AWS Node Auto Scaler Karpenter 도입기

안녕하세요, 비브로스 백엔팀에서 인프라를 맡고 있는 박진홍입니다.
23년 상반기 EKS Blue-Green 업데이트에 이어 Karpenter 도입기를 소개해드리고자 합니다.
기존 AWS Cluster AutoScaler를 사용하였지만, 스파크성 트래픽시 노드 스케일링 속도에 문제가 있었고 비용 최적화를 위해 Karpenter 도입에 대해 고민하였습니다.
시작하기전 Kubernetes 엔지니어들의 많은 고심이겠지만.. 인프라의 변경사항은 "낭만이 아니라 헬이다!!!" 라는 말과 같이 유사한 영상이 있어 공유드립니다!
웃으면서 봐주시면 감사하겠습니다. 😂

Karpenter 도입 계기

비브로스의 “똑닥” 어플은 실시간 병원 접수/예약 서비스를 제공하고 있습니다. 매일 사용자가 몰리는 아침, 점심 그리고 새벽에 크게 스파크성 트래픽이 쏟아지게 되어 서버, 데이터베이스에 과부하로 서비스 지연 및 장애가 발생하게 됩니다. 사전에 인프라 리소스를 예측하여 늘려놓아도 독감시즌 및 연휴이후 평일에 병원을 내원하시는분들이 많아서 예측하기 어렵고, 무한정 인프라를 늘리기에는 클라우드 비용에 대한 제약사항이 있어 다른 방안을 찾게 되었습니다.
현재 똑닥 인프라는 ECS(Elastic Container Service)에서 EKS(Elastic Kubernetes Service)로 모두 마이그레이션하여 사용하고 있고, 백엔드 서비스 뿐만아니라 Cron Job, Batch Job, Action Runner를 Kubernetes 환경에서 사용하고 있습니다.
Kubernetes 노드 프로비저너로 기존 Cluster Autoscaler를 통해 Manage NodeGroup(서비스 개별)으로 노드 프로비저닝을 하였지만, 스파크성 트래픽이 몰릴 경우 노드가 늘어나는 시간이 오래걸리고, 원하는 인스턴스 타입으로 비용 최적화를 할 수 없다는 단점이 있었습니다.
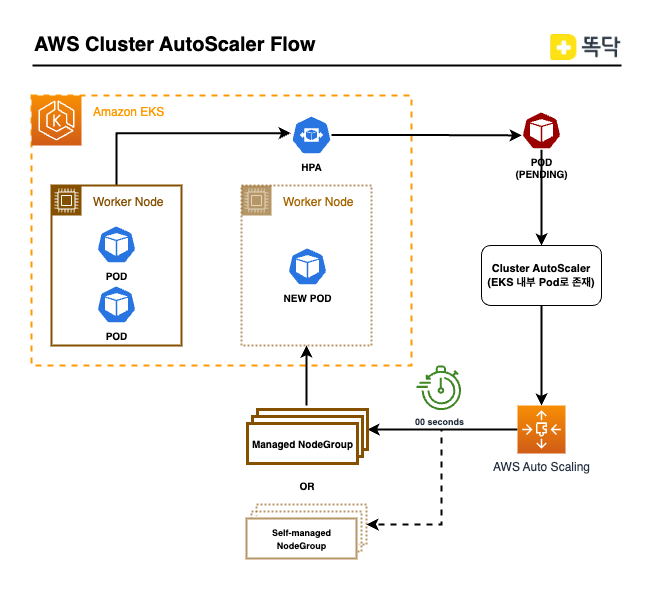
기존 똑닥 인프라는 Auto Scaling Group(이하 ASG)를 통해 Cluster Autoscaler 기능이 구현되어 있음
Cluster AutoScaler 작동 원리
- Pod가 배포/확장되어 더이상 기존 노드에 배정받지 못할 경우 Pod는 PENDING 상태가 됩니다.
- Cluster AucoScaler�는 AWS ASG을 통하여 자동으로 노드를 추가/제거 합니다.
- PENDING 상태의 Pod는 새로 구성된 노드로 Kube-scheduler에 의해 새로운 노드로 배정합니다.
이에 인프라 부서에서는 노드의 프로비저닝을 기존 Cluster Autoscaler(이하 CA) 에서 프로비저닝 속도가 빠른 Karpenter로 변경하게 기획하였습니다.
