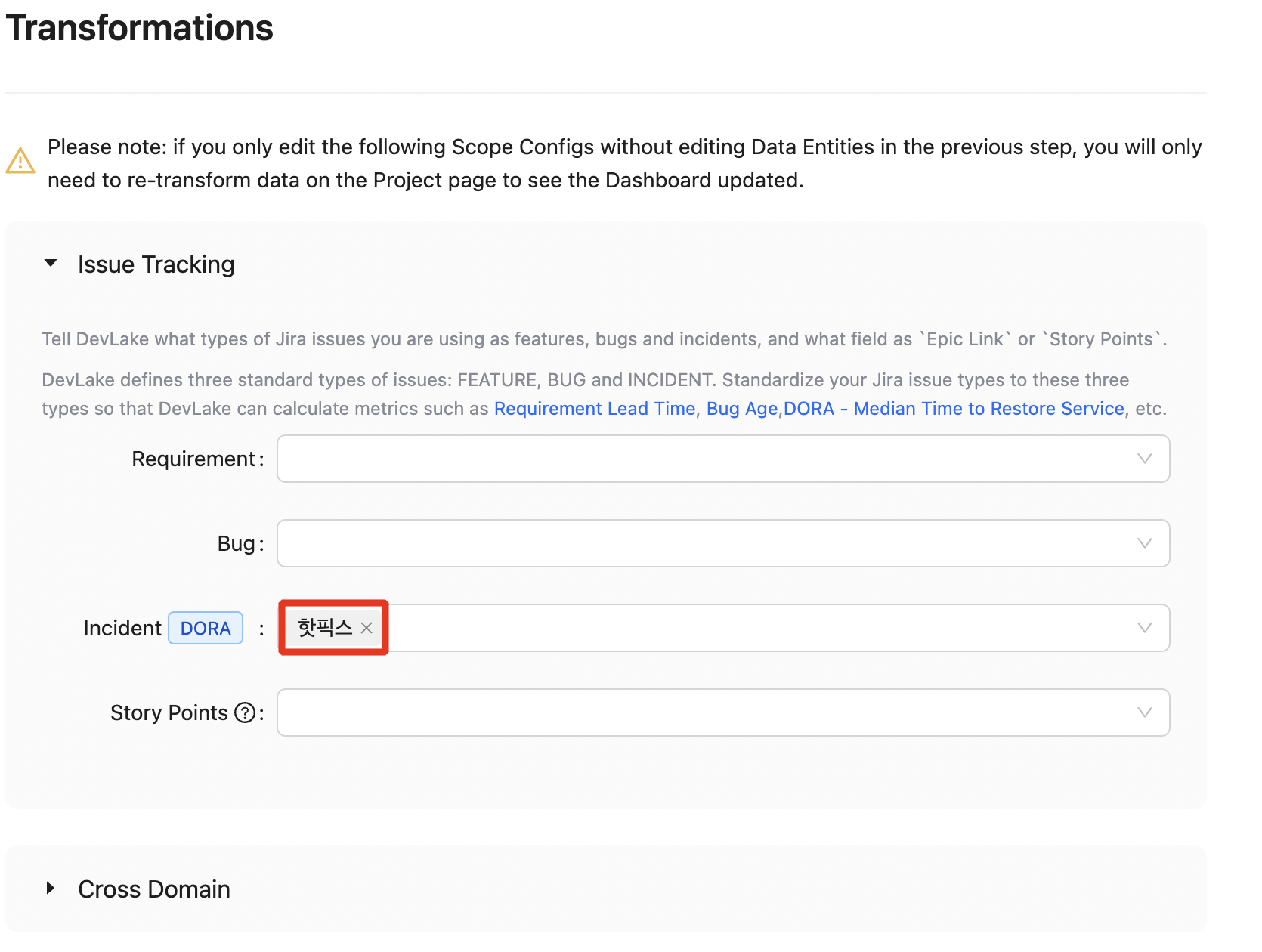
[ Issue Tracking - Incident 기준 설정 (Jira 기반) ]
사내에서는 Jira를 통해 이슈를 관리하고 있으며, DevLake에서는 DORA Metrics의 평균 복구 시간과 변경 실패율을 측정하기 위해 Incident 이슈를 정확하게 분류해야 했습니다.
때문에 DevLake에서 정의한 Incident와 내부적으로 장애 대응 목적을 위해 사용하는 이슈 유형(’핫픽스’)을 다음과 같이 매칭해줬습니다.
4️⃣ 프로젝트 생성 및 연결
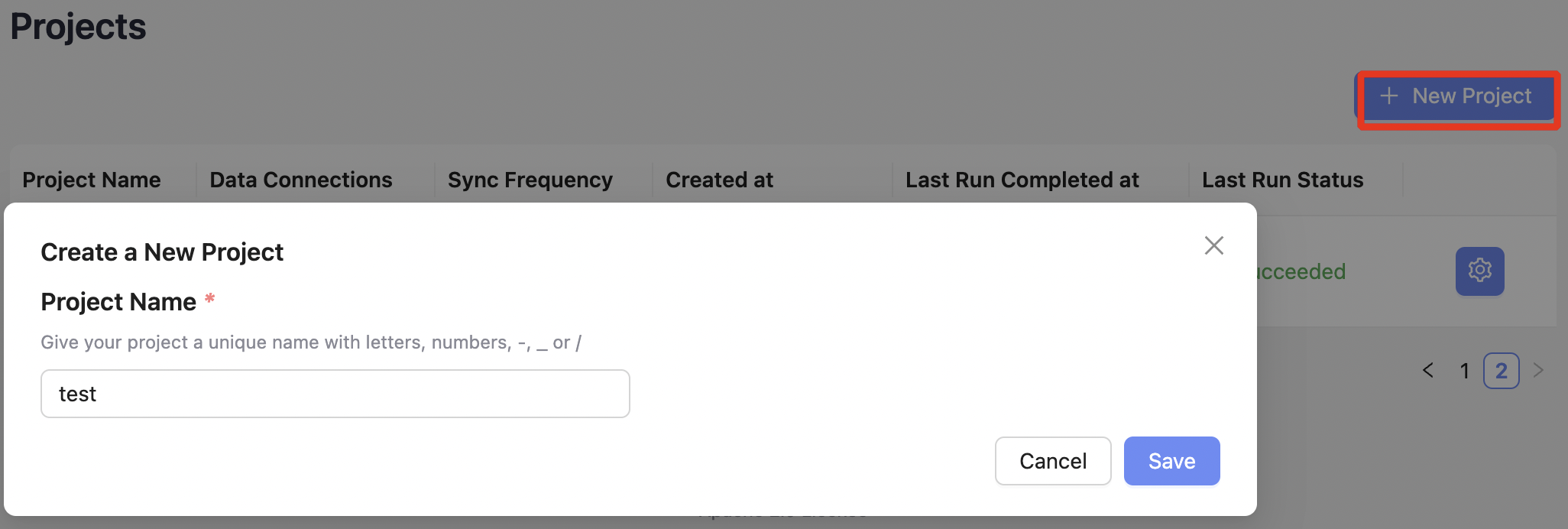
DevLake의 모든 지표는 Project 단위로 수집 및 평가되므로, 팀이나 서비스 단위로 구성하는 것이 일반적입니다.
