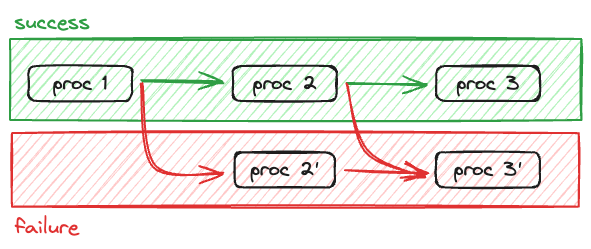
ROP Pattern

안녕하세요. 비브로스 백엔드 개발자 고윤호입니다.
이번에는 이름은 낯설지만 막상 들어보면 친숙한 개념인 ROP Pattern을 소개하고 어떻게 사용하며 어떤 장단점이 있는지 함께 얘기해보고자 합니다.
ROP?
Railways Oriented Programming
쉽게 설명하자면 성공과 실패라는 두 갈래의 분기 흐름을 가지는 프로그래밍 방식입니다. 코틀린이나 Rust 같은 현대적인 언어를 접해보신 분들이라면 Result class에 대해서 알고 계신 분들이 있을 겁니다. Javascript에서 흔히 사용되는 Promise<Ok>는 성공 타입 밖에 알 수 없습니다.
class Result<Error, Ok> {
/* snip */
}
많은 프로그래밍 언어에서 에러 상태가 되면 진행 중인 프로세스를 중단하고 함수 혹은 메소드를 호출한 caller에게 에러를 전달합니다. 그런데 함수를 호출한 caller에서는 어떤 에러가 발생했는지 알 수 없기 때문에 항상 unknown을 받고 unknown이 어떤 에러 타입인지에 따라 분기하려면 반드시 개발자가 해당 에러에 대해서 발생할 수 있음을 알고 있어야 합니다.
function mustThrowError() {
throw new Error('This is a Error');
}
function main() {
try {
mustThrowError();
console.log('no reached');
} catch (error) {
error // is unknown
}
}
하지만 ROP Pattern에서는 에러를 던지지 않고 에러 상태를 가지고 다음 프로세스로 진행합니다. 다만, 에러 상태를 가지고 있을 경우 다음 프로세스가 실행되지 않고 넘어갑니다.
function mustThrowError() {
return Result.failure(new Error('This is a Error'));
}
function main() {
mustThrowError(); // Result<Error, Ok>;
console.log('reached'); // reached
}
기본 지식부터 알아보자
ROP는 함수형 프로그래밍 개념에서 차용한 Functor에 기반하고 있습니다. 그럼 함수형 프로그래밍을 모르면 쓸 수 없�는 걸까요? 그렇지 않습니다. 왜냐하면 우리는 알게 모르게 함수형 프로그래밍을 이미 쓰고 있기 때문이죠.
우리가 흔히 쓰는 함수들을 통해 개념을 익혀봅시다.
Functor
"함자"라고도 부르는 Functor는 이미 우리 가까이서 사용하고 있습니다. Array, Promise, String 등 너무 많네요.
Functor는 값을 그 자체로 사용하지 않고 한꺼풀 감싼 것을 의미합니다. 근데 함자라고 부르는 것은 너무 와닿지 않으니 직관적이게 "상자"라고 부르겠습니다. 함수라는 단어에도 함(函)이라는 단어가 상자라는 뜻입니다.



왜 이런 형태가 필요할까요? 그건 값을 처리할지 말지에 대한 분기 여부에 따라 값의 처리 여부를 달리 할 수 있기 때문입니다. 이 다음 메소드들을 보면 좀 더 이해가 쉽습니다.
.map
map? 배열에서나 보던 메소드 아닌가요? 그럼 쉽게 설명하기 위해 배열을 기준으로 설명해보겠습니다.
