똑닥닷컴 SEO(a.k.a. 네이버 월 노출 수 1000만 달성기)


안녕하세요. 비브로스 프론트엔드 개발자 박서영입니다.
혹시 네이버에서 ‘아기 토’, ‘38도’와 같은 건강 키워드를 검색했을 때, 검색 결과에서 똑닥닷컴을 발견한 적 있으실까요? 불과 1년 전만 해도 똑닥닷컴의 커뮤니티 페이지들은 네이버와 구글 검색 결과에 노출되지 않았습니다. 그러나 최근 검색엔진 최적화 작업을 통해 똑닥닷컴 전반의 검색 노출 성과를 개선하였는데요. 그 결과, 네이버 월 노출 수는 약 2만 건에서 1,000만 건으로, 구글 월 노출 수는 7천 건에서 90만 건으로 증가하였습니다.
이번 글에서는 검색엔진 최적화 작업을 진행하며 알게 된 지식을 공유하고, 도움이 될 만한 문서 및 개발 도구들도 같이 소개해 드리겠습니다.
검색엔진에 페이지를 등록하자!
네이버/구글 수집 요청
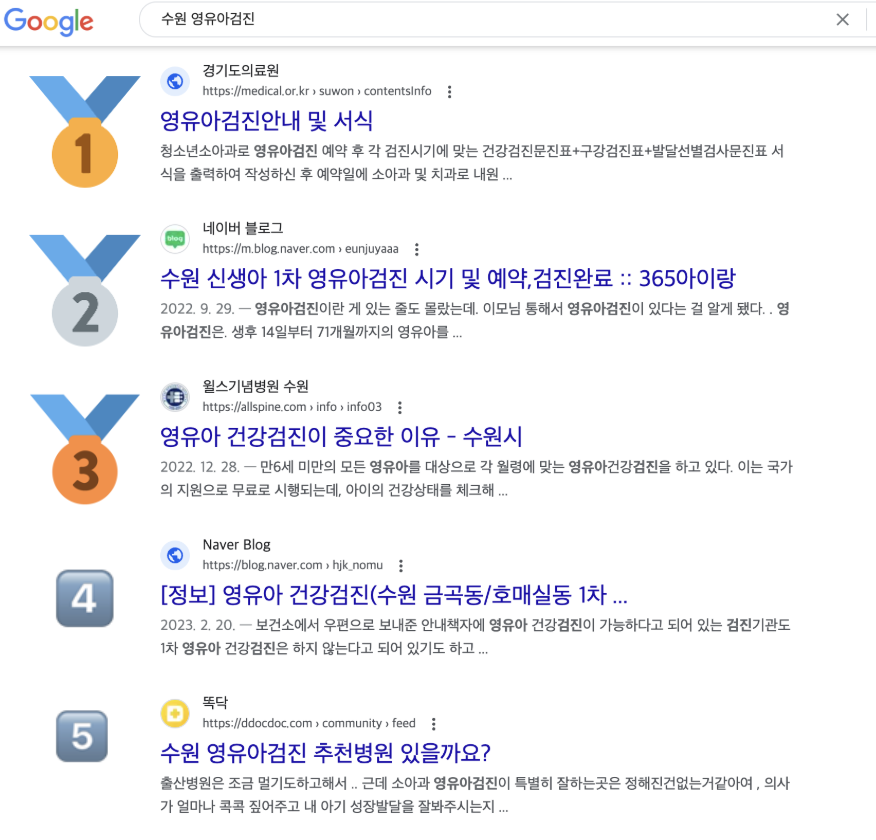
SEO(Search Engine Optimization, 검색엔진 최적화)란 검색엔진 결과 페이지(SERP)에서 더 높은 순위를 차지할 수 있도록 하는 전략과 기법을 의미합니다. 그러나 처음 웹페이지를 만들면 상위 노출은 고사하고 검색 결과에 노출되지 않는 경험을 하게 됩니다. 이는 소유한 페이지가 검색엔진에 의해 크롤링(crawling) 및 인덱싱(indexing)되는 과정이 필요하기 때문입니다.
크롤링이란 크롤러라는 봇이 웹페이지를 수집하는 행위를 말합니다. 크롤러는 페이지의 링크를 따라가며 다른 페이지로 이동하며, 주기적으로 재방문해서 최신콘텐츠를 반영합니다.
인덱싱이란 수집한 데이터들을 데이터 베이스 저장하고 색인하는 행위를 의미합니다. 검색엔진은 페이지의 메타데이터, 콘텐츠, URL 등의 정보를 저장하여, 특정 키워드를 검색했을 때 검색 결과를 빠르게 제공합니다.
네이버 서치 어드바이저와 구글 서치 콘솔에 도메인을 등록해 검색엔진에 크롤링을 요청할 수 있습니다. 그리고 페이지의 크롤링 상태, 노출 수, 클릭 수 등 다양한 검색 데이터를 확인할 수 있습니다.