- 프로젝트 생성
Projects →
New Project
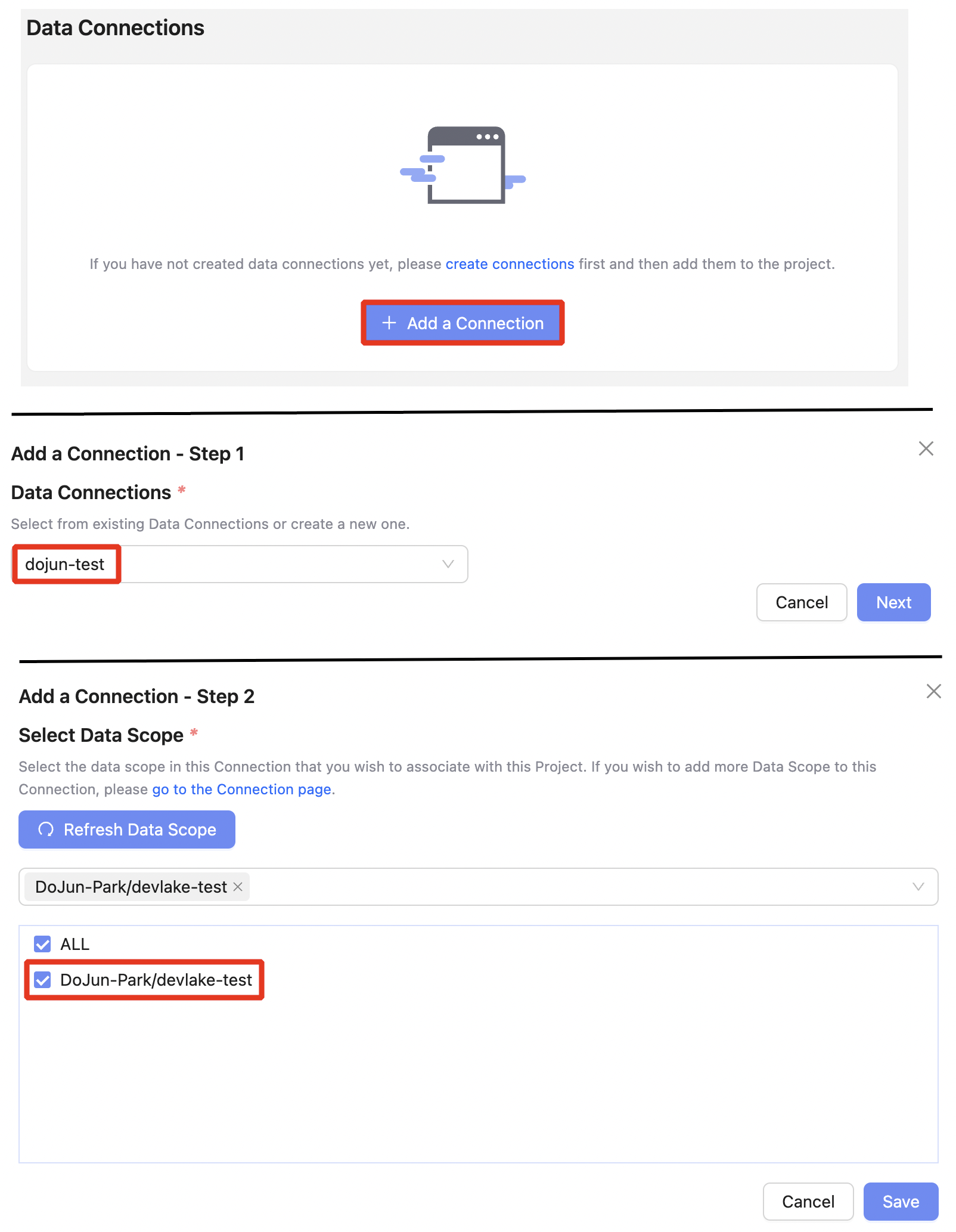
- Scope 연결
프로젝트 생성 후에는, 앞서 구성한 Data Connection과 Scope를 선택하여 프로젝트에 연결합니다.