const arr = [value];
arr.map(value => `value is ${value}`); // [`value is ${value}`]

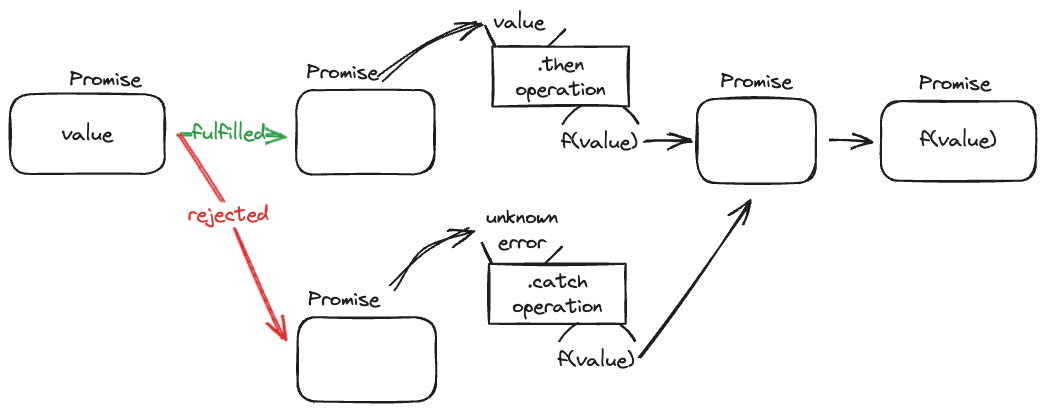
.map은 Functor로 감싸여 있는 value를 꺼내 함수를 적용하고 다시 Functor로 감싸는 함수입니다. 이것을 통해서 값이 있을 경우 적절하게 처리할 수 있죠. Promise를 예시로 다시 확인해볼까요?
const promise: Promise<string> = Promise.resolve(value as string);
promise
.then(value => `value is ${value}`)
.catch(error => `no rechead`);
.flatMap
flatMap도 Array를 다루다 보면 한번 쯤은 써보셨을 함수입니다. 배열에서 map을 사용하다가 반환값이 배열일 때 이차배열을 일차배열로 변환하면서 써보셨을 텐데요.
const arr = [value];
arr.map(value => [`value is ${value}`]); // [[`value is ${value}`]] as string[][]
arr.flatMap(value => [`value is ${value}`]); // [`value is ${value}`] as string[]
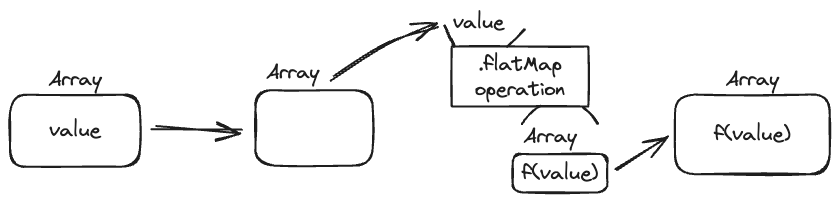
보시면 이해하시겠지만 map과 차이점은 다시 박스로 처리를 할 것인지? 박스를 그대로 사용할지 차이라고 볼 수 있습니다.
map: 값을 박스에서 꺼낸다 → 처리된 값을 받는다 → 처리된 값을 다시 박스에 넣는다.flatMap: 값을 박스에서 꺼낸다 → 처리된 값이 든 박스를 받는다 → 박스를 그대로 쓴다.
그럼 Promise도 한번 살펴볼까요?
const promise = Promise.resolve(value);
promise
.then((value): string => `value is ${value}`) // Promise<string>
promise
.then((value): Promise<string> => Promise.resolve(`value is ${value}`)) // Promise<Promise<string>>
.catch(error => `no rechead`);
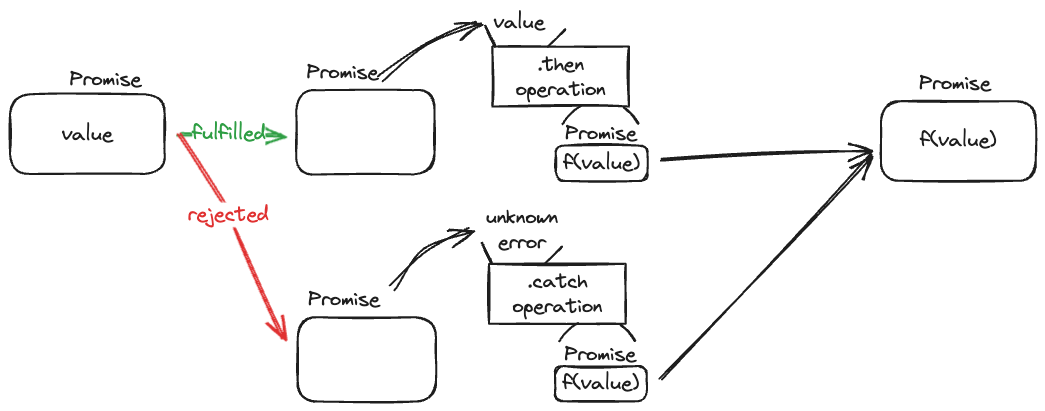
엇! 그런데 이상한 점이 보이시죠? Array에서는 map과 flatMap이 서로 다른 함수였습니다. 그런데 Promise는 왜 같은 then 함수에서 map과 flatMap을 동시에 처리할까요?
