똑쿼리 고도화 일대기

똑쿼리는 전사 데이터를 LLM을 통해 조회할 수 있는 서비스입니다. 여기서 전사 데이터는 단순한 데이터 웨어하우스의 수치를 넘어서, 프로젝트 문서, API 문서, 사내 규정까지 포괄하는 개념입니다. 이 글에서는 똑쿼리가 어떤 배경에서 탄생했고, LangGraph 도입과 함께 어떻게 고도화되었는지를 공유합니다.
들어가며
비바리퍼블리카, 배달의 민족, 당근 등 다양한 빅테크 기업에서는 사내 AI 를 이미 도입했고 이에 영향을 받기도 했습니다. 그럼에도 불구하고, 조직의 규모가 엄청 크지도 않은 비브로스라는 조직에 왜 사내 AI 가 필요했는가를 되짚어보았습니다.
비브로스는 그리 크지 않은 조직임에도, 우리가 운영하는 "똑닥"이라는 서비스는 MAU 100만 이상의 큰 서비스입니다. 여기서 파생되는 다양한 정책, 데이터가 있었고 이에 대한 조회 내지 설명을 위해 특정 개인 또는 집단에게 의존하곤 했습니다. 가령, "멤버십 유저 중 4세 미만 자녀 연동이 된 유저는 몇 명일까?" 같은 질문은 백엔드팀 또는 데이터 담당자에게 물어봐야 했습니다.
이것은 개인에게 컨텍스트 스위칭을 요구하며 업무 효율을 낮출 뿐 아니라, 이를 인지하는 구성원은 데이터가 궁금해도 쿼리에 대해 선뜻 물어보기 힘들었습니다. 데이터뿐만 아니라 정책, 사내 규정도 마찬��가지입니다. 그것을 잘 숙지하는 구성원에게 물어보곤 했고, 만약 그 구성원 부재 중이라면 답변을 기약 없이 기다려야 했습니다.
똑쿼리는 이런 배경에서 탄생하였습니다. 궁극적으로는, 회사 내 모든 구성원이 필요한 정보를 오랜 기다림 없이, AI와의 자연스러운 대화를 통해 즉시 확인할 수 있는 환경을 만드는 것이 목표입니다.
똑쿼리 개발기
시작점: 채팅 에이전트
똑쿼리는 단순한 데이터 질의응답 기능을 제공하는 것을 출발점으로 삼았습니다.
인터페이스는 사내 구성원 누구나 쉽게 접근할 수 있도록 슬랙으로 시작하였습니다. 사용자는 슬랙에서 똑쿼리 봇을 멘션하여 질문을 입력하면, 해당 요청이 서버로 전달되어 응답이 생성되는 방식입니다.
초기 똑쿼리 서버는 내부적으로 ChatAgent를 중심으로 답변을 결정하였습니다. ChatAgent 는 시스템 프롬프트 기반의 Chain-of-Thought(CoT) 추론을 통해 쿼리를 생성하고 실행하여 최종 답변을 생성하였습니다.
CoT(Chain of Thought)은 복잡한 문제를 단계적으로 사고하도록 유도하는 LLM 프롬프트 기법입니다. 즉, 모델이 곧바로 정답을 예측하는 대신, 중간 추�론 과정을 먼저 언어로 설명하도록 유도하는 방식입니다.
아래는 당시 사용했던 시스템 프롬프트의 일부입니다:
SYSTEM_PROMPT = """
Respond to the human as helpfully and accurately as possible. You have access to the following tools:
{tools}
...(중략)
Follow this format:
Question: input question to answer
Thought: consider previous and subsequent steps
Action:
```
$JSON_BLOB
```
Observation: action result
... (repeat Thought/Action/Observation N times)
Thought: I know what to respond
Action:
{{ "action": "Final Answer", "action_input": "Final response to human" }}
...(생략)
"""
이 형태의 구현은 "데이터 질의 응답"이라는 단일 테스크만을 수행하는 데는 충분했습니다.
더욱 복잡한 기능을 추가하기엔 한계가 있었지만, 당시엔 Langchain 생태계에 막 적응하던 시기였기에 복잡한 라이브러리 도입은 부담스러웠습니다.
하지만 이 구현 방식에는 다음과 같은 문제점이 있었습니다:
- 유지보수가 어려웠습니다. 모델이 정해진 포맷을 지키지 않으면 에러가 발생하거나, 체인이 한 번 더 실행되는 비효율이 생겼습니다.
- CoT 지시로 인해 프롬프트가 길어지면서, 토큰 낭비와 응답 속도 저하 문제가 발생했습니다. 프롬프트의 가독성 또한 떨어졌습니다.
- 다양한 에이전트들과 통합하려 했지만, 확장성이 부족해 유연한 스케일 확장이 어려웠습니다.
이러한 한계를 구조적으로 해결하고, 더 복잡한 기능을 체계적으로 다룰 수 있도록 저희는 LangGraph를 도입하게 되었습니다.
랭그래프 도입
랭그래프란
랭그래프(LangGraph)는 상태 기반(stateful)의 LLM 워크플로우를 구성할 수 있게 도와주는 프레임워크입니다. 공식 문서에서는 랭그래프의 특징을 아래와 같이 설명하고 있습니다:
신뢰성과 제어 가능성
에이전트의 행동을 모더레이션 검사와 인간의 승인 절차를 통해 제어할 수 있습니다. LangGraph는 장기 실행 워크플로우의 컨텍스트를 지속적으로 유지하여, 에이전트가 올바른 경로를 따르도록 돕습니다.
저수준 접근과 확장성
제약이 많은 추상화 없이, 완전하게 설명 가능한 저수준 프리미티브로 사용자 정의 에이전트를 구축할 수 있습니다. 각 에이전트가 특정 역할을 수행하도록 설계하여, 사용 사례에 최적화된 확장 가능한 멀티 에이전트 시스템을 설계할 수 있습니다.
일급 스트리밍 지원
토큰 단위의 스트리밍과 중간 단계의 실시간 스트리밍을 통해, LangGraph는 사용자가 에이전트의 추론 과정과 행동을 실시간으로 명확하게 파악할 수 있도록 도와줍니다.
쉽게 생각하면, 서버를 구성할 때 사용하는 if/else나 for/while 같은 제어 구조를 Langchain 환경에서도 명시적으로 구성할 수 있도록 해주는 프레임워크입니다. 복잡한 프롬프트로 모델에게 일일이 로직을 맡기기보다는, 애플리케이션 코드 수준에서 제어권을 직접 쥘 수 있도록 해줍니다.
랭그래프는 세 가지 요소로 이루어집니다.
State (상태)
State는 애플리케이션의 현재 상태를 담고 있는 공유 데이터 구조입니다. Python의 모든 타입을 사용할 수 있으나, 주로
TypedDict나Pydantic BaseModel을 활용합니다.Node (노드)
Node는 에이전트의 로직이 구현된 Python 함수입니다. 현재 상태(State)를 입력받아 필요한 연산이나 부수 효과를 수행하고, 갱신된 상태를 반환합니다.
Edge (엣지)
Edge는 현재 상태(State)를 기반으로 다음 실행할 Node를 결정하는 Python 함수입니다. 조건에 따른 분기나 미리 정의된 전이 규칙을 포함할 수 있습니다.
즉, LangGraph는 데이터의 흐름(State), 실행의 주체(Node), 실행의 경로(Edge)를 분리해, 복잡한 에이전트 시스템도 구조적으로 명확하고 유연하게 ��구성할 수 있도록 도와줍니다.
아래 그림은 랭그래프의 간단한 예시입니다.