Projects → (Projects 선택) →
Add a Connection
5️⃣ 데이터 수집 주기 설정
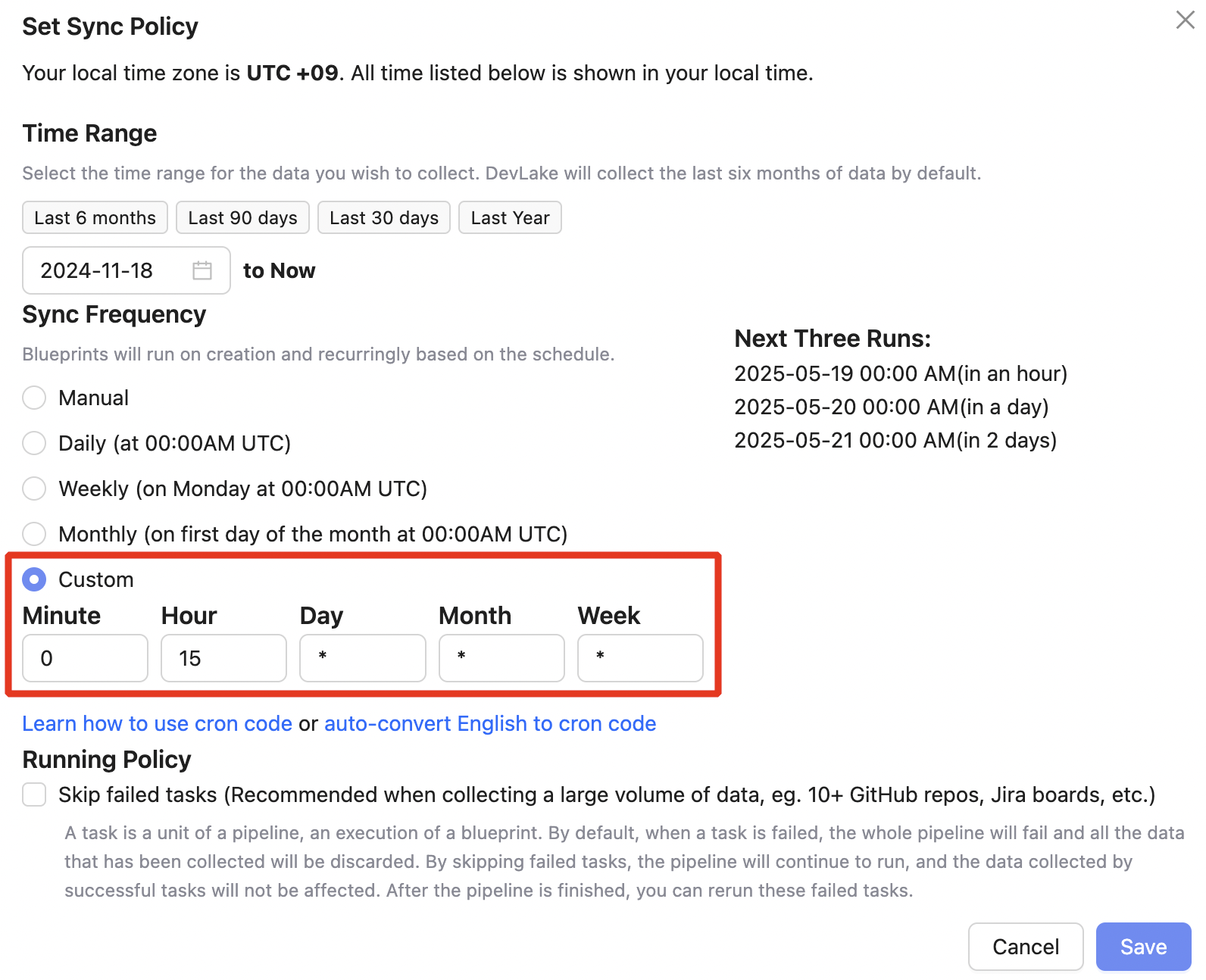
수집 대상이 정해졌다면, 데이터를 언제 어떻게 수집할지 설정합니다.
기본 설정은 프로젝트 생성 시점 기준으로 이전 6개월 데이터부터 현재까지 수집하도록 설정되어 있으며, 사용자 상황에 맞게 기간과 주기를 조정할 수 있습니다.
Projects → (Projects 선택) → Sync Policy
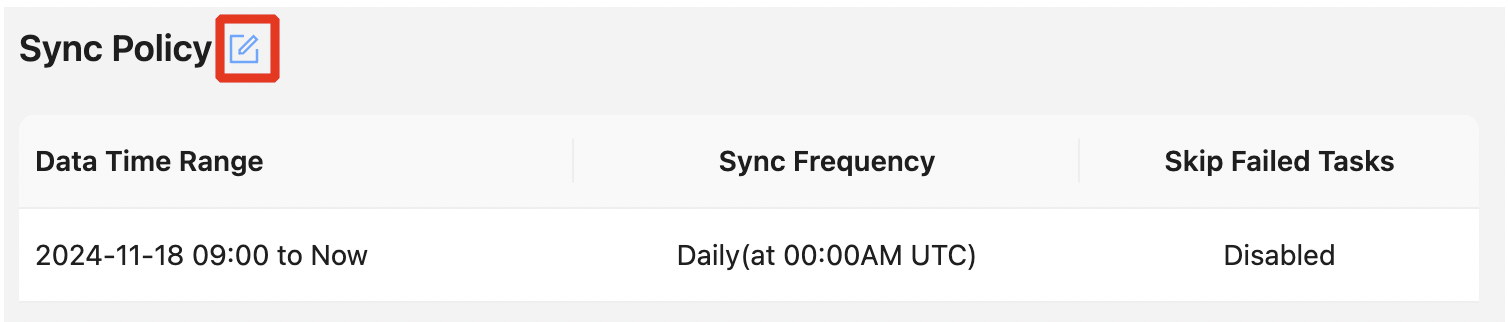
수집 시간은 내부적으로 API Rate Limit(기본 5,000 req/h)을 바탕으로 다른 서비스에 영향을 주지 않기 위해, 업무 외 시간에 안정적으로 수집하도록 다음과 같이 매일 자정에 수집되도록 설정했습니다.