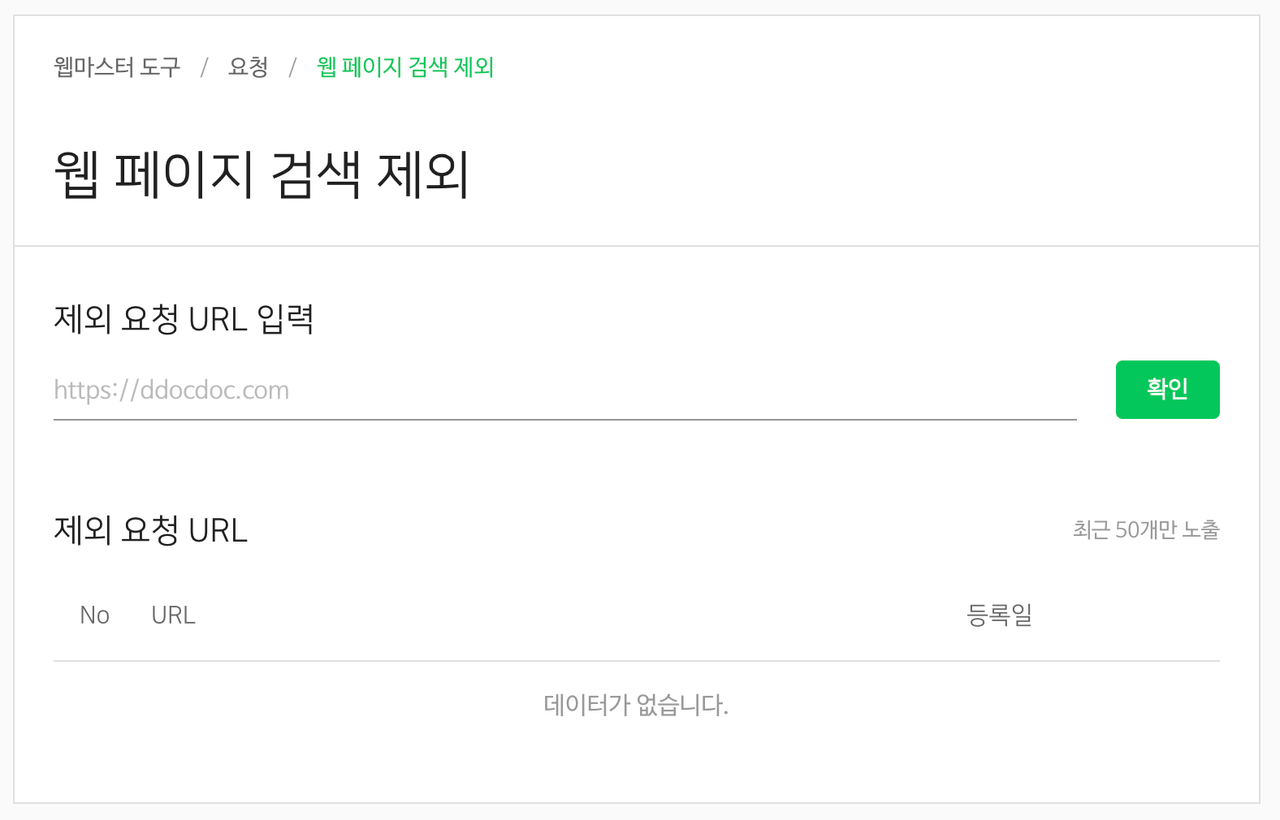
네이버/구글 웹페이지 검색 제외 요청
검색 결과에서 긴급히 삭제해야 하는 페이지는 단일 URL(path)로 검색 엔진에 제외 요청을 할 수 있습니다
네이버는 [네이버 웹마스터 도구] → [요청] → [웹페이지 검색 제외]에서, 구글은 [구글 서치 콘솔] → [삭제]에서 설정할 수 있습니다.
웹사이트 가이드를 제공하자!
sitemap.xml
sitemap.xml은 페이지 목록을 XML 형식으로 나열하여 책의 목차처럼 작동합니다. 이를 통해 검색엔진 크롤러에 크롤링해야 할 URL뿐만 아니라 최종 업데이트 시기, 업데이트 빈도, 페이지의 우선순위 등의 추가 정보를 전달할 수 있습니다.