그건 Promise가 Monadic하기 때문입니다. 드디어 등장해버린 Monad!!
Monad
말만 들어도 무섭고 떨리는 "모나드"는 무엇일까요? 제가 감히 모나드를 설명해도 되는가는 의문이지만 생각보다 우리가 코딩할 때 자주 사용되기 때문에 이를 바탕으로 느낌만 짚어보고 넘어 가겠습니다.
저와 모나드에 대해서 얘기해보신 분들은 저의 비유를 들어보셨을 거예요.
모나드는 Promise입니다!!! 그것만 기억하세요!!
재차 말씀드리지만 이 기술 공유는 모나드를 설명하기 위한 기술 공유가 아니기 때문에 짧고 명료하게 설명하고 넘어가겠습니다.
const context_1 = Promise.resolve('Hello BBROS!'); // Promise<string>
const context_2 = context_1
.then(str => Promise.resolve(`${str} Ok... Bye...T^T`));
context_2; // Promise<Promise<string>>?
코드를 보면 context_2의 예상하는 타입은 Promise<Promise<string>>이지만 실제로는 Promise<string>만 받습니다. 그 이유는 Promise가 모나딕하기 때문인데요. 모나드라는 것은 결국 상자 안에 감싸인 값을 쉽게 처리하기 위해서 중첩해서 감싸지 않는다는 개념입니다. 만약 모나드가 지원되지 않았다면 context_2를 처리하기 위해서는 아래처럼 코드가 짜였겠죠?
context_2 // context_2 is Promise<Promise<string>>
.then(str2Promise => // str2Promise is Promise<string>
str2Promise.then(str2 => `Puke....`) // str2 is string
);
즉, flatMap을 지원하는 함자는 모나딕하다고 할 수 있습니다.
사실 모나드를 설명하려면 더 많은 내용이 들어가야 하지만 본론을 위해 여기까지만 알아보죠.
드디어 두둥 등장 "Result"
Result class는 사실 이미 많은 언어들에서 기본으로 지원하는 클래스 중 하나입니다.
Wikipedia에서는 이렇게 설명하고 있습니다.
함수형 프로그래밍에서 결과 유형은 반환된 값 또는 오류 코드를 포함하는 모나딕 유형입니다. 모나딕 타입은 예외 처리에 의존하지 않고 오류를 처리하는 우아한 방법을 제공하며, 실패할 수 있는 함수가 결과 타입을 반환할 때 프로그래머는 예상 결과에 액세스하기 전에 성공 또는 실패 경로를 고려해야 하므로 프로그래머의 잘못된 가정이 발생할 가능성을 제거합니다.
그나마 대중적인 Kotlin으로 살짝 살펴볼까요?
inline class Result<out T> : Serializable
A discriminated union that encapsulates a successful outcome with a value of type T or a failure with an arbitrary Throwable exception. (번역) 유형 T의 값으로 성공적인 결과를 캡슐화하거나 임의의 Throwable 예외로 실패를 캡슐화하는 차별적 결합입니다.
차별적 결합? 인터페이스 형태를 구분할 수 있는 공통된 property를 가진 인터페이스들�의 결합
interface A {
type: 'A';
value: string;
}
interface B {
type: 'B';
value: number;
}
type C = A | B;
if (some.type === 'A') {
typeof some.value === 'string';
} else {
typeof some.value === 'number';
}
이렇게만 보면 Promise<T>와 다를 바가 없어보입니다. 하지만 Promise와는 다르게 명시적으로 Error를 어떻게 처리할 것인지 알려주어야만 값을 얻을 수 있습니다.
runCatching {
login() // Result<User>
}
.getOrNull() // 에러면 null을 반환
.getOrDefault(fakeUser) // 에러면 기본값 반환
.getOrElse(err ->
// 에러면 실행
)
.exceptionOrNull() // 에러면 에러 객체 반환
.getOrThrow() // 에러면 throw Error // 가질 수 없다면 부숴버리겠어!!
반면, Promise는 성공/실패 핸들링을 명시하지 않아도 값을 얻을 수 있습니다.
await Promise.reject(new Error('This is a error'));
그런데 Kotlin도 단점이 있는데 그건 Error Type을 알 수 없다는 점이죠. Rust, Haskell, Scala, Swift는 모두 실패 타입과 성공 타입을 기술하도록 되어 있습니다. 내가 실패할 경우 어떤 에러를 받게 될지 명확하게 알 수 있죠.
pub enum Result<T, E> {
Ok(T),
Err(E),
}
그래서 만든 Result 구경이나 좀 해봅시다.