Karpenter 알아보기
Karpenter란 2020년 11월에 출시된 오픈소스로 Kubernetes 예약할 수 없는 파드를 감지하고, 새로운 노드를 자동 확장/병합/제거가 가능한 노드 스케일러 이며 구성항목으로는 “Provisioner”와 “AWSNodeTemplate” 를 통해 구성할 수 있습니다.
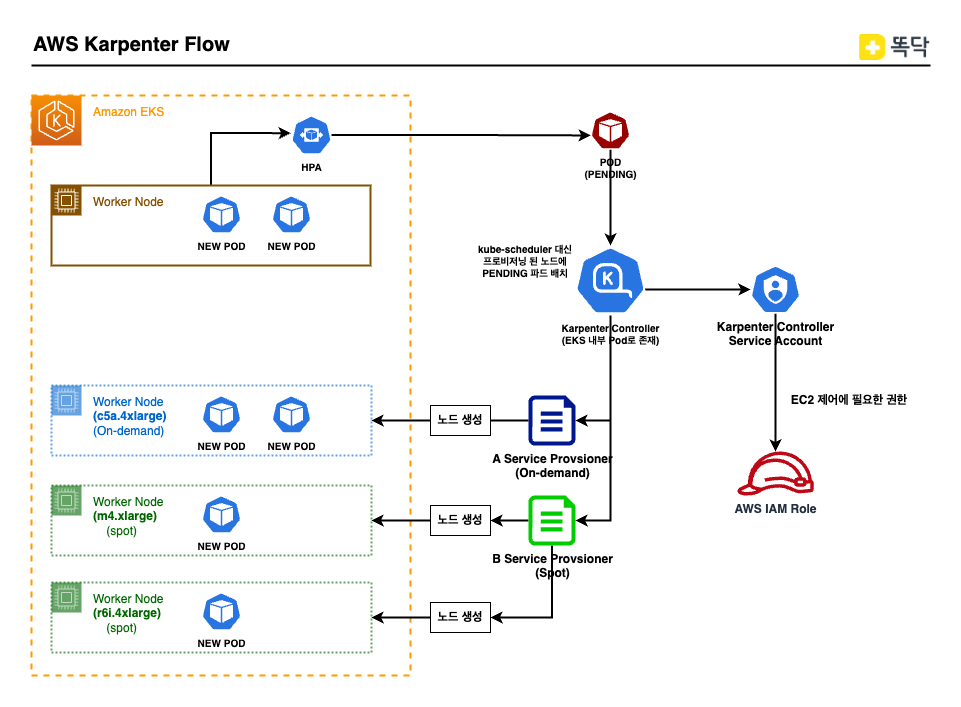
Karpenter 작동 원리
- Pod가 배포/확장되어 더이상 기존 노드에 배정받지 못할 경우 Pod는 PENDING 상태가 됩니다.
- Karpenter는 스케쥴링 되지 않은 Pod를 관찰하고, Provisioner 조건에 맞는 EC2 인스턴스 타입을 결정하고, EC2 Fleet 요청을 통해 인스턴스를 생성합니다.
- 추가된 노드가 준비되면, Karpenter는 kube-scheduler 대신해서 Pod를 노드에 배치합니다.
위와 같이 CA와 다르게, PENDING인 Pod가 있을 경우 실시간(Just-in-time)으로 프로비저닝하게 되며, 사전에 설정한 프로비저닝 �조건에 맞춰 확장이 일어나게 됩니다. Karpenter 도입시 장점을 정리해보면 하기와 같습니다.
Karpenter 장점
-
노드의 리소스가 부족할때 빠른 노드 추가와 제거 그리고 병합 Karpenter를 사용하면 CA를 사용할때 보다 눈에 띄게 노드가 프로비저닝 되는 속도가 빨라지게 됩니다. CA와 동일하게 POD가 배포될 수 있는 노드가 없어 PENDING될 경우 그 즉시 최적의 노드를 찾아서 노드를 배포하게 됩니다. (인스턴스 타입마다 상이하지만 CA 대비 약 1분~2분 빨라짐)
똑닥 사용자가 몰리는 피크타임이 끝나면 노드는 자동적으로 줄어들고 병합됩니다. 노드 종료에 대한 방법은 Provisioner CRD를 통해 선언할 수 있는데 똑닥은 사용 목적에 따라 “ttlSecondsAfterEmpty” 와 “consolidation” 를 같이 사용하고 있습니다.