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
/* 페이지의 URL */
<loc>https://ddocdoc.com</loc>
/* 페이지의 마지막 수정 날짜 (예: YYYY-MM-DD 또는 YYYY-MM-DDThh:mm:ss.sTZD) */
<lastmod>2025-02-24T08:00:52.495Z</lastmod>
/* 페이지의 변경 빈도 (예: daily, weekly, monthly) */
<changefreq>daily</changefreq>
/* 페이지의 중요도 설정 (예: 0.0 ~ 1.0) */
<priority>1.0</priority>
</url>
</urlset>
사이트맵은 파일당 최대 50,000개의 URL 또는 50MB까지만 지원하므로, 이를 초과하면 여러 사이트맵으로 분할하고 인덱스 사이트맵을 활용하는 것이 좋습니다. 그리고 robots.txt 파일에 사이트맵 위치를 명시하면 검색 엔진 크롤러가 더 효율적으로 탐색할 수 있습니다.
robots.txt
robots.txt 파일은 검색엔진 크롤러에 어떤 페이지에 접근할 수 있고, 어떤 페이지는 비공개인지 알려주는 역할을 합니다. 모든 페이지를 허용하고 일부만 막는 블랙리스트 방식이나 모든 페이지를 막고 일부만 허용하는 화이트리스트 방식 등을 적용할 수 있습니다.
# User-agent: 특정 크롤러(봇)만을 대상으로 규칙을 적용
# '*'는 모든 크롤러에 적용됨을 의미 (예: Googlebot, Yeti, daum)
# Allow: 크롤링을 허용할 경로를 설정
# Disallow: 크롤링을 차단할 URL을 지정
# Sitemap: 사이트맵의 위치를 명시해 크롤러가 사이트 구조를 효율적으로 파악하도록 도움
User-agent: *
Allow: /$
Disallow: /
Sitemap: https://.../sitemap.xml
설정 후에는 구글 서치 콘솔과 네이버 서치 어드바이저에서 robots.txt 수집 상태를 검증하는 것이 좋습니다. Google robots.txt 사양과 네이버 robots.txt 설정 가이드를 참고하여 지원하는 와일드카드와 규칙 경합 시 우선순위 등을 확인할 수 있습니다.
heading 태그
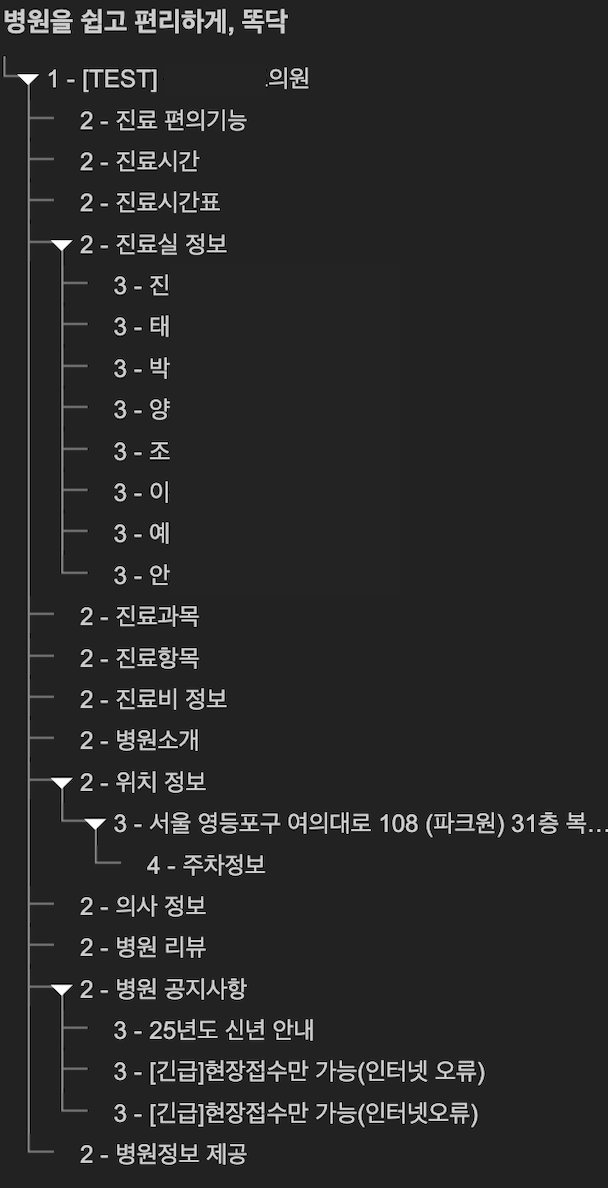
heading 태그는 페이지의 주요 콘텐츠를 강조하고 검색 엔진이 페이지의 내용을 이해하도록 돕습니다. h1 태그는 페이지당 하나만 사용하며 주요 주제를 나타내고, h2와 h3 태그는 섹션과 하위 섹션을 구분합니다. 크롬 확장 프로그램 headingsmap 을 사용하면 현재 페이지의 헤딩 구조를 쉽게 확인할 수 있습니다.
아래는 확장프로그램을 통해 똑닥닷컴 �병원 상세 페이지의 헤딩 태그 구조를 확인한 예시입니다.