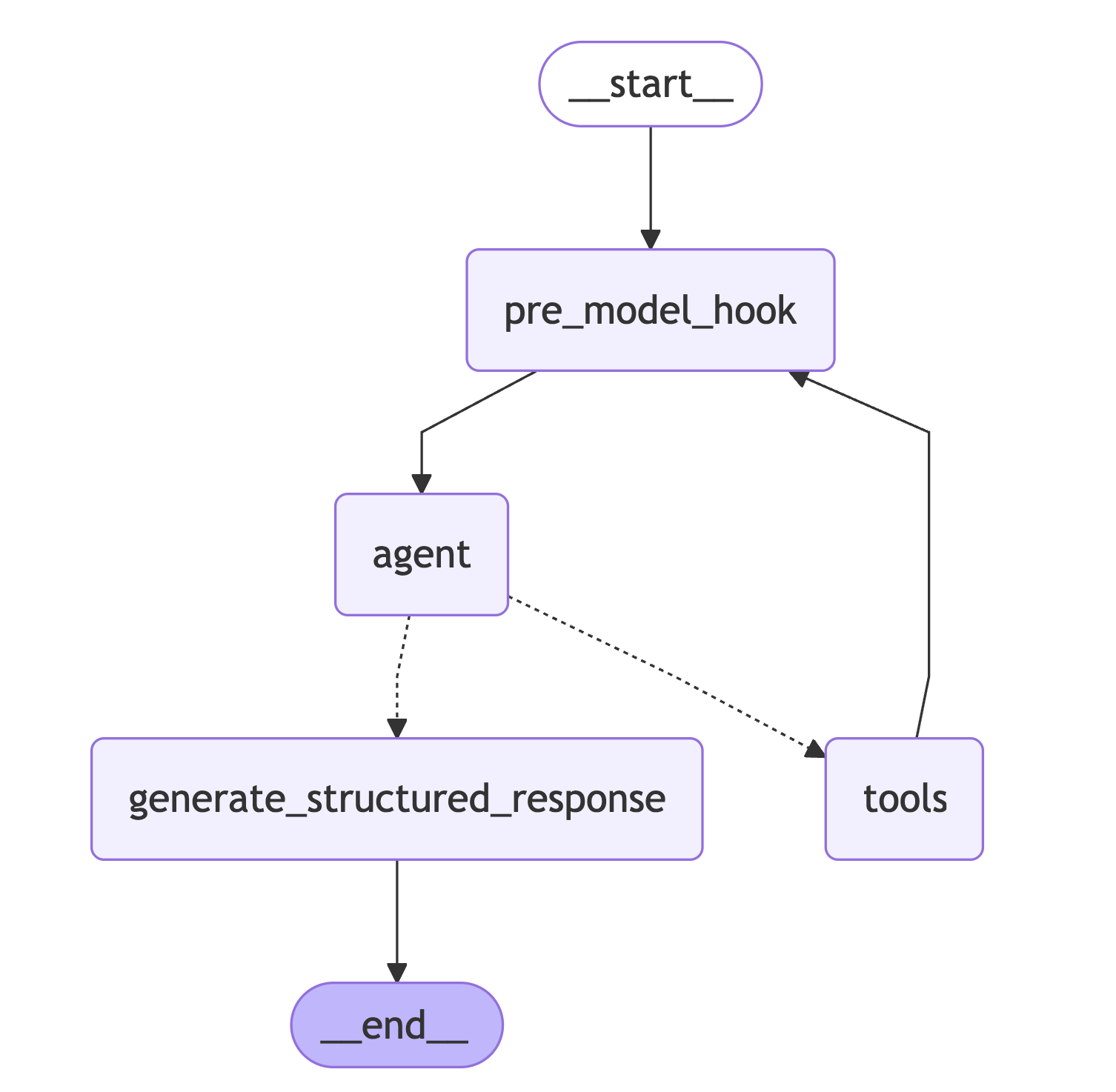
예를 들어, 유저가 "멤버십 구독 정책 알려줘" 라고 요청을 보내면, 워크플로우는 __start__ 에서 시작됩니다. 초기 State 는 다음과 같이 구성됩니다.
{
"messages": [{ "role": "user", "content": "멤��버십 구독 정책 알려줘" }],
"today": "2025-06-19 15:00:00",
"thread_id": "%THREAD_ID%"
}
초기 상태는 먼저 pre_model_hook 을 거쳐 agent 로 전달됩니다.
agent 에서는 사내 문서를 탐색이 필요하다고 판단을 내리고, 데이터를 수집하기 위해 tools 로 이동합니다.
tools 는 데이터베이스에서 관련 문서를 탐색한 뒤, 그 결과를 State에 추가하고 다시 pre_model_hook 으로 흐름을 돌려보냅니다.
{
"messages": [
{ "role": "tool", "content": "멤버십 정책 설명: 블라블라" },
{ "role": "user", "content": "멤버십 구독 정책 알려줘" }
],
"today": "2025-06-19 15:00:00",
"thread_id": "%THREAD_ID%"
}
이후 pre_model_hook은 갱신된 상태를 다시 agent 에 전달합니다.
agent는 메시지를 기반으로 더 정보를 탐색할지, 혹은 결론을 도출할지를 판단합니다.