6️⃣ 데이터 수집 실행
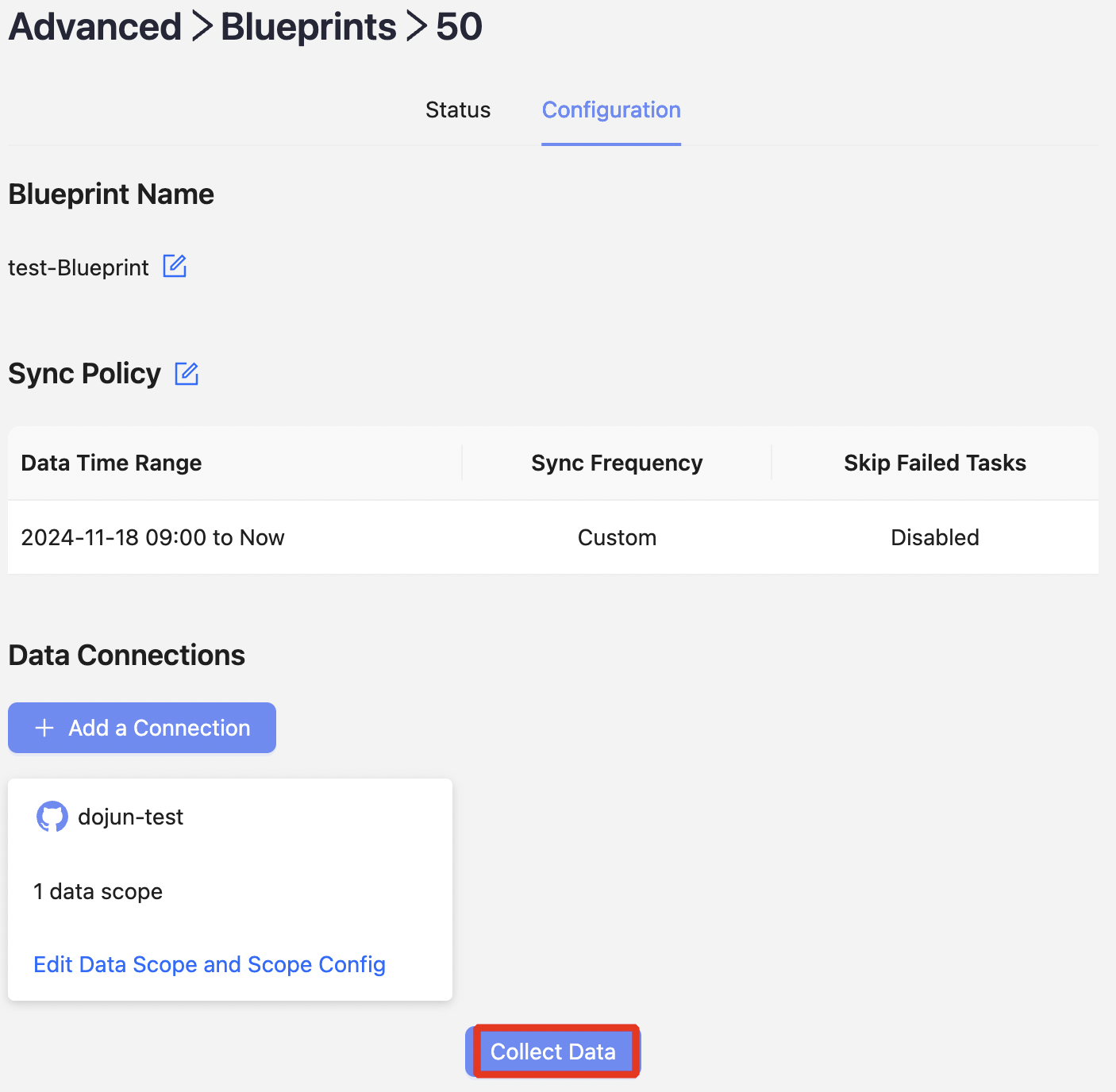
모든 설정이 완료되면, Blueprint를 실행하여 데이터를 수집할 수 있습니다.
데이터가 정상적으로 수집되면 Grafana 대시보드에서 시각화된 지표를 확인할 수 있습니다.
Advanced → Blueprints → (Blueprint 선택) → Collect Data
7️⃣ 시각화 및 대시보드 구성
DevLake는 Grafana와의 연동을 지원하며, MySQL에 저장된 데이터를 기반으로 시각화할 수 있는 Grafana 대시보드 템플릿을 공식적으로 제공합니다. (DevLake Grafana Dashboard 링크)
다만 해당 대시보드는 기본 설치 시 자동으로 구성되는 않으며, DevLake Github 저장소에서 직접 JSON 템플릿을 복사하거나 다운받아 Grafana에 import하여 사용해야 합니다.
-
Grafana Datasource에 DevLake MySQL 추가
-
DevLake 공식 저장소에서 대시보드 템플릿(JSON) 복사
-
Grafana에서 Dashboards → New → Import → (복사한 템플릿 붙여넣기)
-
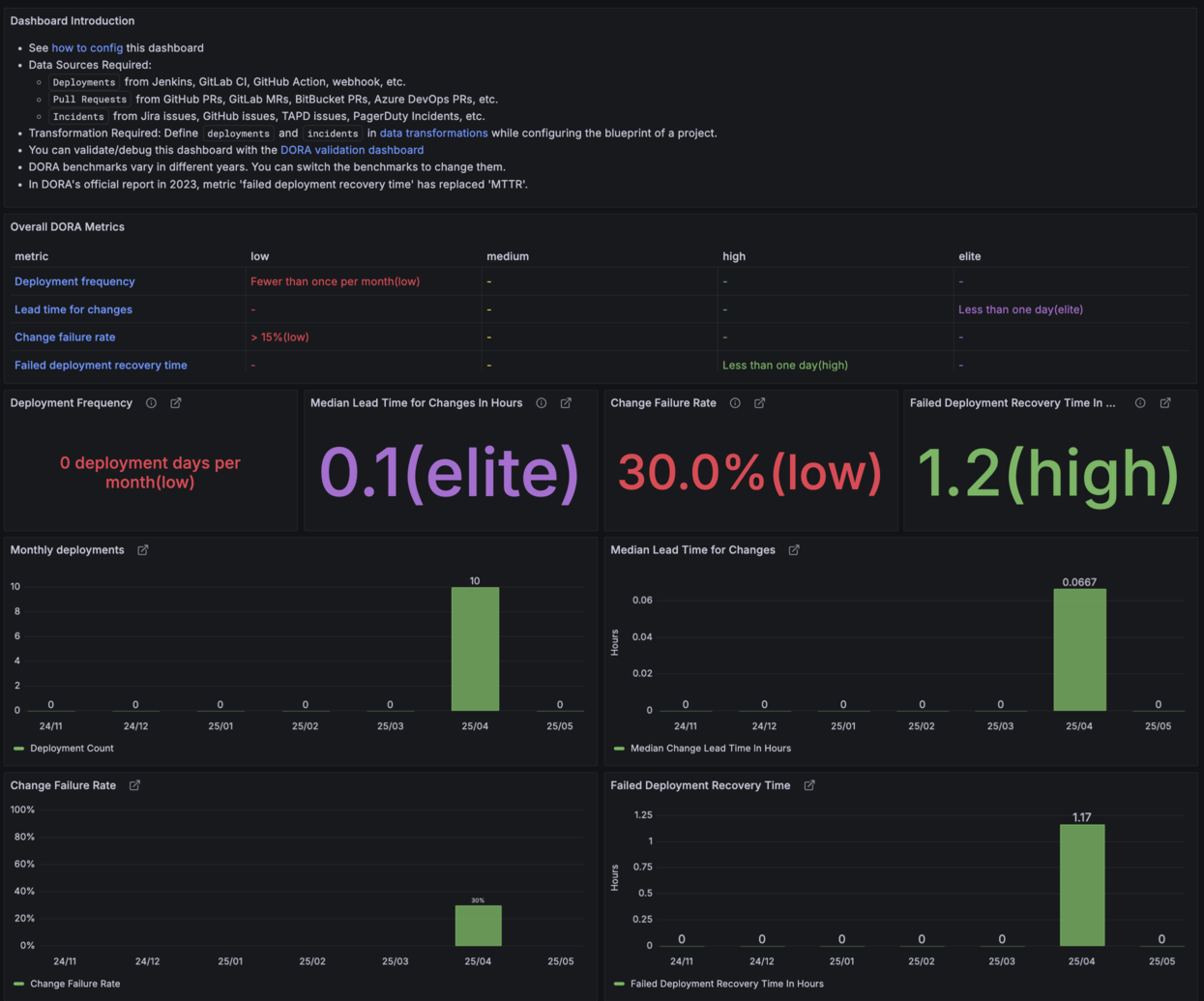
대시보드 확인 (예시 데이터 기반)
마주한 이슈와 해결 방법
Jira Incident를 서비스 단위로 필터링하기
[문제 상황]
DevLake에서는 수집된 데이터를 ‘프로젝트(Project)’ 단위로 구분합니다.