원래는 Effect라는 라이브러리를 통해서 Lazy execution으로 구현하였으나, Promise에 익숙하신 분들이 보다 쉽게 사용하실 수 있도록 Promise 상속 class로 새롭게 만들었습니다.
class Result<Error, Ok> extends Promise<[Error, Ok]>;
왜 오픈 소스 라이브러리를 안쓰셨나요?
이 섹션은 비브로스 백엔드팀 안에서 공유한 라이브러리에 대한 내용이 들어가 있습니다만 다른 알려진 라이브러리를 통해서도 인사이트를 얻을 수 있을 것이라고 판단하여 글의 내용을 지우지 않았습니다.
여러분들과 함께 일하며 자주 느끼는 것인데 러닝커브가 높으면 잘 안쓰시더라구요? 그리고 아무래도 Typescript + NodeJS 진영에서 FP가 마이너한 영역이다 보니 여러분들이 충분히 쓰실 수 있을 만한 수준에서 관리할 필요가 있었습니다.
기본 사용법
쉽게 보는 비교표!
| 기능 | Promise<T> | Result<E, T> |
|---|---|---|
| �성공 객체 | Promise.resolve | Result.succeed |
| 실패 객체 | Promise.reject | Result.fail |
| 객체 값 수정 | Promise.prototype.then | Result.prototype.map |
| 객체 연결 | Promise.prototype.then | Result.prototype.flatMapResult.prototype.chain |
| await 결과 | T | Either<E, T> |
| 에러 수정 | Promise.prototype.catch | Result.prototype.orElse |
// Result 성공 만들기
const name: Result<never, string> = Result.succeed('yoonho');
const say = (text) => console.log(text);
// Result의 성공 값을 변경하기
const greeting: Result<never, string> = name
.map(name => `Hello, ${name}!`);
.tap(say);
// 값이 없으면 Failure로 분리하기
const failNotFound = (value: User): Result<NotFoundError, User> => {
if (value == null) {
return Result.fail(new NotFoundError('사용자를 찾을 수 없습니다.'));
}
return Result.succeed(value);
}
// 이름으로 사용자 조회
const findUserByName = name => Result.from(
User.findOne({ name })
).flatMap(failNotFound);
export const exec = async () => {
const user = await name.flatMap(findUserByName).getOrThrow();
return user;
}
그럼 기존 것들 다 마이그레이션 해야 하나요?
아뇨! 언어 자체적으로 Result Type을 지원하는게 아닌 이상 모든 Promise를 마이그레이션 할 필요는 없습니다. 기존에 잘되는 것이라면 더더욱이요!
그럼 앞으로 무조건 Promise 말고 Result를 사용해야 할까요? 그것도 아닙니다. 단순하고 오히려 Result가 가독성이나 코드 흐름을 복잡하게 만든다면 Promise가 더 좋습니다.
예를 들어 아래의 경우는 그냥 Promise 패턴을 쓰는게 낫겠죠.
- 어떤 Error가 발생할지 모르고 어떻게 처리해야 하는지도 모르는 경우
- 이미 구현된 Promise 처리에서 완벽하게 에러 처리가 되는 경우
후기
그래서 Result Type을 쓰고 나니 어떤가 궁금하실 것 같아요.
사이드 이펙트를 줄일 수 있다(에러를 예상할 수 있다)
저의 경험상 에러를 처리해야 하는 로직에서 어떤 에러가 발생할지 예상할 수 있는 부분이 첫째로 좋았습니다. 에러라는 게 어느 포인트에서나 발생하고 처리할 수 있는 것이지만, 특히나 의도적으로 에러를 내는 경우에 특히 편하다고 생각했습니다.
예를 들면 Controller가 비즈니스 로직 후 응답을 내려줄 때인데요.
export class APIController {
async legacyRequest(
@Queries() queries: LegacyRequestQueries
): Promise<Response> {
try {
return await service(queries);
} catch (error) { // error is unknown
// error의 타입으로 알 수 없기 때문에 개발자가 알아서 찾아야 하는 부분
if (error instanceof BadRequestError) {
// ...
} else if (error instanceof NotFoundError) {
// ...