결론을 도출할 수 있다고 판단되면, 응답 생성을 위해 generate_structured_response 로 이동합니다. 이 노드에서는 최종 답변을 JSON 형태로 구성하고, 이를 마친 후 __end__ 노드로 전달하여 워크플로우를 종료합니다.
이처럼 LangGraph는 상태 기반의 흐름 제어를 통해 요청의 입력부터 응답 생성까지의 전 과정을 명시적이고 구조적으로 관리할 수 있도록 돕습니다.
랭그래프 구조
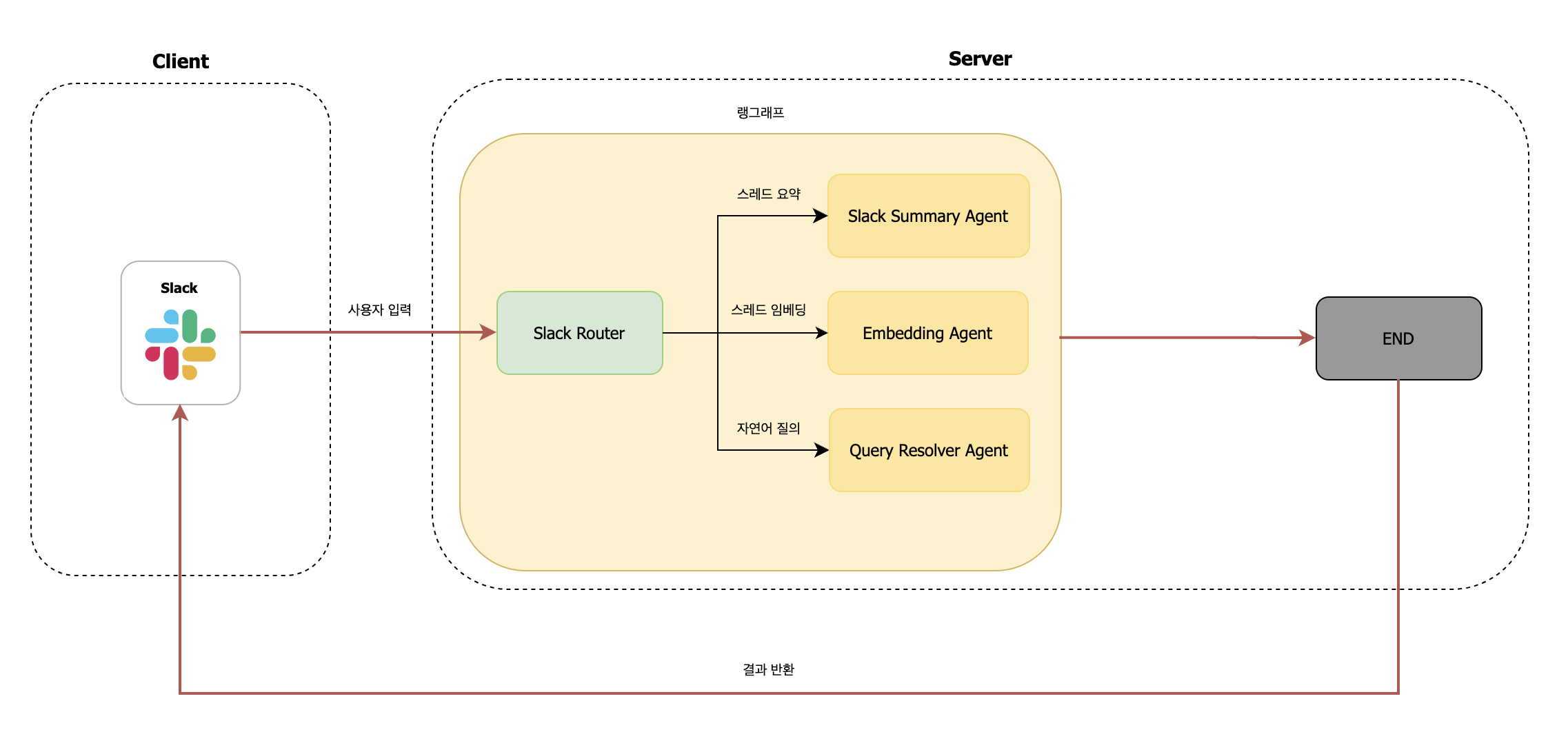
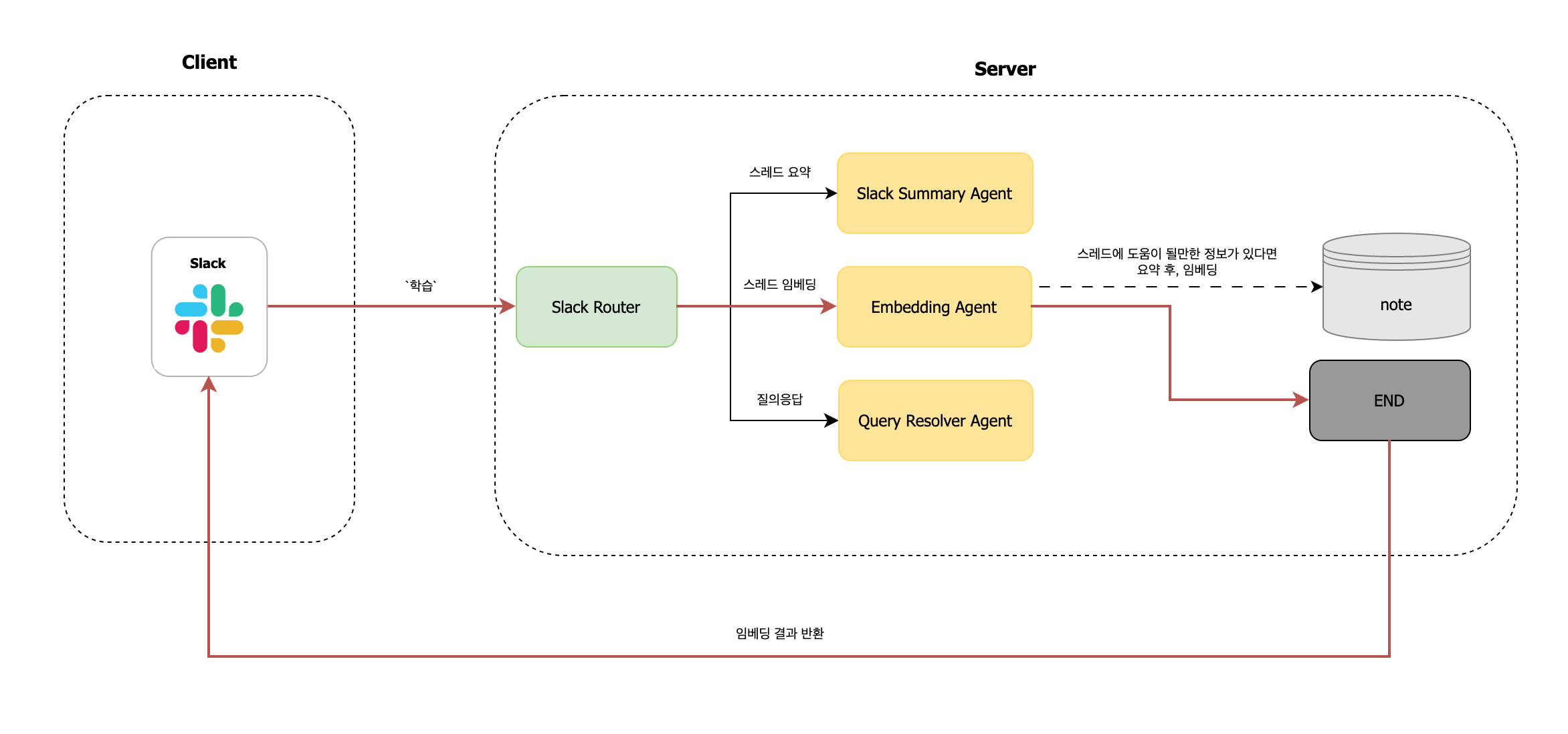
초기에는 단순한 질의응답에 초점을 맞췄지만, 사용자 니즈와 활용도가 높아지면서 저희는 똑쿼리 기능을 다음과 같이 세 가지 영역으로 확장하였습니다:
- 슬랙 스��레드 내용을 요약하여, 긴 대화를 빠르게 파악할 수 있는 기능
- 슬랙 스레드를 벡터화하여 검색에 활용할 수 있는 기능
- 사내 데이터(데이터 웨어하우스, 스키마, 문서, 정책 등)를 기반으로 한 자연어 질의응답 기능
이러한 기능들은 모두 슬랙봇을 멘션한 사용자 요청을 분석하여, 어떤 기능을 수행할지 결정하는 Slack Router를 통해 자동으로 분기 처리됩니다.
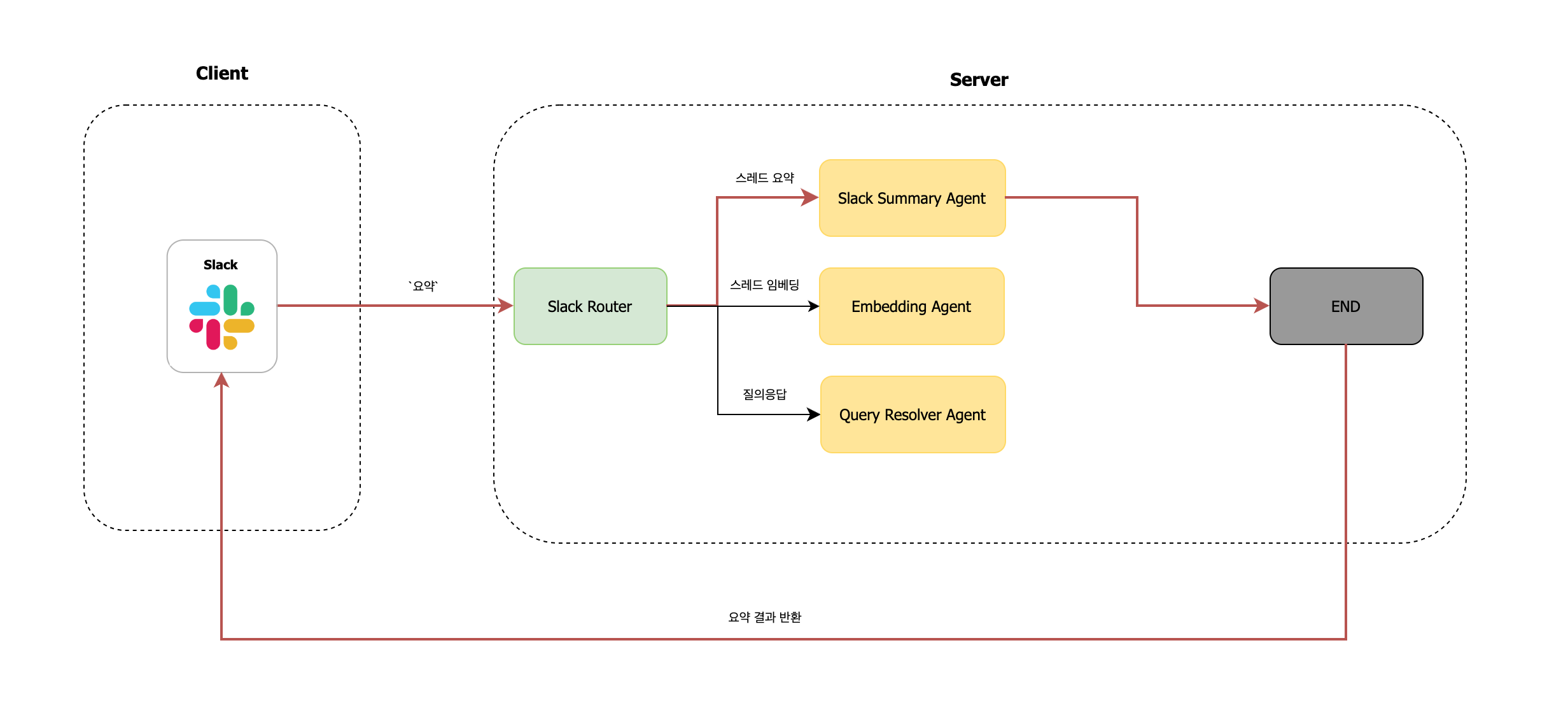
(1) 슬랙 스레드 요약
스레드에서 나눈 대화 내용을 LLM을 통해 요약하는 기능입니다. 슬랙 내 스레드는 길어지면 전체 맥락을 파악하기 어려운 경우가 많기 때문에, 요약 기능은 빠른 의사결정과 협업에 도움을 줍니다.