이때 DevLake 공식 문서에서는 DORA 지표의 정확한 해석을 위해 프로젝트를 팀 단위가 아닌, 실제 개발·배포되는 서비스 또는 시스템 단위로 구성할 것을 권장하고 있습니다
이에 따라 저희 조직도 팀 내 서비스 단위로 프로젝트를 구성하기로 결정했습니다.
하지만 서비스별로 프로젝트를 구성하는데 문제가 있었습니다.
우선 저희 조직의 서비스 운영 구조와 DevLake 프로젝트 구성 방식에 대해 간략히 설명드리겠습니다.
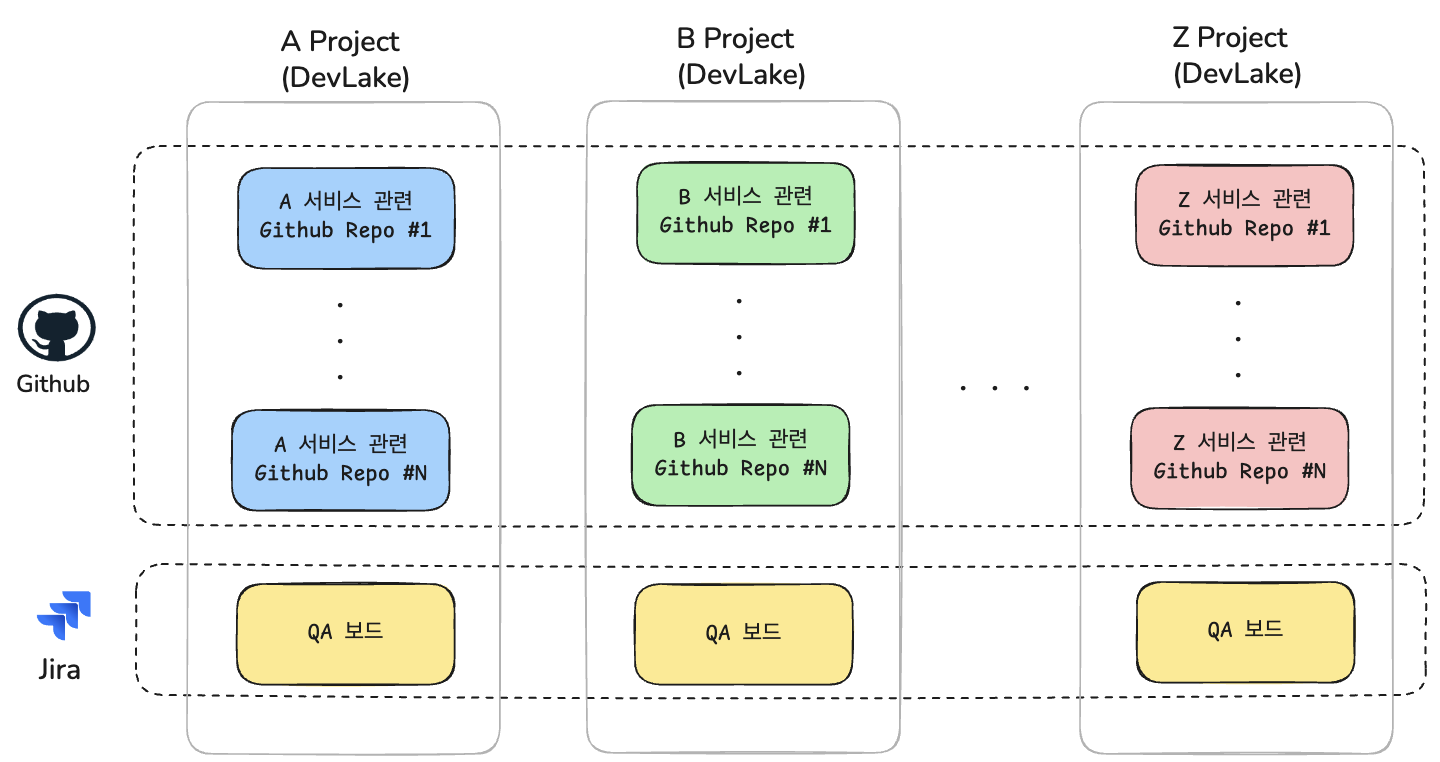 (보안상 팀내에서 관리하는 서비스는 A, B와 같이 지칭했습니다.)
(보안상 팀내에서 관리하는 서비스는 A, B와 같이 지칭했습니다.)