## 둘중 하나만 사용 가능하며, 사용목적에 따라 나눠서 사용중
# consolidation 기반 예시
spec:
consolidation:
enabled: true
# ttl 기반 예시
spec:
ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
ttlSecondsAfterEmpty: 30 -
다양한 인스턴스 타입 사용 및 비용 최적화 기존 Managed NodeGroup을 사용할 경우 ASG 와 Launch Template을 별도로 추가하고 관리하였는데, Karpenter 를 도입하고 나서는 Provisioner에 손쉽게 선언하고 사용할 수 있습니다.
spec:
requirements:
## on-demand, spot 선택 또는 둘다 동시 사용
- key: "karpenter.sh/capacity-type"
operator: In
values: ["on-demand"]
## 어느 가용용역에 배포
- key: "topology.kubernetes.io/zone"
operator: In
values: [ "ap-northeast-2a", "ap-northeast-2c" ]
## 특정 인스턴스 타입으로 선언이 가능
- key: "node.kubernetes.io/instance-type"
operator: In
values: [ "c5a.4xlarge", "c5a.8xlarge" ]
## 인스턴스 패밀리로 선언이 가능
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: ["c"]다양한 인스턴스 타입을 통해 리전내 인스턴스 가용성을 높히고, Karpenter에 의해 Pod가 적절한 노드에 배치됩니다. 똑닥 서스는 Memory보다는 CPU를 더 많이 사용는 서비스들이 많아서 C 패밀리(cpu:mem = 1:2) 타입을 사용하여 비용절감을 위해 Reserved Instance(이하 RI)와 Saving Plain(이하 SP)를 같이 사용하고 있습니다.
"C" 패밀리 타입안에서 다양한 인스턴스 타입을 통해 “Bin-Packing”전략을 통해 클러스터 내의 노드 사용량을 최적화하여 비용 절감과 RI/SP 에 대해 더 많은 효과를 볼 수 있습니다.
Bin-Packing : 사용하는 노드 Fit 하게 리소스를 할당하여 다른 노드에 남는 리소스가 없게 스케쥴링 됨
그리고 On-demand, Spot Instance에 대해서도 가격 용량 최적화 할당(price-capacity-optimized)전략 기반의 인스턴스를 생성할 수 있습니다. Spot 인스턴스의 경우는 가격이 낮고 중단 가능성이 가장 낮은 인스턴스 유형이 선택��됩니다.
Karpenter 적용
Karpenter 적용은 Helm Chart 와 Kustomzie를 통한 각 멀티 클러스터에 자동 적용되게 구성되어 있습니다. (구성 방법에 대해서는 공식문서를 참고 부탁드립니다)
아래는 CA 에서 Karpenter를 적용하는 과정에 대해 사전 고려 사항과 진행하면서 이슈 사항에 대해 말씀드리고자 합니다.
현재 고려사항과 이슈사항을 적용한 아키텍처는 하기와 같습니다.
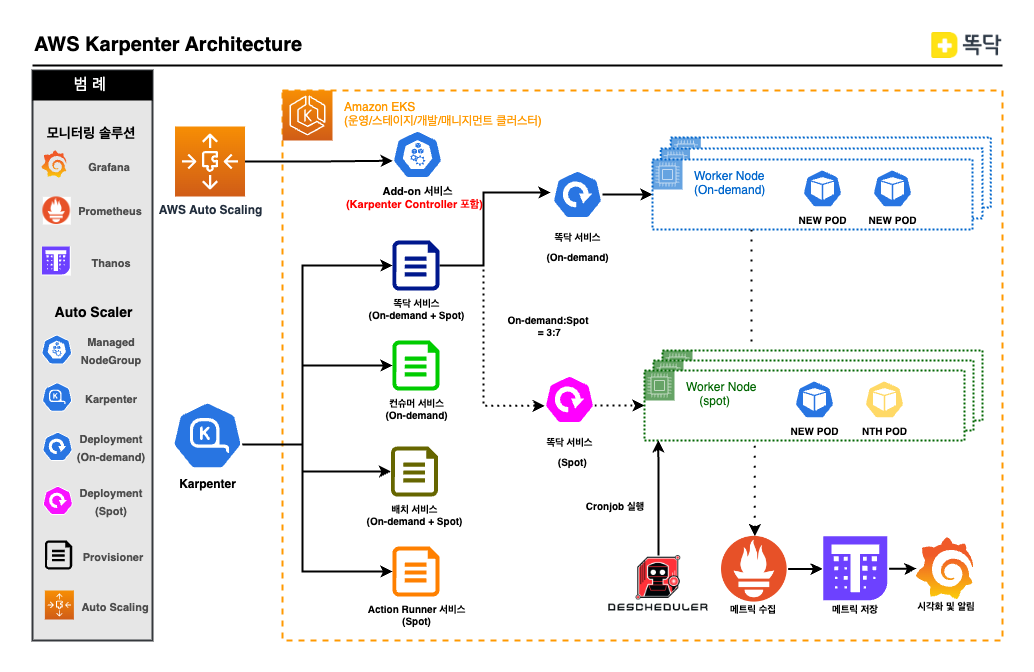
고려 사항
-
NodeGroup에서 Provisioner 변경 설계 기존 서비스목적별로 Internal/External/Office/Solution NodeGroup이 별도로 존재하였습니다. 해당 노드그룹에 대해 재정의하고 Add-on 과 karpenter Controller는 노드의 스케일링이 일어나지 않으므로 1개의 노드그룹에서 별도 관리하며, 다른 서비스들은 사용목적과 인스턴스 타입을 고려하여 Provisioner와 AWSNodeTemplate 를 구성하였습니다. (NodeGroup 뿐만 아닌 Fargate를 통해 배포하는 방법도 존재)