클릭하게 만들자!
메타데이터(Metadata)
메타데이터는 웹페이지에 대한 설명을 제공하는 데이터입니다. 동일한 도메인 내 페이지들의 title과 description이 동일하면, 검색 엔진 크롤러가 페이지를 중복 콘텐츠로 인식하여 검색 결과에 표시하지 않을 가능성이 있습니다. 따라서 각 페이지의 성격에 맞게 메타데이터를 설정해 주는 것이 좋습니다.
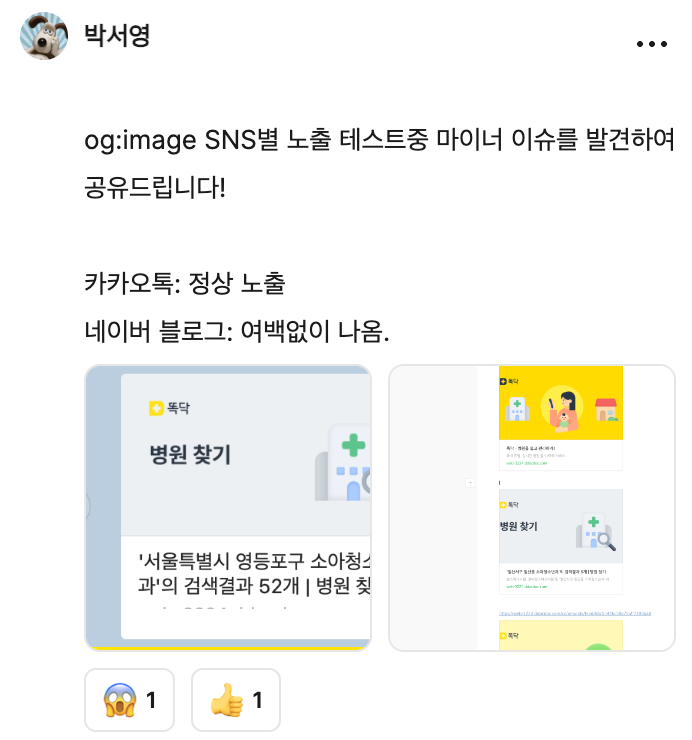
또 메타데이터의 Open Graph(OG) 태그를 활용하여 공유된 링크를 클릭하게 만드는 것도 중요합니다. 카카오톡이나 네이버 블로그에 링크를 공유했을 때 썸네일과 설명을 통해 사용자의 관심을 유도할 수 있습니다.
똑닥닷컴에서는 각 페이지별로 여러 가지 유형의 메타데이터를 제공하고 있습니다.
예를 들어 병원 검색 페이지는 검색 키워드와 더불어 검색 결과까지 description에서 확인할 수 있습니다.
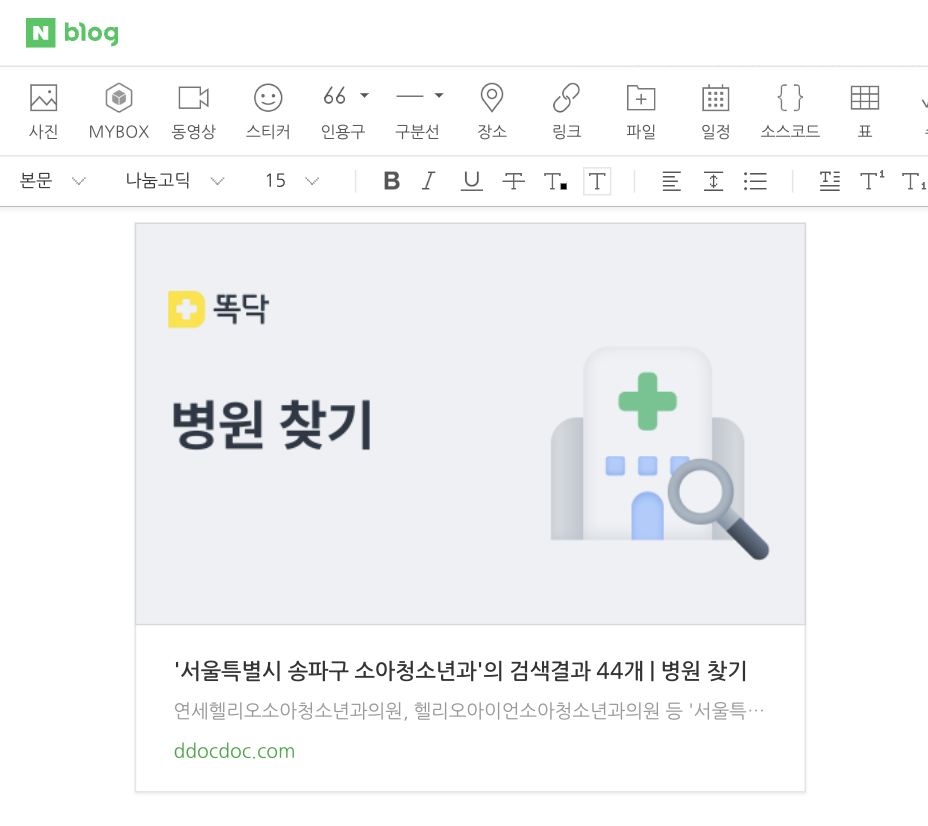
그리고 커뮤니티 피드 상세 페이지는 글에 이미지가 있는 경우 해당 이미지를 썸네일로 사용하고, 이미지가 없으면 기본 커뮤니티 이미지를 활용합니다.