- 팀 내에서 여러 개의 서비스를 운영
- 하나의 Jira 보드(QA 보드)에서 모든 서비스의 Incident 이슈 통합 관리
- 서비스별 Incident 이슈는 Jira 커스텀 필드를 통해 구분 (Issue_Category)
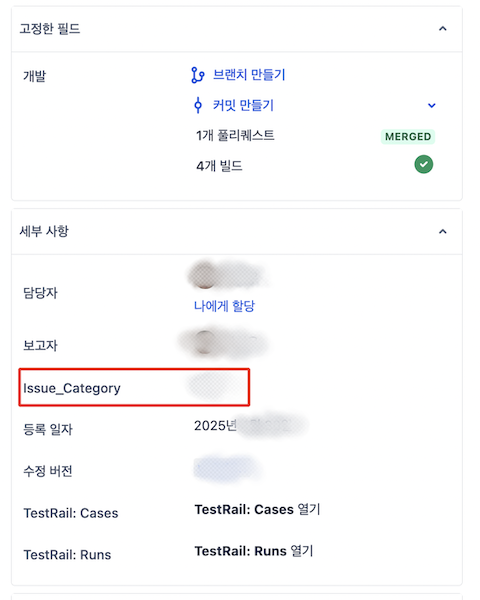
이러한 내부 구조에서 프로젝트별 Incident를 정확하게 집계하기 위해선, 각 이슈에 포함된 커스텀 필드값을 기준으로 필터링하는 것이 필요했습니다.
하지만 DevLake의 기본 스키마(Domain Layer)에는 해당 커스텀 필드가 포함되어 있지 않아, 서비스 단위로 Incident를 필터링하는데 한계가 있었습니다.
[해결 방법]
아래와 같은 순서로 작업을 진행했습니다.
1. Raw Layer에서 커스텀 필드 수집 여부 확인앞서 [데이터 처리 구조]에서 설명한 것처럼, DevLake는 3단계 계층을 거쳐 데이터를 수집합니다. 그리고 지표 계산은 기본적으로 Domain Layer에 저장된 데이터를 기준으로 이루어집니다.
이 중 Domain Layer는 DevLake의 표준 스키마에 따라 정제된 데이터만 포함되기 때문에, 커스텀 필드와 같이 표준에 포함되지 않은 데이터는 확인이 어렵습니다.
때문에 필요한 커스텀 필드가 실제로 수집되었는지 확인하기 위해, 가장 원본에 가까운 계층인 Raw Layer에서 해당 필드의 존재 여부를 먼저 확인했습니다.
- 확인 대상 필드 :
Issue_Category
Raw Layer 테이블인 _raw_jira_api_issues의 data 컬럼을 조회합니다.
SELECT CONVERT(data USING utf8mb4) AS json_data
FROM _raw_jira_api_issues
WHERE id = <이슈 id>;
해당 데이터를 확인해보면, 커스텀으로 생성한 필드의 경우 실제 필드명(Issue_Category)이 아닌
아래와 같이 customfield_*** 형태로 수집되는 것을 확인할 수 있습니다.
{
"fields": {
"customfield_10823": {
"self": "https://<domain>.atlassian.net/rest/api/2/customFieldOption/10217",
"value": "접수",
"id": "10217"
}
}
}
2. Customize 기능을 활용한 데이터 추출
위 과정에서 확인한 커스텀 필드(customfield_10823)를 실제 지표 계산에 활용하려면, 해당 필드를 Domain Layer로 추출할 수 있어야 합니다.
이를 위해 DevLake에서 제공하는 Customize 기능을 사용했습니다.
Customize는 Raw Layer에서 특정 데이터를 추출하여 Domain Layer 테이블에 사용자가 정의한 컬럼(x_ prefix)으로 저장할 수 있도록 지원합니다. (자세한 기능 설명)
저희 팀에서는 다음과 같은 방식으로 Customize를 활용하여 데이터를 수집하고 가공했습니다.
-
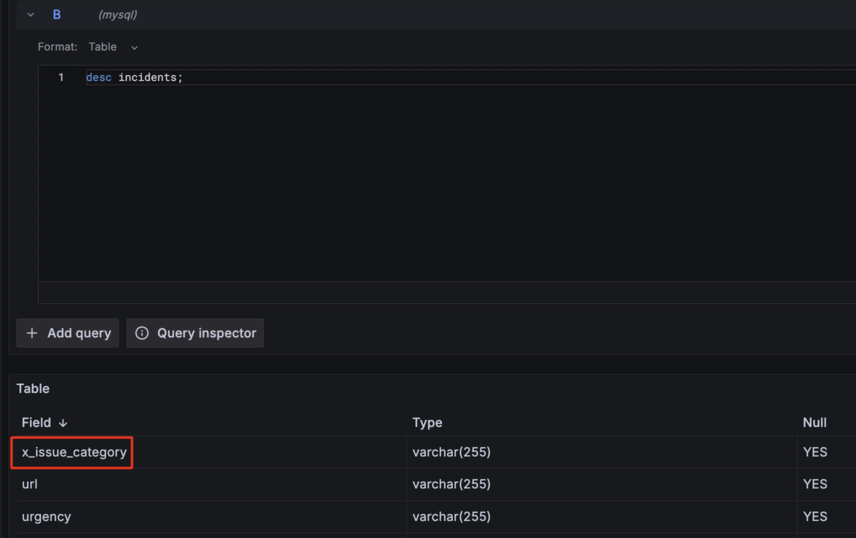
Domain Layer에 컬럼 추가
Raw Layer에 존재하는 필드를 Domain Layer로 옮기기 전에, 사용자 정의 컬럼을 Domain Layer 테이블에 추가합니다.
컬럼 추가는 DevLake API 서버에 요청하여 진행했습니다.
# DevLake API 접속
$ kubectl exec -it <devlake 파드> -n <devlake 네임스페이스> -- /bin/sh
# 필드 추가
# incidents 필드에 x_issue_category 컬럼 추가
curl -X POST <devlake svc>.<devlake 네임스페이스>.svc:8080/plugins/customize/incidents/fields \
-H "Content-Type: application/json" \
-d '{
"columnName": "x_issue_category",
"displayName": "Issue Category",
"dataType": "varchar(255)",
"description": "Jira customfield(issue category)"
}'
-
Customize Plugin 사용하여 데이터 추출
추가한 컬럼에 데이터를 매핑하기 위해 Blueprint에 Customize Plugin을 설정합니다.
Advanced → Blueprints → (New Blueprint)
Blueprint는 Advanced Mode로 설정합니다.