-
NTH(aws-node-termination-handler) 도입 Karpenter는 Spot 노드의 Rebalance Recommendation를 지원하지않아 서비스 운영시 문제가 될 수 있다.
만약 Spot Instance가 Interrupt가 발생시 2분내로 서비�스가 정상 종료되어야 하는데, 정상종료 되지 않는 경우 서비스 장애로 이어질수 있다. 이에 NTH(IMDS Mode)를 통해 다른 노드로 이전될 수 있게 설정합니다.
또한 “PreStop”, “terminationGracePeriodSeconds”, “PodDisruptionBudget” 설정을 통해 파드가 정상적으로 종료할수 있는 시간과 이전시 파드수량에 대해서 보장할 수 있게 설정하였습니다.
## 똑닥 Helm Chart value.yaml 중 일부
server-dd-template:
# TerminationGracePeriodSeconds Update
terminationGracePeriodSeconds: "40"
# Lifecycle Events
lifecycle:
preStop:
exec:
command:
- sh
- -c
- "sleep 30"
## Allow PDB to Service
pdb:
enabled: false
minAvailable: 2
maxAvailable: ""그리고 보다 효율적이고 안정적인 방법을 위해 일정 비율로 On-demand 와 Spot Instance의 Deployment를 나눠서 운영하게 되었습니다. (현재는
on-demand:spot = 3:7로 구성) -
Spot Instance 모니터링 Spot Instance Interrupt가 발생할 경우 알림에 대해서 어떻게 받을지 고민하였는데, 옵저버빌리티로 멀티 클러스터 관측을 위한 Grafana가 구성되어 있습니다. 해당 Grafana를 통해 Karpenter에서 제공하는 메트릭 기반의 알림을 구성하였습니다.
이슈 사항
-
Provisioner의 리소스 할당 이슈 각 서비스 항목에 맞춰 Provisioner를 생성하였지만, 해당 Provisioner에 할당된 리소스 이상을 요구할 경우 노드가 프로비저닝 되지 않는 문제가 발생하였습니다. 해당 프로비저너의 리소스할당을 여유롭게 설정해야 합니다.
# Provisioner On-demand Instance yaml 일부
spec:
# 할당할 수 있는 Limit 설정 필요
limits:
resources:
cpu: "500"
memory: 1000Gi -
deschduler 도입
AntiAffinity및TopologySpread그리고PodDisruptionBudget(이하 PDB) 로 인해 노드의 병합이 잘 이뤄지지 않는것을 확인할 수 있었습니다. PDB를 제거하기에는 Spot Instance가 Interrupt 발생시 Pod가 termination 되기에 서비스 장애가 발생할 수 있어서 다른 방법을 선택하게 되었습니다.여러 방법이 있었지만, 저희가 선택한 방법은 오픈소스인 deschduler를 도입하여 “Mostallocated + HighNodeUtilization”을 도입하려고 하였습니다. 다만, EKS는 기본 스케쥴링 설정이 “LeastALlocated” 을 변경할수 없으므로 “LeastAllocated + HighNodeUtilzation” 조합으로 설정하게 되었습니다.