사용자가 "요약"이라는 키워드를 포함해 멘션하면, Slack Router는 이를 감지하고 고정된 흐름으로 Slack Summary Agent 노드로 분기합니다. 이 노드는 해당 스레드의 모든 메시지를 조회한 뒤, 요약에 적합한 형식(예: 핵심 발언, 주요 결정 사항 등)으로 정리하여 전달합니다.
(2) 슬랙 스레드 임베딩
스레드에서 나눈 대화 내용을 요약해서 벡터DB에 임베딩하는 기능입니다. Confluence 등 공식 문서에는 기록되지 않았지만, 실무 대화에서 의미 있는 정보가 오가는 경우가 많아 이를 벡터화하여 검색에 활용할 수 있도록 만든 기능입니다.
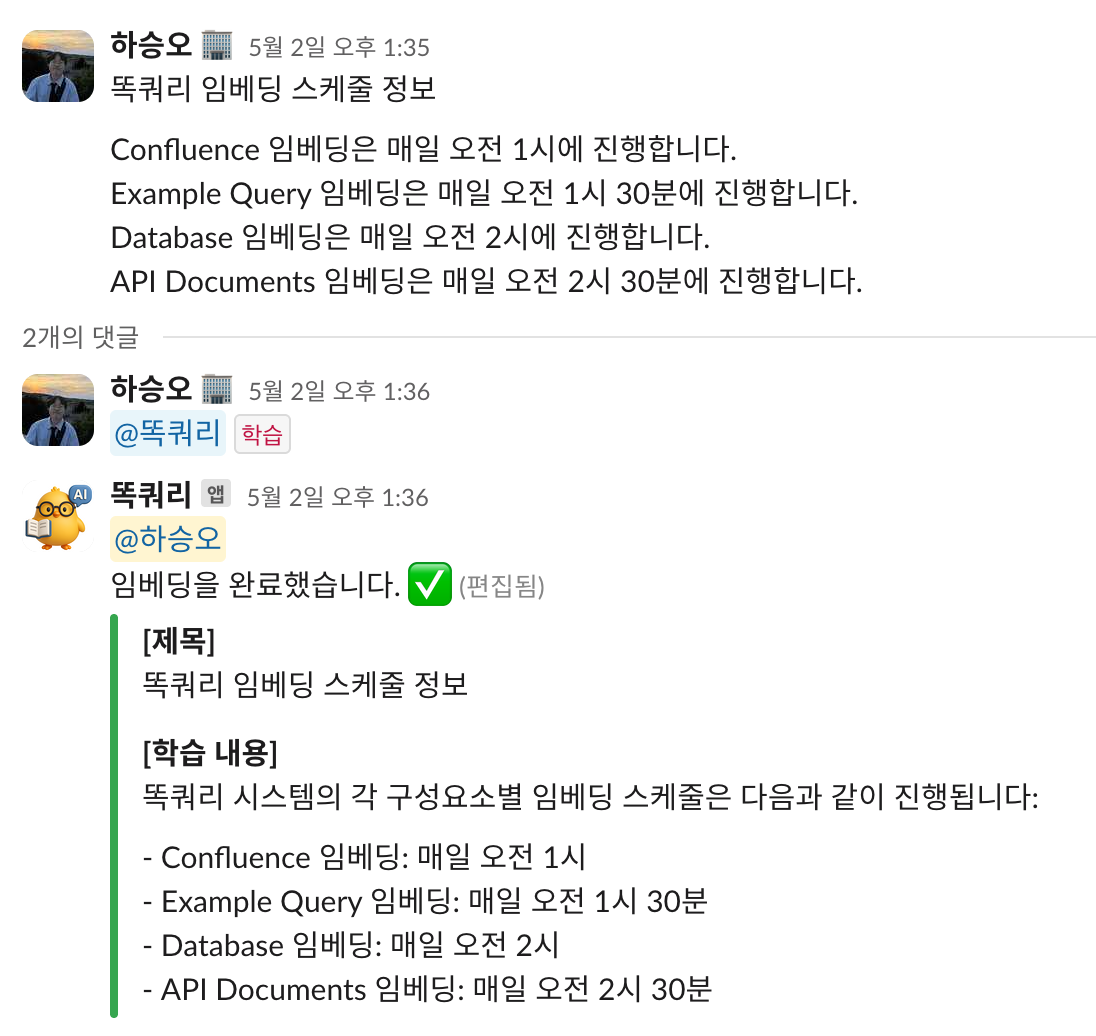
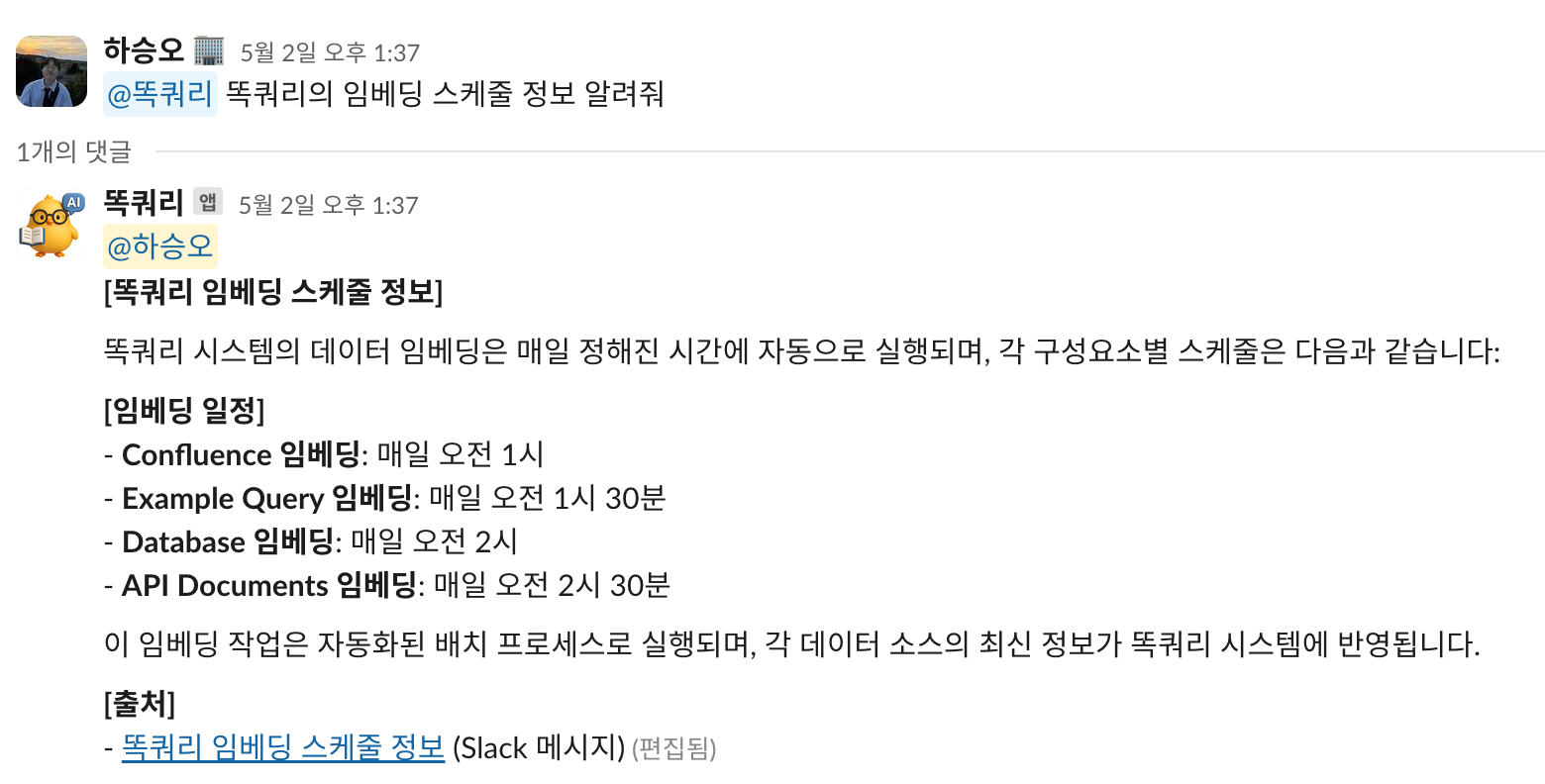
사용자가 "학습"이라는 키워드를 포함해 슬랙봇을 멘션하면, Slack Router는 해당 요청을 감지하여 Embedding Agent 노드로 워크플로우를 전환합니다.