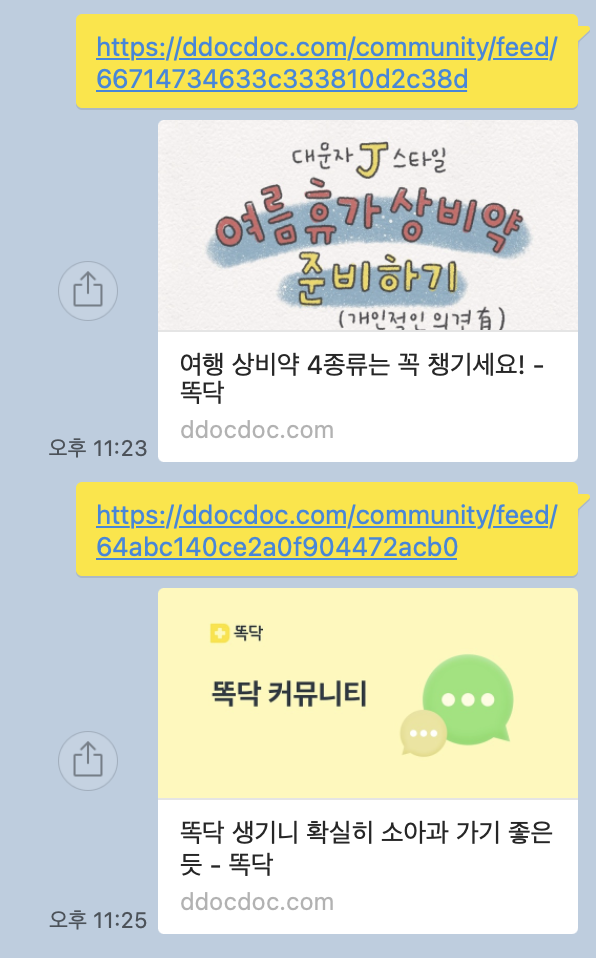
SNS에 자주 공유될 가능성이 있는 웹페이지라면, URL 미리보기가 정상적으로 표시되는지, 썸네일이나 설명이 잘리지 않는지 사전에 테스트해 보는 것이 좋습니다.
아래는 자주 사용되는 Meta 태그들을 정리했습니다.
// 검색 엔진 및 공유 시 표시될 페이지 설명
<meta name="description" content="This is a sample description.">
// 페이지의 문자 인코딩 설정
<meta charset="UTF-8">
// 브라우저 탭이나 북마크에 표시될 아이콘
<link rel="icon" href={파일경로} />
// 브라우저 툴바 색상
<meta name="theme-color" content="#000000">
// 검색 엔진 크롤러의 인덱싱 및 크롤링 제어
<meta name="robots" content="index, follow">
// SNS 공유 시 사용할 Open Graph 메타데이터
<meta property="og:title" content="My Website">
<meta property="og:description" content="A great website.">
<meta property="og:image" content="<https://example.com/image.png>">
<meta property="og:url" content="<https://example.com>">
아이폰의 Safari에서 웹페이지를 "홈 화면에 추가"하면 모바일 웹앱처럼 실행할 수 있습니다. 이를 지원하는 iOS 웹앱용 메타 태그를 활용하면 스플래시 이미지, 주소창 숨김, 상태바 색상 변경 등 다양한 설정이 가능합니다.
// 주소창 숨김 여부
<meta name="apple-mobile-web-app-capable" content="yes">
// 화면이 로딩될 때 노출할 스타트업 이미지
<meta name="apple-touch-startup-image" href="/startup.png">
// iOS 웹앱 이름
<meta name="apple-mobile-web-app-title" content="My Web App">
// iOS 상태바 색상
<meta name="apple-mobile-web-app-status-bar-style" content="#000000">
// 웹페이지 최상단 Smart App Banner 표시
<meta name="apple-itunes-app" content="app-id={App Store ID}">
구조화된 데이터(Schema.org)
구조화된 데이터는 검색 엔진이 웹페이지의 콘텐츠를 구체적으로 이해하고 효과적으로 활용할 수 있도록 돕는 데이터 형식입니다. 이를 적용하면 리치 검색 결과(Rich Results)를 통해 검색 결과 페이지(SERP)에서 일반 텍스트 링크보다 더 많은 정보를 제공할 수 있습니다.