해당 방법이 100% 해결해주지 않지만, 비용 절감에 효과가 있다고 판단되어 설정하게 되었습니다. 똑닥에서는 해당 deschduler를 병원업무시간이 끝나는 시간에 맞춰 Cronjob 형태로 작동하고 있습니다.
# PDB로 인한 노드 스케쥴링 불가시 노드 이벤트
events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal DeprovisioningBlocked 9m15s (x13 over 71m) karpenter Cannot deprovision Node: PDB "community/dd-community-spot" prevents pod evictions
# 노드의 병합이 이뤄지지 않을때 노드 이벤트
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Unconsolidatable 4m20s (x80 over 21h) karpenter Can't replace with a cheaper node -
EBS CSI Driver 이슈 AWS EKS 1.23+ 부터는 IAM Role에 EBS CSI Driver 권한이 필요합니다. Karpenter 추가시 해당 Role을 추가로 추가해줘야 EBS CSI Driver Controller에 문제가 발생하지 않습니다.
-
Karpenter 적용후 Cluster 제거시 이슈 Karpenter 테스트를 위한 Sandbox Cluster 생성하였는데, 테스트 이후 제거시 클러스터를 제거하여도 Karpenter로 배포된 노드는 제거되지가 않았습니다. 반드시 Karpenter 제거후 Cluster를 제거해야 합니다.
-
On-demand , Spot Deployment 2개를 운용시 이슈 External 트래픽에 대해서는 AWS ELB 에서 가중치기반으로 설정하지만, Kubernetes Internal 트래픽에 대한 가중치기반 설정이 필요하지만 현재 똑닥 인프라에서는 별도 게이트웨이를 만들어서 사용하고 있습니다. 해당 기능을 추가하기 전까지는 On-demand:Spot 에 대해 가중치기반으로 트래픽을 제어할 수 없다는 단점이 있어서 향후 해당부분은 개선하고자 합니다. 기존 게이트웨이를 사용하는 방식 외 대체 오픈소스로는 Kong, Istio 와 같은 게이트웨이 제품으로도 구현이 가능합니다.