이 노드는 해당 스레드의 모든 메시지를 조회한 뒤, 학습할만한 가치가 있는 내용이 있을 경우 요약 후 벡터화하여 저장합니다. 의미 있는 정보가 없다고 판단되면, 임베딩을 수행하지 않고 요청을 종료합니다.
(3) 사내 데이터를 기반으로 한 자연어 질의응답
슬랙봇을 통해 사내 데이터를 조회할 수 있는 기능입니다.
예를 들어 "어제 가입한 유저가 몇 명인지", "멤버십 무상 지원 정책은 무엇인지", "복지비는 어떻게 신청하는지"와 같은 질문을 자연어로 입력하면 응답을 받을 수 있습니다.
Slack Router 관점에서는, 요약 또는 임베딩과 같은 명시적 키워드가 없는 모든 요청은 일반 질의로 분류되어 Query Resolver Agent 노드로 전달됩니다.
이 기능은 LangGraph 기반으로 다시 구성되어, 복잡�한 판단과 흐름을 유연하게 처리합니다.
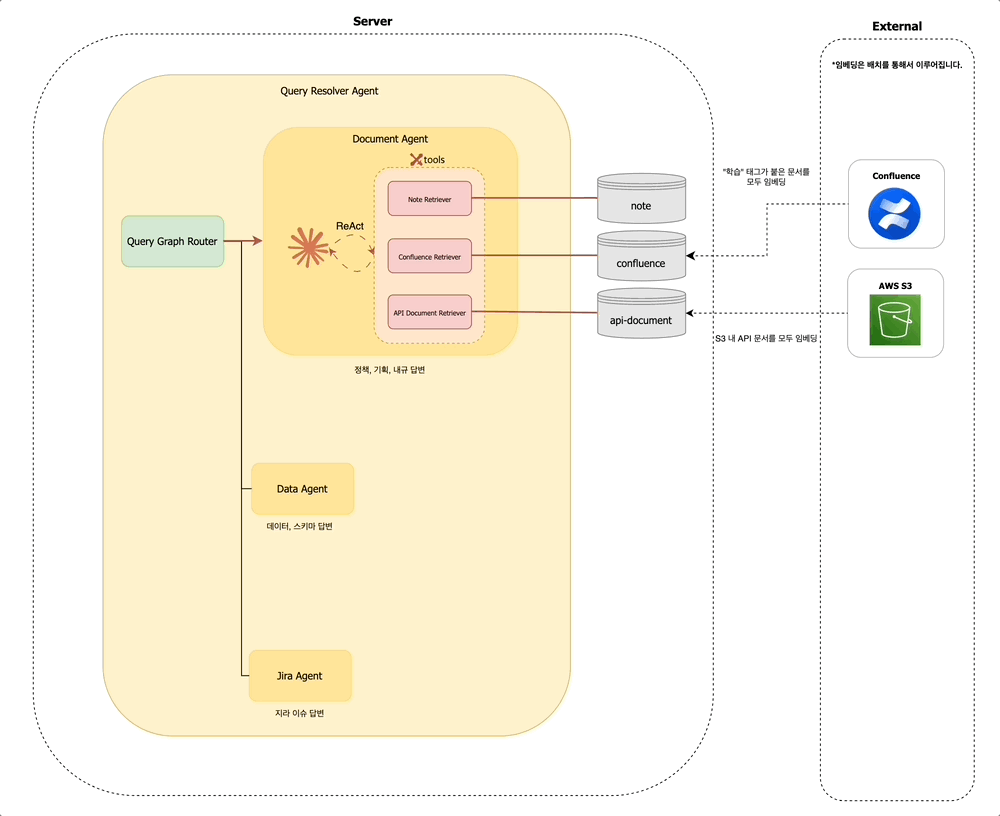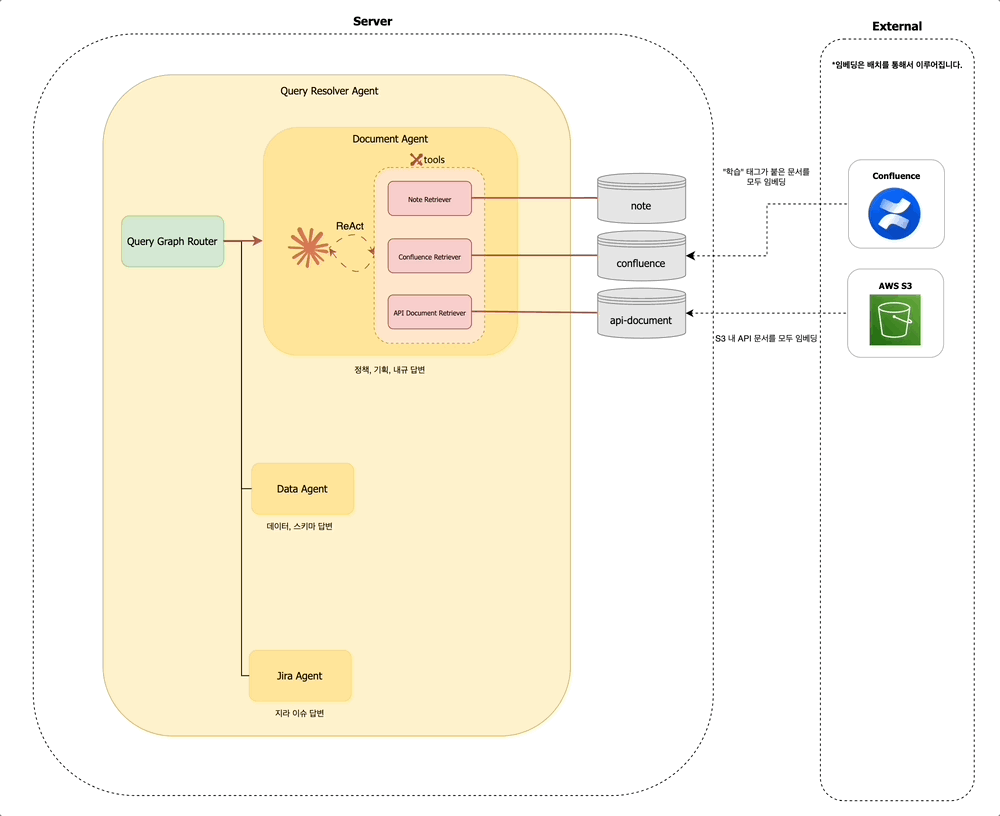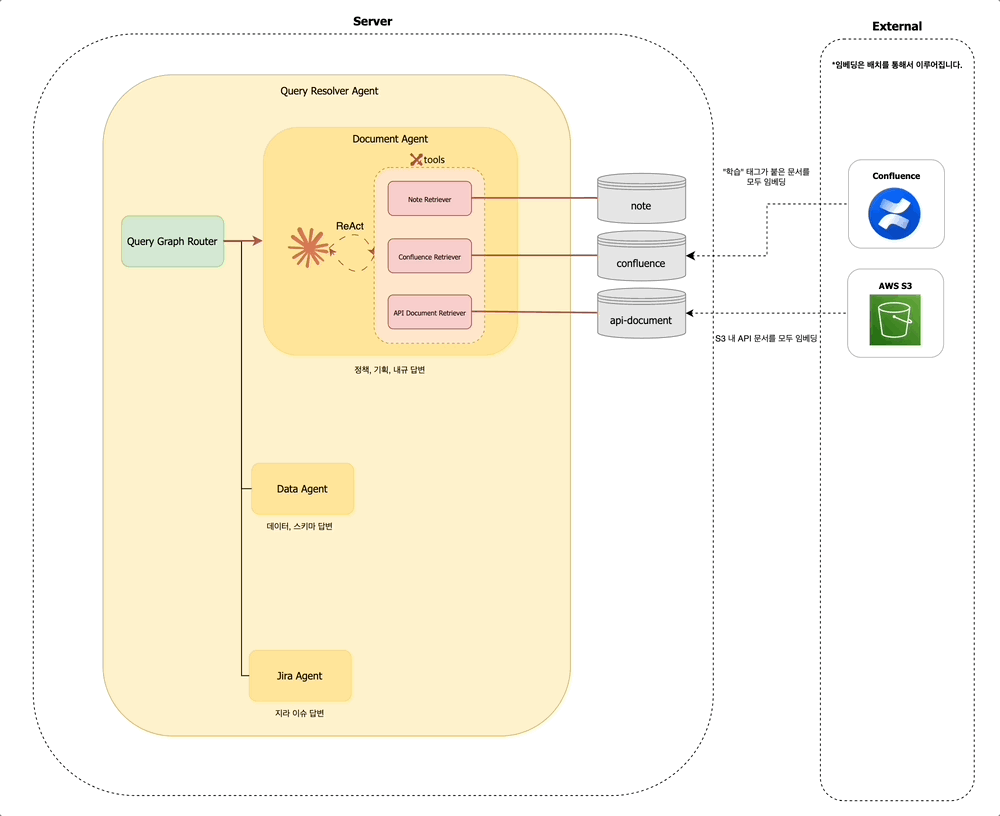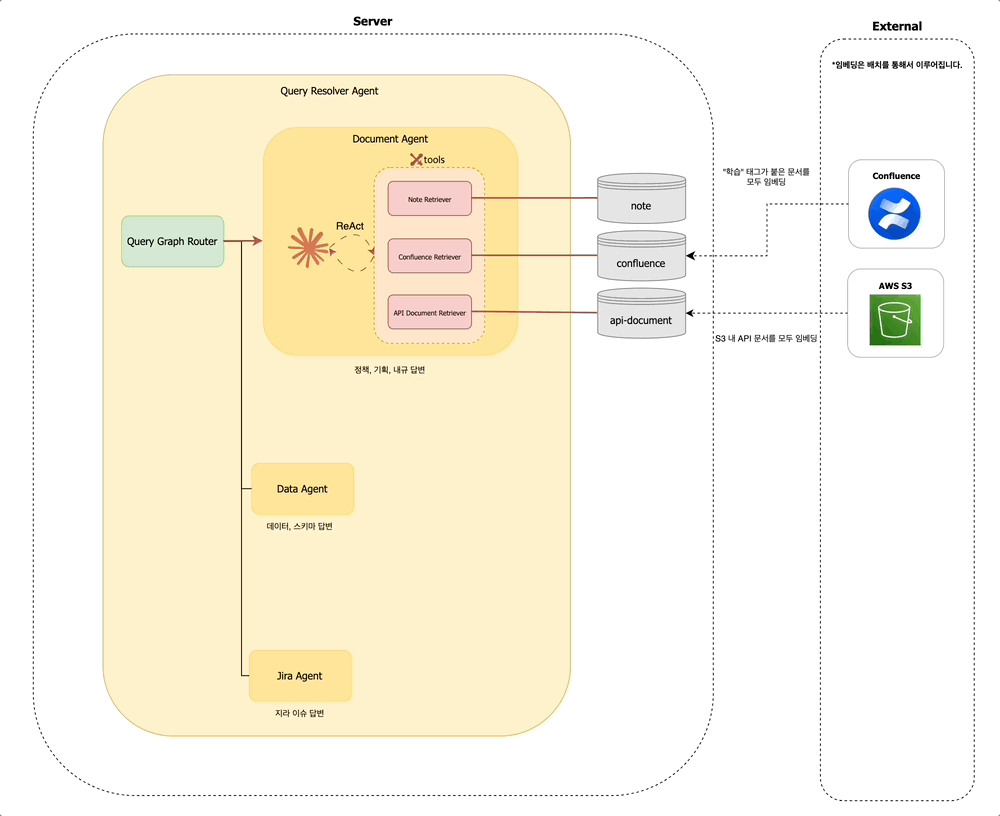
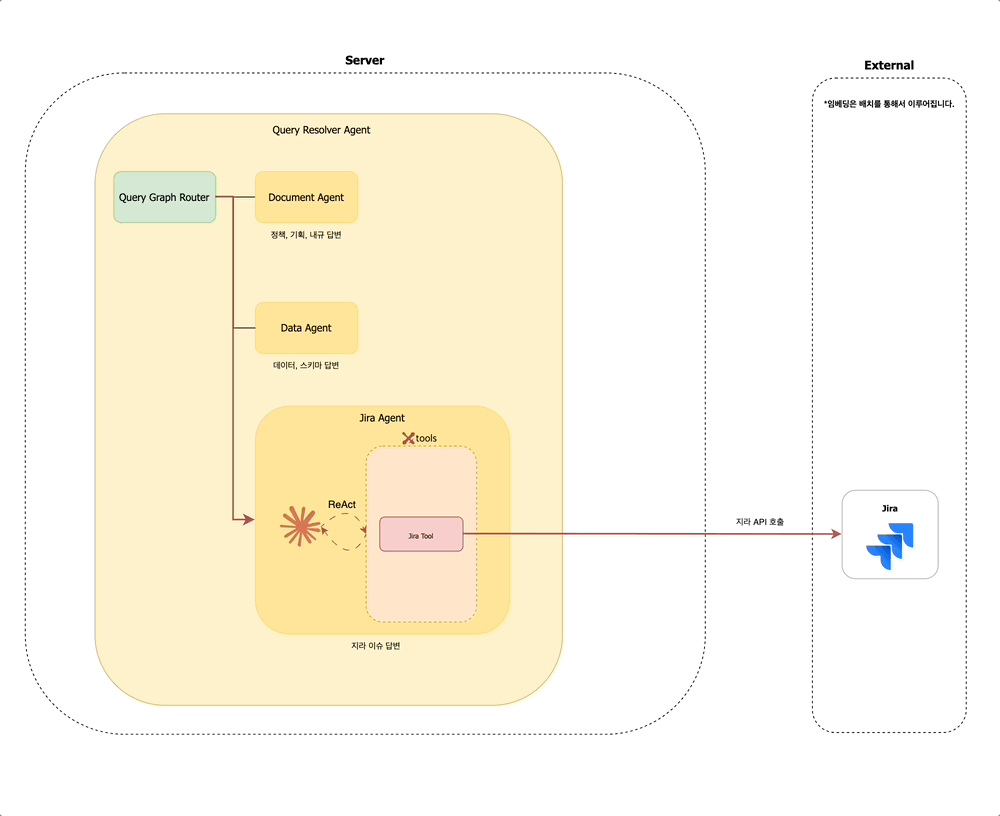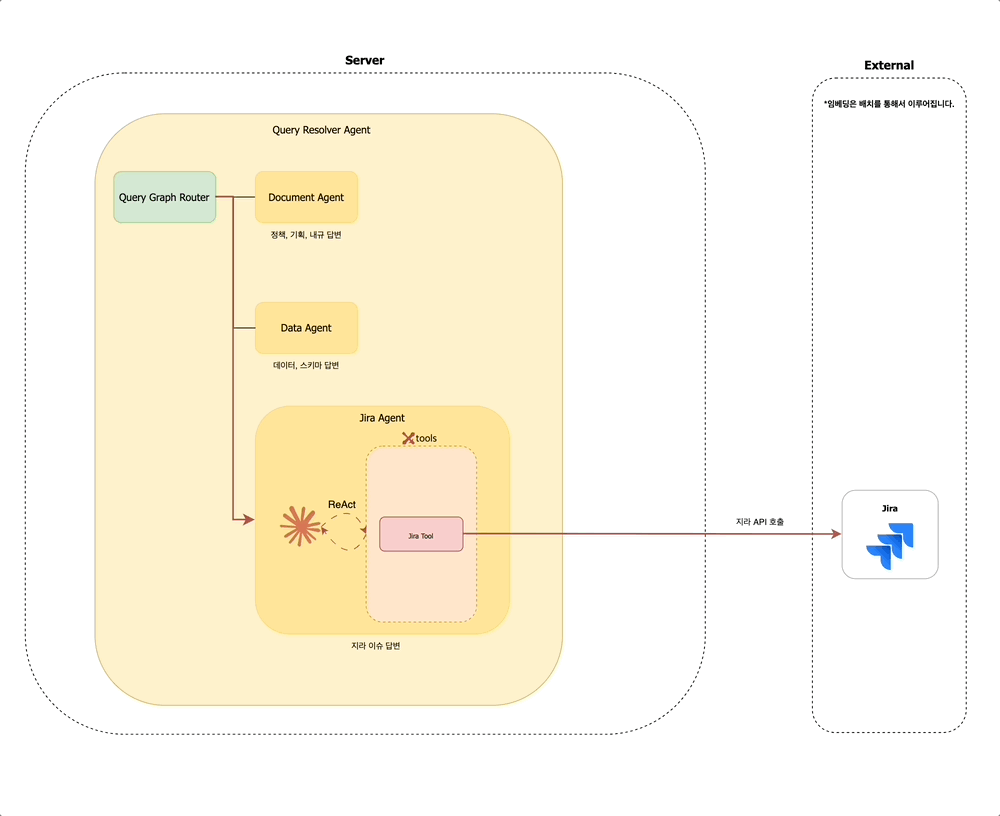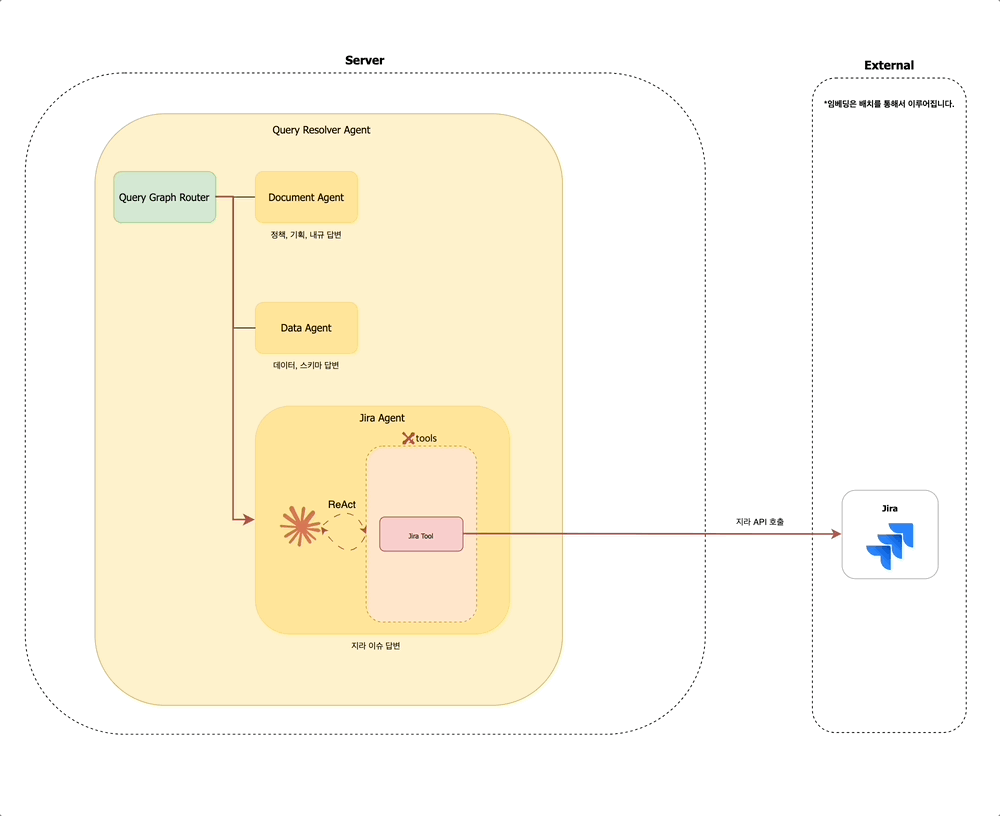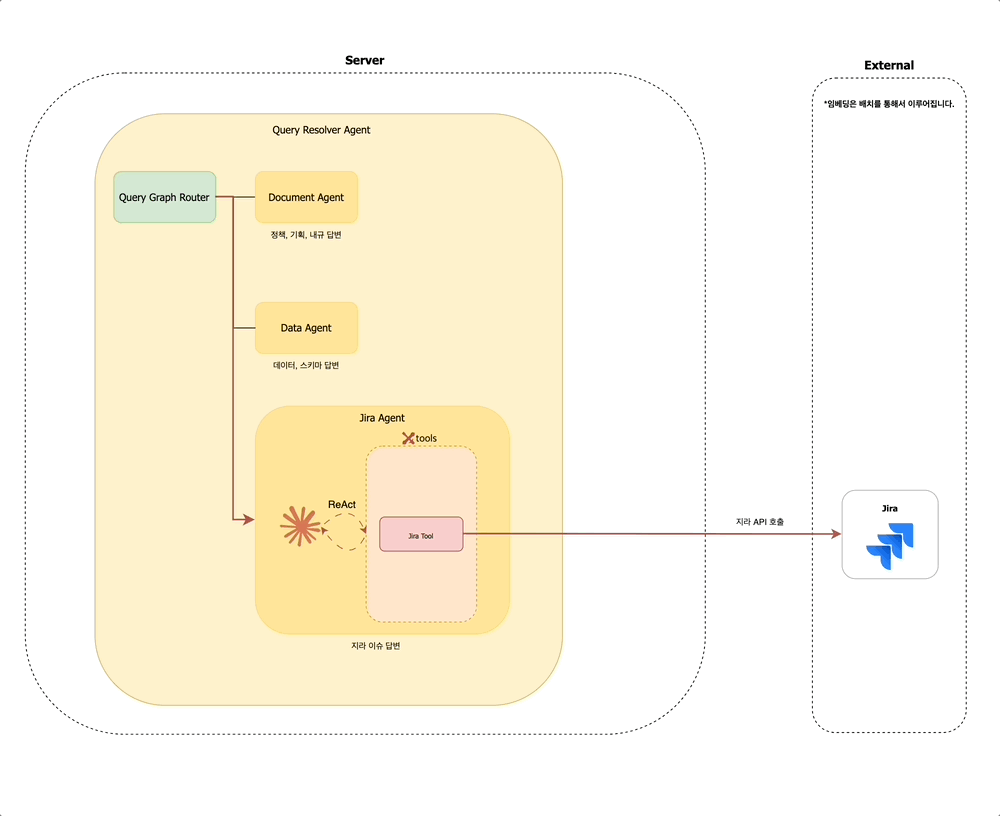