리치 검색 결과란 검색 결과 페이지에서 페이지 타이틀과 설명뿐만 아니라 제품의 가격, 평점, 이벤트 날짜 등 추가적인 정보까지 함께 노출되는 것을 의미합니다. 이를 통해 사용자의 관심을 끌고 더 많은 클릭을 유도할 수 있습니다. 똑닥닷컴에서는 커뮤니티 피드에 Q&A 리치 결과를 적용하여 답변의 개수, 인기 답변까지 검색 결과에 노출되도록 했습니다.
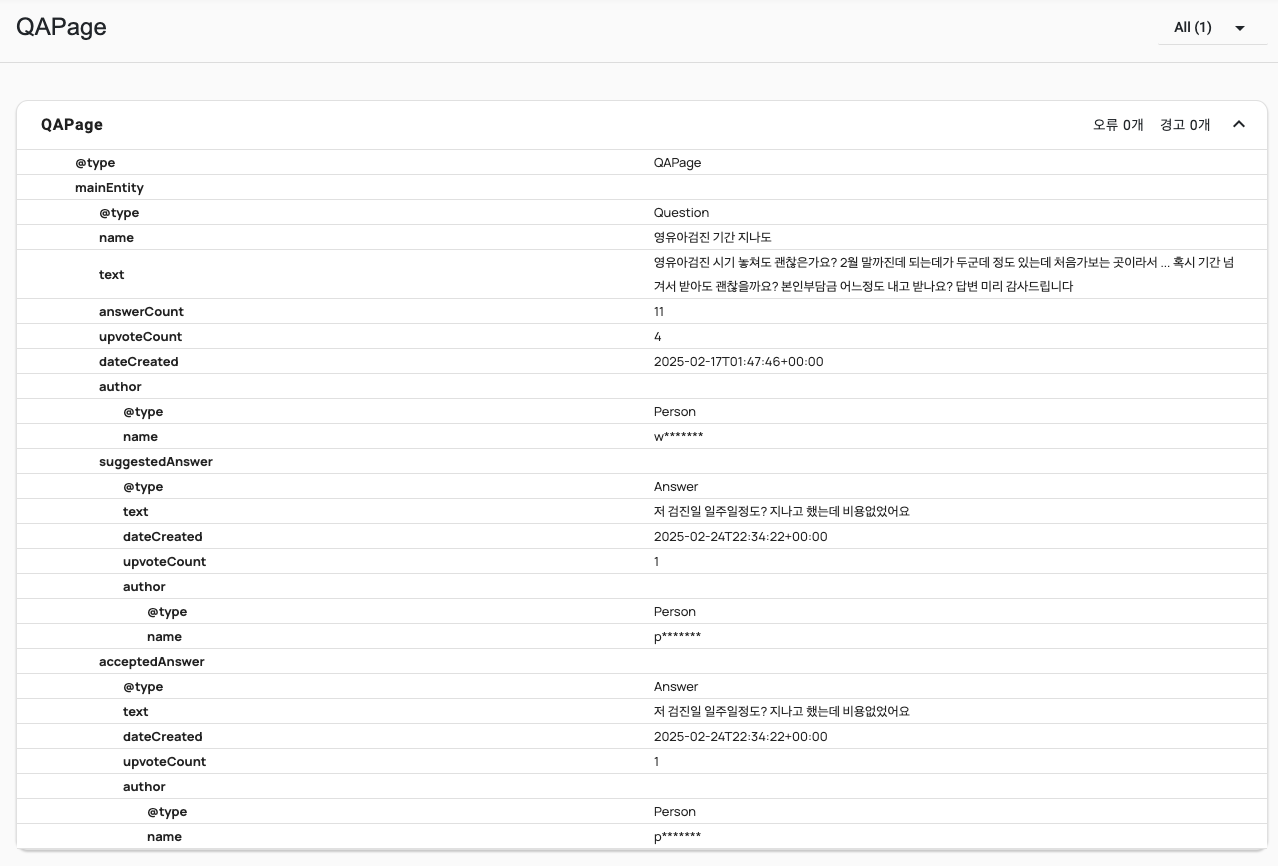
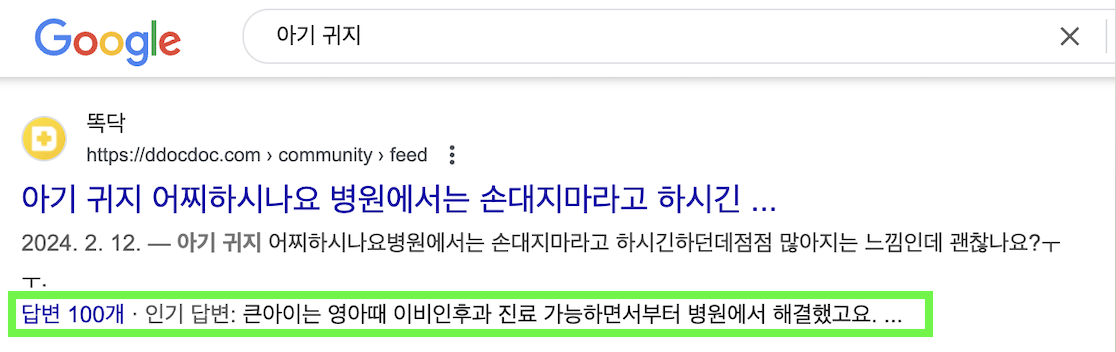
구글의 리치 검색 결과 테스트 도구와 Schema Markup Validator를 통해 구조화된 데이터를 테스트할 수 있으며, Schema.org에서 다양한 데이터 형식을 확인할 수 있습니다
favicon
favicon은 웹사이트를 대표하는 작은 아이콘으로, 브라우저 주소창이나 검색 결과에서 노출됩니다. 보통 <link> 태그를 사용해 설정합니다. 만약 아이콘을 설정하지 않은 상태로 검색 결과에 표시되더라도 네이버와 구글의 수동 크롤링 요청 기능을 통해 빠르게 반영할 수 있습니다.