그래서 효과는?
2023년 10월에 Karpenter를 도입하고 나서 변화에 대해 확인합니다.
첫번째로 트래픽이 몰리지 않는 새벽시간에 노드의 ��사용 수량이 줄어든것을 확인할 수 있습니다. 즉 노드의 병합이 잘 이뤄져 Bin-Packing 전략이 동작한 것을 확인할 수 있습니다.
- 새벽시간 기준 20(19) -> 17 node
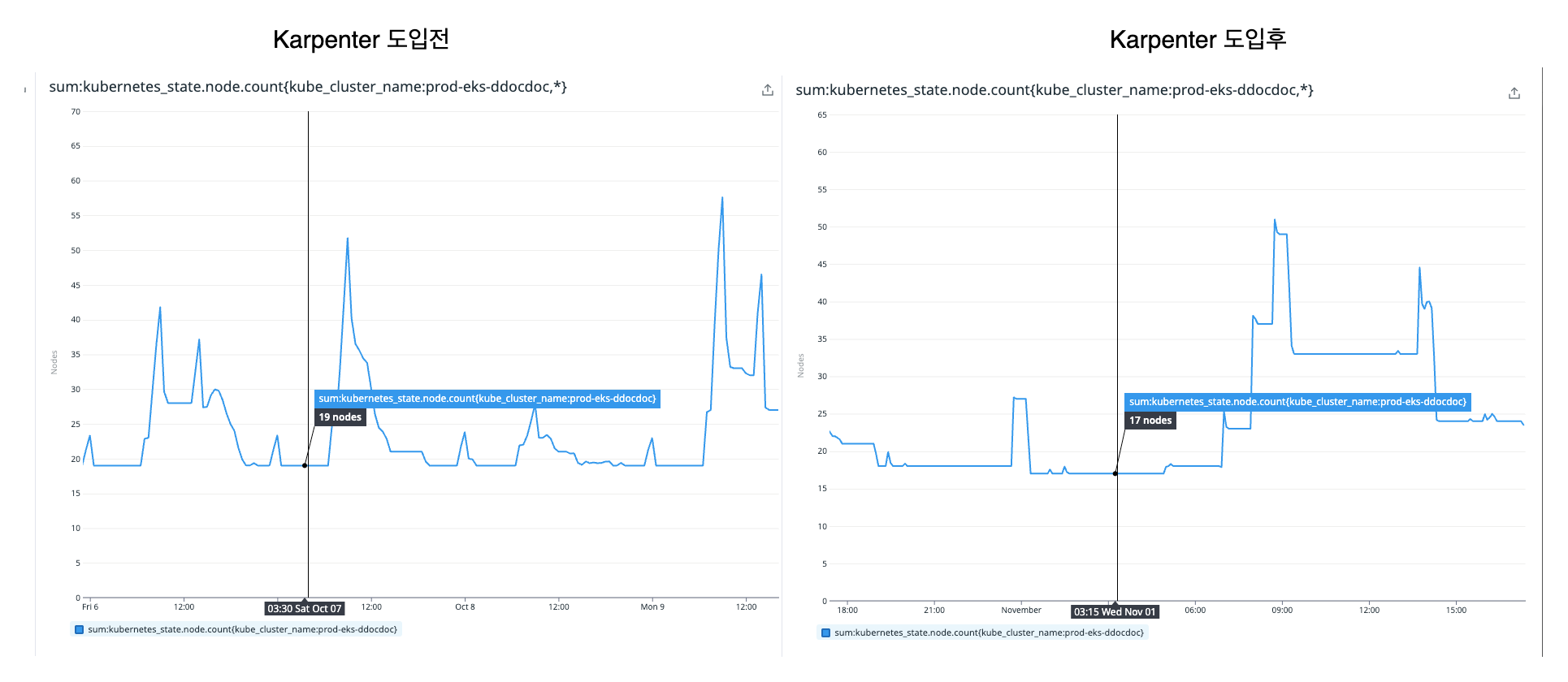
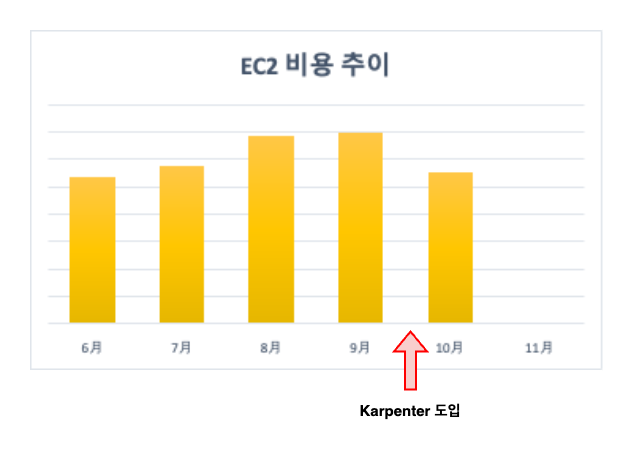
또한 독감시즌으로 병원을 내원하는 사용자가 증가하였지만, EC2 비용은 Karpenter 도입하기전 비용보다 절감한것을 확인할 수 있습니다.
마지막으로 기존 On-demand Node Group을 통해 Batch 와 Action Runner를 구성하였는데, 다양한 인스턴스 타입으로 필요 요청량 기반으로 인스턴스 타입을 선택하여 실행할 수 있게 구성하였습니다. 빠른 프로비저닝 및 비용 절감효과를 얻게 되었습니다.
마치며
Karpenter를 도입하면서 정말 많은 시나리오 테스트를 진행한것 같습니다.
특히 똑닥 인프라는 스파크성 트래픽이 매일 발생하기에 빠른 프로비저닝과 빠른 병합 및 제거를 통해 비용효과를 보고자 안정성테스트를 많이 진행하였습니다. 또한 Bin-Packing 전략이 제대로 작동하는지에 대해서도 여러 테스트를 진행한것이 기억에 남고, 이러한 테스트로 인해 운영환경에 적용하였을때 안정성이 보장되었던것 같습니다.
그리고 Karpenter를 0.31 version으로 구�성하였는데, 곧바로 0.32 version이 나오게 되었습니다. 만약 현재 버전에 필요 기능이 없을 경우, 새로운 버전을 확인하고 새로 구축한다면 가장 최신버전을 구성하는것을 추천드립니다.
AWS Blog 및 다른 기업에서도 Karpenter를 도입 사례의 글이 많아지는것 같습니다. 본 글을 통해 Karpenter 도입에 고민이 있으신분들에게 조금이나마 도움이 되었으면 좋겠습니다.
마지막으로 잘못된 정보가 있다면 알려주시면 감사하겠습니다.
감사합니다! 😄