Query Resolver Agent 내에서는 먼저 Query Graph Router가 동작하여, 해당 질문이 어떤 유형인지 판단합니다. 문서 탐색이 필요한지 / 데이터 조회가 필요한지 / 지라 티켓을 확인해야 하는지를 경량 LLM을 통해 분석합니다. 예를 들어 사용자가 "멤버십 정책 알려줘"라고 입력하면, Query Graph Router는 해당 질문이 문서 탐색에 해당한다고 판단하여 Document Agent 노드로 분기합니다.
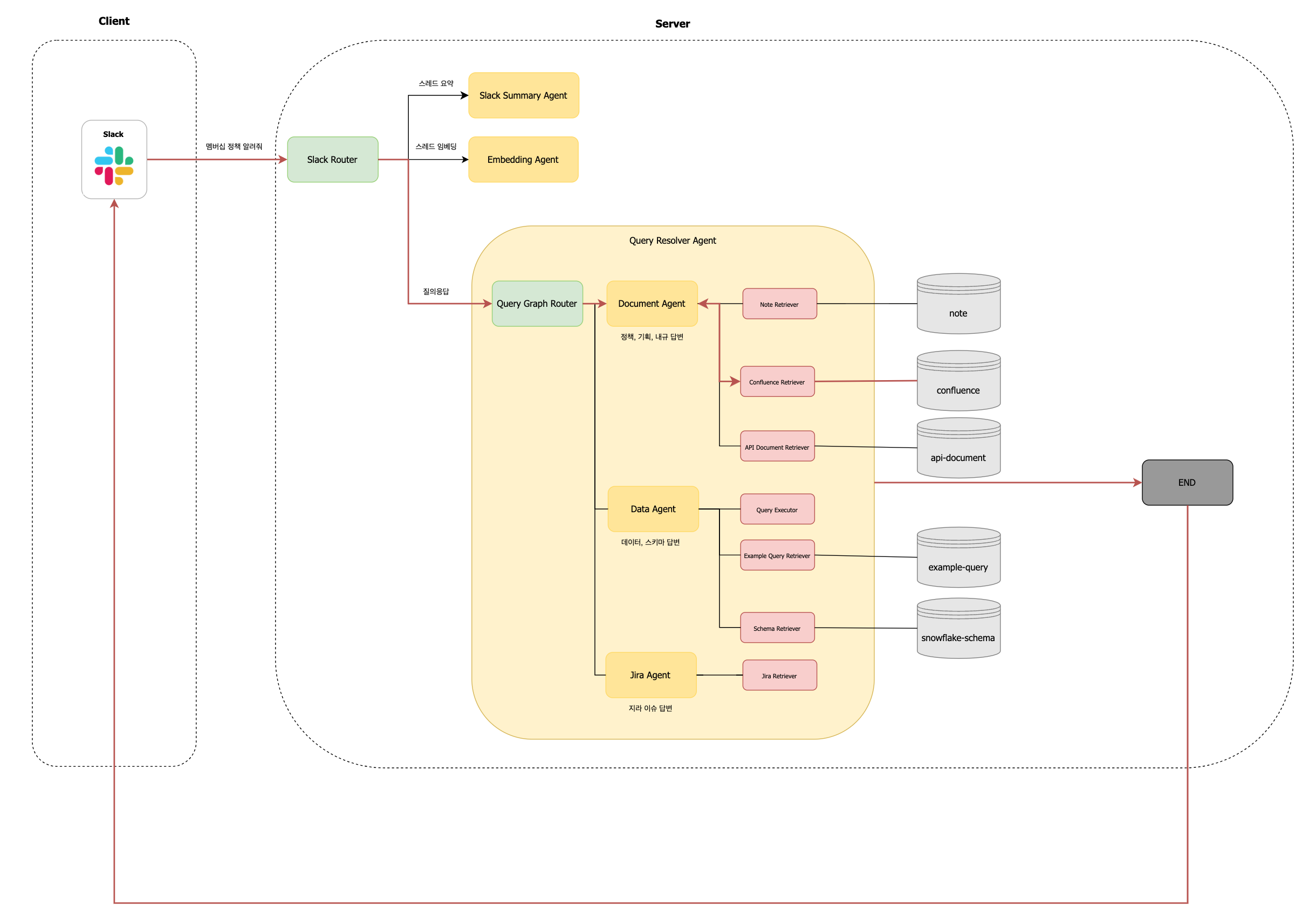
Query Graph Router 하위의 각 에이전트 노드는 langgraph.prebuilt 의 create_react_agent 함수를 통해 생성됩니다.