<link rel="icon" href={파일경로}>
새로운 페이지들을 크롤링시키��자!
검색 엔진 최적화에서 중요한 요소 중 하나는 '페이지 색인 수'입니다. 검색 엔진이 내 웹사이트의 페이지를 인식하고 데이터베이스에 저장한 수가 늘어날수록 검색 결과에 내 페이지가 노출될 확률도 높아집니다.
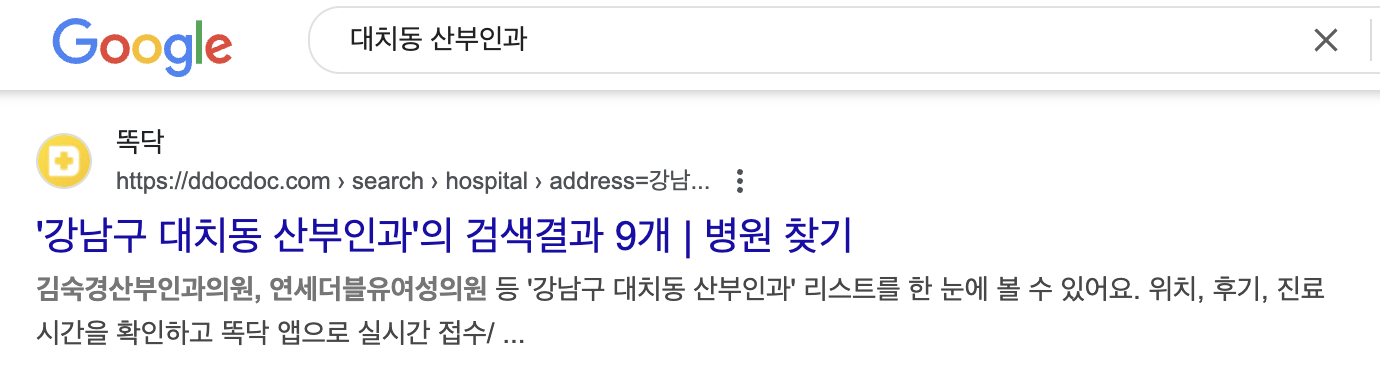
똑닥닷컴의 경우, 병원 검색 결과 페이지를 만들고 사이트맵(sitemap)에 [법정동] X [진료 과목] 조합으로 약 N만 개의 링크를 등록했습니다. 검색 엔진 크롤러가 사이트맵을 통해 법정동과 진료 과목을 결합한 검색 결과 페이지를 탐색하고 해당 페이지 내 수십 개의 병원 링크도 자동으로 수집할 것으로 예상했습니다. 실행 결과 네이버와 구글에서 페이지 색인 수를 약 30~50배가량 개선할 수 있었습니다.
매일 새로운 병원과 커뮤니티 글이 추가되는데, 이를 사람이 직접 하나하나 등록하는 것은 비효율적일 것입니다. 대신 검색 엔진 크롤러의 '링크를 따라가는' 특성을 활용한다면 색인 수를 효과적으로 늘릴 수 있습니다.
인기 키워드를 파악하자!
인기 있는 키워드를 파악하는 것은 SEO 전략의 중요한 부분입니다. 트래픽이 많은 키워드를 중심으로 페이지를 구성하면 자연스럽게 �더 많은 방문자를 유도할 수 있습니다. 구글 트렌드와 네이버 데이터랩 - 검색어 트렌드 같은 도구를 활용해 간편하게 키워드 검색량 데이터를 비교하고 분석할 수 있습니다.