}
return new InternalServerError(error.message, { cause: error });
}
}
async newRequest(
@Queries() queries: NewRequestQueries
): Promise<Response | ErrorResponse> {
const resp: Response | BadRequestError | NotFoundError | InternalServerError =
await service(queries).getOrElse(error =>
// Really unknown error
new InternalServerError(error.message || error, { cause: error })
);
// resp의 타입 중 하나이기 때문에 개발자의 실수를 줄여줌
if (resp instanceof BadRequestError) {
// ...
} else if (resp instanceof NotFoundError) {
// ...
}
return resp;
}
}
error가 어떻게 나올지 몰랐을 때는 사이드 이펙트가 터지기를 기다리거나 일일이 확인했어야 했는데 Result Type을 적용한 이후로는 최소한 Result Type이 적용된 서비스에서는 원하는 에러의 분기를 걱정할 필요가 없어졌습니다.
너 빼고 다 알아
Promise는 너무 뻔하게 에러가 예상되는 상황에서도 어떤 에러인지 추론하지 못하는 경우가 있습니다.
const service = async (userId: string) => {
const user = await getUser(userId)
.catch(() => null)
.then((user: User | null) => {
if (!user) {
throw new NotFoundError('사용자를 찾지 못했습니다');
}
return user;
})
.catch(error => {
logger.error(error.message); // lint error: 'error' is of type 'unknown'.
});
};
비단 위의 경우가 아니더라도 이미 에러 타입을 아는데도 핸들링 하기 위해서 Type Guard를 써야 하는 등의 불편함이 있습니다. 하지만 Result Type을 쓴 이후로는 타입 명시의 불편함이 줄어들었습니다. 이는 코드 가독성이 한결 좋아졌다는 의미이기도 합니다.
const service = async (userId: string) => {
const user = await getUserResult(userId)
.orElse(() => Result.succeed(null))
.flatMap((user: User | null) => {
if (!user) {
return Result.fail(new NotFoundError('사용자를 찾지 못했습니다.'));
}
return Result.suecced(user);
})
.tapError(error => { // 'error' is 'NotFoundError'
logger.error(error.message);
});
};
흐름의 연속성이 좋아진다
Promise의 경우(면밀히 말하면 async/await 패턴의 경우) "성공에 집중"하기 때문에 코드가 깔끔해보이고 흐름이 자연스럽게 느껴집니다.
const service = async (userId: string) => {
const user = await getUser(userId);
if (!user) {
throw new NotFoundError('사용자를 찾지 못했습니다.');
}
const posts = await getPostByUserId(user.id);
if (posts.length === 0) {
throw new NotFoundError('사용자의 글을 찾지 못했습니다.');
}
return posts;
}
하지만 만약 예외 처리를 해야한다면 코드는 꽤나 더러워집니다.
const service = async (userId: string) => {
// try catch 구문을 중첩하지 않으려면 블록 범위 바깥에 지역변수를 만드는건 어쩔 수 없는 부분입니다.
let user: User | null, posts: Post[];
try {
user = await getUser(userId);
} catch (error) {
logger.error('Catch error by `getUser`.', error);
throw new InternalServerError(error.message, { cause: error });
}
if (!user) {
throw new NotFoundError('사용자를 찾지 못했습니다.');
}
try {
posts = await getPostsByIds(user.favoritePostIds);
} catch (error) {
logger.error('Catch error by `getPostsByIds`.', error);
throw new InternalServerError(error.message, { cause: error });
}
if (posts.length === 0) {
throw new NotFoundError('즐겨찾기 글을 찾지 못했습니다.');
}
return posts;
}
Result Type을 사용한다면 이렇게 해결할 수 있을 겁니다.
const service = (userId: string) => {
const userResult = Result.from(getUser(userId))
.tapError(error => logger.error('Catch error by `getUser`', error))
.flatMap(fromNullable(new NotFoundError('사용자를 찾지 못했습니다.')));
const postsResult = (user) =>
Result.from(getPostsByIds(user.favoritePostIds))
.tapError(error => logger.error('Catch error by `getPostsByIds`', error))
.flatMap(posts => {
return posts.length === 0
? Result.fail(new NotFoundError('즐겨찾기 글을 찾지 못했습니다.'))
: Result.succeed(posts);
});
return userResult
.flatmap(postsResult)
.mapError(error => new InternalServerError(error.message, { cause: error }));
}
그 외에도 사용하면서 느낀 장단점이 있지만 개발에 Silver Bullet이 없듯이 Result Type 또한 적재적소에 활용한다면 사이드 이펙트를 줄이고 개발 경험을 상승 시킬 수 있습니다.
아는 것은 힘이라는 말이 있듯이 조금은 낯선 이 Pattern이 여러분들의 Happy Hacking을 돕기를 바랍니다.