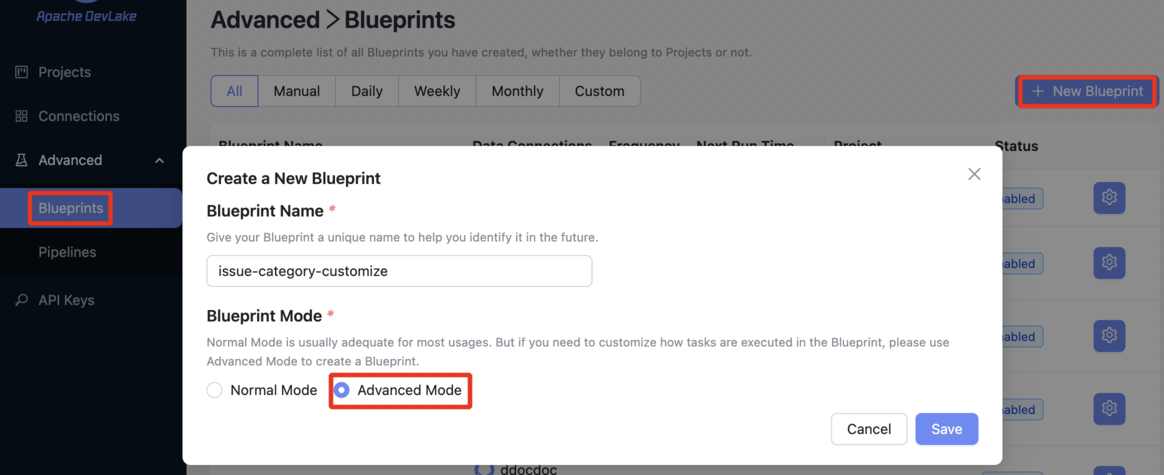
Blueprint 생성 이후, Raw Layer의 필드 → Domain Layer의 커스텀 컬럼으로 매핑하기 위한 정보를 JSON Task Editor에 다음과 같이 작성합니다.
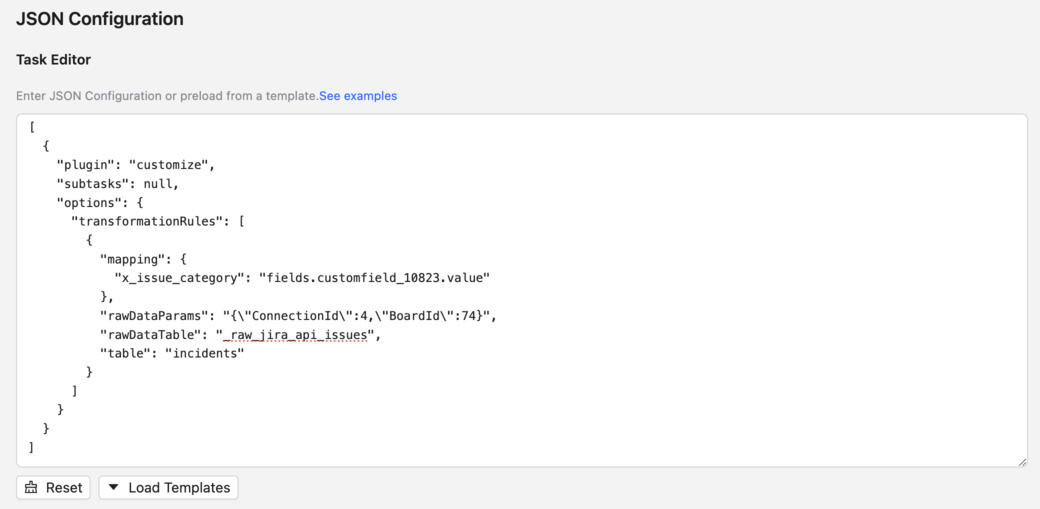
[
{
"plugin": "customize",
"subtasks": null,
"options": {
"transformationRules": [
{
"mapping": {
"x_issue_category": "fields.customfield_10823.value"
},
"rawDataParams": "{\"ConnectionId\":4,\"BoardId\":74}",
"rawDataTable": "_raw_jira_api_issues",
"table": "incidents"
}
]
}
}
]
구성이 완료되면 Blueprints를 실행하여, Customize로 추가한 필드가 Domain Layer 테이블(incidents)에 정상적으로 매핑되었는지 확인합니다.
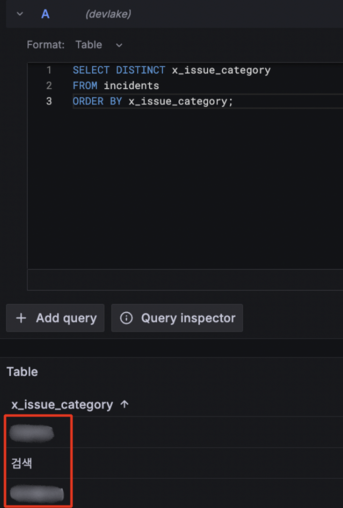
위 과정을 통해 서비스별로 발생한 Incident 이슈에 대한 식별이 가능해졌고, 이를 기반으로 DORA 지표를 프로젝트 단위로 분석할 수 있게 되었습니다.
운영 기준에 맞춘 DevLake 기본 쿼리 갈아엎기
[문제 상황]
DevLake 기본 대시보드에서 제공하는 일부 DORA Metrics 쿼리는 내부 운영 기준 데이터와 일치하지 않거나 지표 해석의 관점 차이��로 쿼리 수정이 필요했습니다.
Change Failure Rate: 기존 쿼리는 배포와 Incident 간 매핑이 부정확함Failed Deployment Recovery Time: ‘복구 시점’에 대한 재정의 필요
이에 따라, 내부 운영 기준에 맞춰 쿼리 재구성했습니다.
[지표별 쿼리 수정 사항]
-
Change Failure Rate
🧭 배경
기존 쿼리는
project_incident_deployment_relationships테이블을 기준으로 배포와 Incident를 1:1로 매핑하여 지표를 계산합니다.하지만 실제 운영 데이터와 비교했을 때, 배포와 Incident가 정확하게 매핑되지 않아 지표값이 부정확했습니다.
🛠 개선 방향
기존 ‘배포 후 장애 발생 여부’ 대신 ‘서비스별 장애 발생 건수’를 기준으로 지표 계산 방식을 변경했습니다.