번외) Next.js App Router SEO 트러블 슈팅
Next.js 14 버전에서 SEO 관련 문제를 해결한 경험을 정리했습니다.
1) 동적 sitemap.xml 설정 방법
Next.js에서는 기본적으로 sitemap.(xml|js|ts) 형태의 사이트맵(sitemap) 생성 방식을 제공합니다. generateSitemaps 함수를 사용하여 id 속성을 가진 객체의 배열을 반환하면 /.../sitemap/[id].xml 형식의 동적 sitemap을 생성할 수 있습니다. Next.js 14 버전에서는 Development 환경과 Production 환경에서 생성되는 URL 형식이 다르니 주의해야 합니다.
- Development 환경:
/sitemap.xml/[id] - Production 환경:
/sitemap/[id].xml
import type { MetadataRoute } from "next";
export async function generateSitemaps() {}
export default async function sitemap({ id }: { id: number }): Promise<MetadataRoute.Sitemap> {}
2) 동적 Metadata 생성 시 API 호출 최소화하는 법
Next.js에서는 generateMetadata 함수를 통해 동적인 메타 데이터를 설정할 수 있습니다.
async function fetchData() {
return fetch("https://api.example.com/data").then((res) => res.json());
}
export async function generateMetadata() {
const data = await fetchData();
return { title: data.title };
}
export default async function Page() {
const data = await fetchData();
return <div>{data.title}</div>;
}
Next.js 공식 문서에 따르면 generateMetadata, generateStaticParams, Layouts, Pages, Server Components 에서 발생하는 동일한 데이터에 대한 fetch 요청은 자동으로 메모이제이션됩니다. 하지만 fetch를 사용할 수 없는 경우에는 React의 cache를 활용할 수 있습니다. cache를 사용하면 동일한 파라미터로 호출된 데이터 호출 함수의 리턴값, 즉 데이터 스냅샷을 공유하여 중복 요청을 방지할 수 있습니다.
import { cache } from "react";
const fetchData = cache(async () => {
return fetch("https://api.example.com/data").then((res) => res.json());
});
export async function generateMetadata() {
const data = await fetchData();
return { title: data.title };
}
export default async function Page() {
const data = await fetchData();
return <div>{data.title}</div>;
}
3) 주요 Metadata Key 정리
Next.js에서는 정적 메타데이터 객체와 동적 메타데이터 생성 함수를 비롯해 다양한 Meta Data API를 제공합니다. 기존 HTML에서는 meta 태그를 직접 나열했지만, Next.js에서는 메타데이터를 객체 형태로 선언하기 때문에 어떤 속성을 어느 위치에 넣어야 하는지 파악해야 합니다.
예를 들어 canonical URL의 경우, 기존에는 link 태그를 사용했다면
<link rel="canonical" href="https://ddocdoc.com"/>
Next.js에서는 alternates 객체 내부에 canonical라는 key를 사용해 값을 설정해야 합니다
alternates: { canonical: "https://ddocdoc.com"'}
Next.js 공식 문서도 참고할 만하지만, Metadata 타입 정의에 구체적인 정보가 나와 있습니다. 아래는 자주 사용하는 메타데이터 설정 예시입니다.
import type { Metadata } from 'next'
export const metadata: Metadata = {
title: '...',
description: '...',
icons: {
icon: ['https://.../favicon.ico'],
shortcut: ['https://.../favicon.ico'],
apple: ['https://.../favicon.ico'],
},
/* 오픈 그래프 메타데이터 */
openGraph: {
type: 'website',
title: '...',
description: '...',
siteName: '...',
images: ['...'],
url: '...',
},
/* 문서의 canonical 및 alternate URL 설정 */
/* <link rel="canonical" href="https://example.com" /> */
/* <link rel="alternate" href="https://example.com/en-US" hreflang="en-US" /> */
alternates: {
canonical: "https://example.com",
hreflang: { "en-US": "https://example.com/en-US"
},
/* 타입에 정의되지않은 meta data 키/값 설정 */
other: {
viewport:'',
'apple-mobile-web-app-title': '',
},
}
마무리
SEO는 크롤링부터 트래픽이 쌓이기까지 시간이 소요되기 때문에 꾸준한 작업이 중요합니다.
소개된 방법들 외에도 검색엔진에 상위 노출되는 웹페이지들에 접속해 Sitemap과 Metadata, URL 설계를 어떻게 했는지 확인해 보거나, SNS에서 SEO 아티클을 작성하는 계정들을 팔로우하는 것도 도움이 되었습니다.
앞으로 똑닥닷컴에 건강과 관련된 다양한 콘텐츠도 추가될 예정이니 기대 부탁드립니다.
감사합니다.