이렇게 변경이 가능했던 이유는, Incident 이슈는 실제 장애 상황에서 단일 건으로 생성되어 관리되기 때문에, 굳이 배포와 직접 매핑하지 않고 발생 건수만으로도 의미 있는 비율 산정이 가능하다고 판단했기 때문입니다.
👨💻 수정된 쿼리 예시
_incidents AS (
SELECT
i.id AS incident_id
FROM
incidents i
WHERE
i.x_issue_category IN (${issue_category})
AND i.component = '${component}'
AND $__timeFilter(i.created_date)
),
_incident_count AS (
SELECT COUNT(*) AS incident_count
FROM _incidents
)위 쿼리는 서비스별 발생한 장애 건수를 계산합니다
해당 결과를 기반으로 전체 배포 대비 장애 발생 비율을 산정하여 해당 지표를 계산합니다.
-
Failed Deployment Recovery Time
🧭 배경
기존 쿼리는 배포 완료 시점(GitHub Action 배포)부터 이슈 종료 시점까지의 걸린 시간을 기준으로 지표를 계산합니다.
하지만 실제 운영 환경에서는 아래와 같은 이유로, 해당 기준이 복구 시간 지표를 판단하는데 부적절하다고 생각했습니다.
⚠️ GitHub Action 배포 시점은 실제 배포 완료 시점이 아니다.
- 사내 배포 환경에서는 Github Action을 통한 이미지 빌드 후, ArgoCD를 통해 최종 배포하기 때문에 실제 배포 완료 시점과 시간 차이가 존재합니다.
⚠️ 배포 시점을 복구 시작 시점으로 삼기 어렵다.
- 배포 이후 서비스는 정상적으로 운영되는 것처럼 보이다가, 특정 사용자 시나리오나 특정 API 호출, 또는 시간 지연 조건 등 특정 조건에서만 문제가 발생하는 경우가 존재합니다.
- 이처럼 배포 직후에는 문제가 드러나지 않다가 일정 시간이 지난 후에야 이슈가 발생하는 상황에서는, 단순히 배포 완료 시점을 복구 시작 시점으로 삼는 것은 실제 문제 발생 시점과 괴리가 생겨 ��지표의 정확성이 떨어진다고 판단했습니다.
🛠 개선 방향
복구 시간을 "문제 인식 시점부터 대응 완료까지 걸린 시간"으로 재정의했습니다.
이때 문제 인식 시점은 Incident 이슈가 등록된 시점으로 보았습니다.
왜냐하면 해당 시점부터 조직 내에서 문제가 공식적으로 인지되고 대응이 시작되므로, 실질적인 복구 프로세스의 시작점은 배포 시점이 아닌 문제 인식 시점이라고 판단했기 때문입니다.
기존 기준과 변경된 기준의 차이를 시각적으로 정리하면 다음과 같습니다.
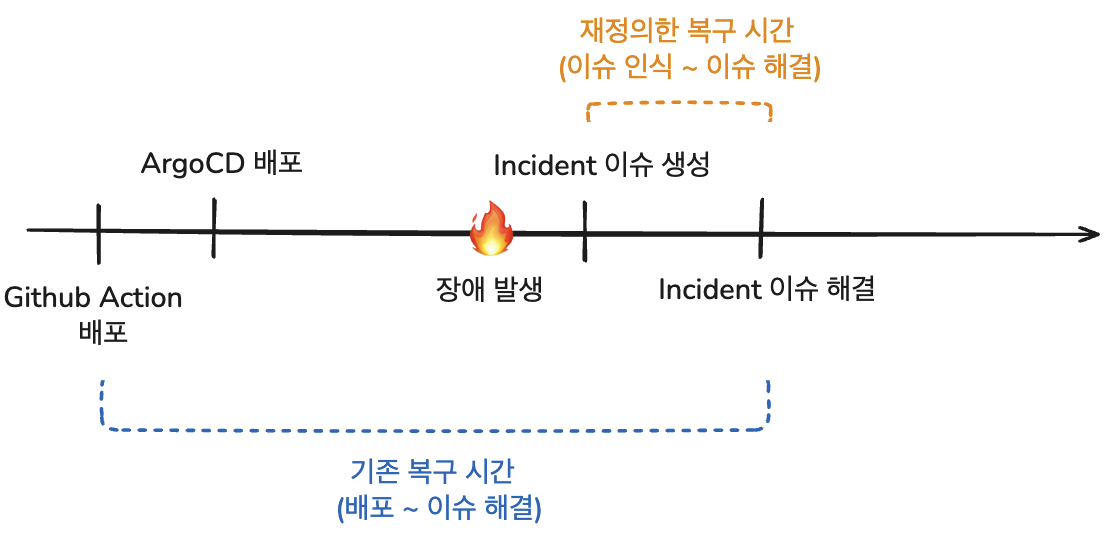
위와 같이 복구 시간을 재정의하여, 내부 환경에 맞게 지표의 현실성과 정밀도를 높였습니다.
👨💻 수정된 쿼리 예시
SELECT
DATE_FORMAT(i.created_date, '%y/%m') AS month,
COALESCE(
CAST(i.lead_time_minutes AS SIGNED),
TIMESTAMPDIFF(MINUTE, i.created_date, i.updated_date)
) AS recovery_time_minutes
FROM
incidents i
WHERE
i.component = '${component}'
AND i.x_issue_category IN (${issue_category})
AND $__timeFilter(i.created_date)위 쿼리는 서비스별 Incident 이슈를 기준으로, 문제 인식 시점(이슈 생성 시점)부터 복구 완료 시점(이슈 종료/업데이트 시점)까지의 시간을 계산합니다.
다만, 내부 Jira 이슈 워크플로우의 구조상 일부는
lead_time_minutes값이 수집되지 않아, 이 경우 이슈 상태가 마지막으로 업데이트된 시간을 기준으로 복구 완료 시간을 보완 계산하도록 처리했습니다.
마무리
AI의 급속한 발전과 확산으로, 그 어느 때보다 빠르게 변화하는 개발 환경에 놓여 있습니다.
이러한 환경에서, 개발팀의 활동과 결과를 정략적으로 지표화하고, 이를 기반으로 지속적인 개선과 운영 안정성 확보가 무엇보다 중요하다고 생각합니다.
이 글이 DevLake 도입이나 지표 환경 구성에 대해 고민하고 계신 분들께 조금이나마 도움이 되었기를 바랍니다.