from langgraph.prebuilt import create_react_agent
document_agent = create_react_agent(
model=claude,
prompt=RETRIEVE_DOCUMENT_PROMPT,
tools=[confluence_retriever_tool, notes_retriever_tool, api_documents_retriever_tool],
name="document_agent",
)
이 에이전트는 주어진 도구를 기반으로 문서를 검색하고, 응답 생성을 위한 추론을 수행합니다.
이러한 방식은 Reasoning and Acting (ReAct) 구조로 불리며, 기존에 프롬프트 기반으로 수행하던 Chain-of-Thought 추론에 비해 더 구조적이고 간결한 추론 흐름을 제공합니다.
에이전트 구성
사내 구성원의 다양한 질문 유형을 처리하기 위해, Query Resolver Agent는 다음과 같은 세 가지 하위 에이전트로 구성되어 있습니다:
- 문서 에이전트 (
Document Agent): Confluence, 정책 PDF 문서, 내부 API 문서 등에서 정보를 검색하고 요약합니다. - 데이터 에이전트 (
Data Agent): 데이터 웨어하우스, 테이블 스키마, 비즈니스 메트릭에 대한 질의를 처리합니다. - 지라 에이전트 (
Jira Agent): 지라 티켓을 조회하거나 특정 이슈의 상태, 담당자 등을 확인합니다.
문서 에이전트 (Document Agent)
문서 에이전트는 사내 문서 데이터를 기반으로 유저의 질문에 답변하는 역할을 합니다.
문서 데이터는 다양한 형태로 존재합니다. 예를 들어, 비브로스에서는 문서 협업 도구인 Confluence, Slack에서 나눈 대화, 그리고 API 명세가 담긴 OpenAPI yaml 파일 등이 활용됩니다.
이 에이전트는 다음과 같은 과정을 통해 답변을 생성합니다:
- 질문을 분석하여 어떤 정보가 필요한지 추론합니다.
- 필요한 정보를 조회하기 위해 도구로 제공된 Retriever를 호출합니다.
- Retriever는 Vector Search 또는 FullText Search를 통해 적절한 정보를 수집합니다.
- 수집한 정보를 기반으로, 답변 가능 여부를 판단합니다.
- 작성이 가능하다고 판단되면 즉시 응답을 생성하며, 수집된 정보가 부족하다면 Retriever를 재호출합니다.
- 최종적으로 구성된 답변을 반환합니다.
Retriever는 다음과 같은 VectorDB를 조회합니다:
note: Slack에서 사용자가 수동으로 임베딩한 내용을 저장합니다.confluence: Confluence에서학습이라는 라벨이 달린 문서를 주기적으로 수집하여 배치 임베딩합니다.api-document: AWS S3에 저장된 OpenAPI (*.yaml) 문서를 API 경로 단위로 분할한 후 임베딩합니다. 이 역시 배치 작업을 통해 주기적으로 수행됩니다.
데이터 에이전트 (Data Agent)
데이터 에이전트는 데이터 웨어하우스의 스키마 정보를 기반으로, 적절한 쿼리를 작성하고 실행하여 유저의 질문에 응답하는 역할을 합니다.
이 에이전트는 다음과 같은 절차로 응답을 생성합니다:
- 질문을 분석하여 필요한 스키마 정보를 추론합니다.
- 관련 정보를 수집합니다.
Schema Retriever를 호출해 스키마 정보를 조회합니다.Example Query Retriever를 호출해 관련 예시 쿼리를 수집합니다.
- 수집한 정보를 바탕으로 쿼리 작성 가능 여부를 판단합니다.
- 작성이 가능하면 쿼리를 생성하고, 부족할 경우 Retriever를 다시 호출해 정보를 보완합니다.
- 작성한 쿼리를
Query Executor를 통해 실행합니다. - 실행 결과를 바탕으로 답변을 생성합니다. 쿼리 실행이 실패하면, 추론을 통해 쿼리를 수정하고 재실행을 시도합니다.
- 최종적으로 구성된 답변을 반환합니다.
에이전트가 조회하는 임베딩 벡터는 다음과 같이 구성됩니다:
snowflake-schema: Snowflake에서 추출한 스키마 정보를 임베딩합니다. 각 스키마에 대한 예시 데이터는 메타데이터로 함께 저장됩니다.example-query: 사전 등록된 예시 쿼리를 임베딩하여, 유사한 질문에 대한 힌트를 제공합니다.
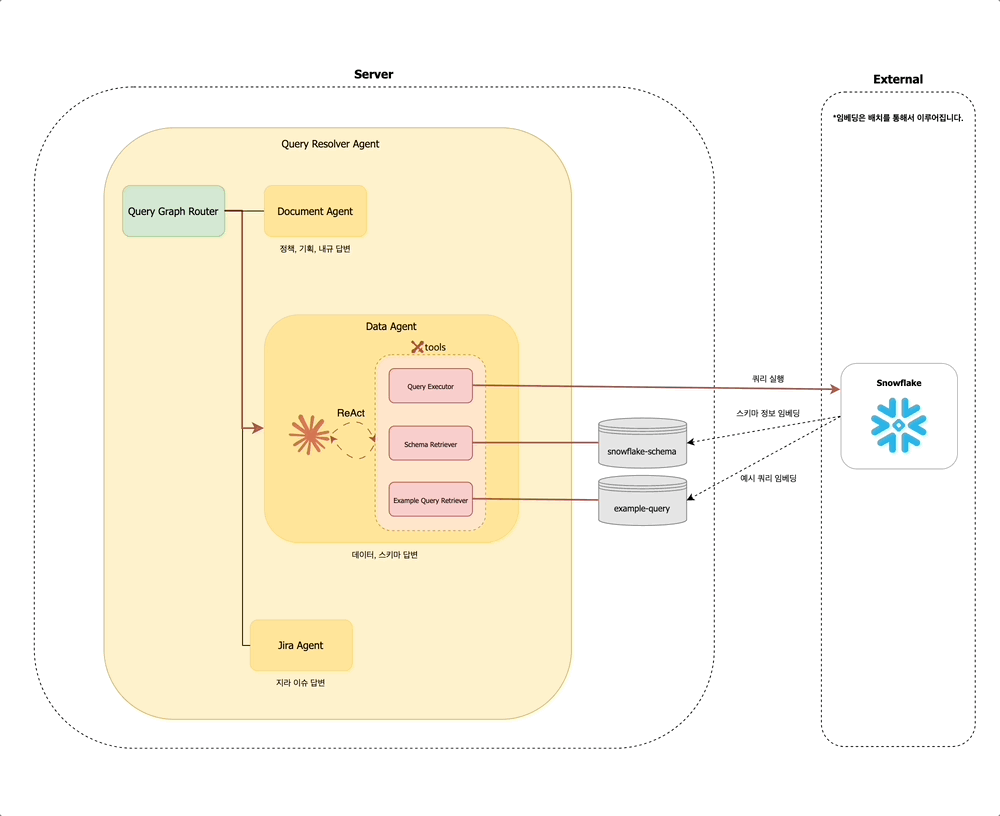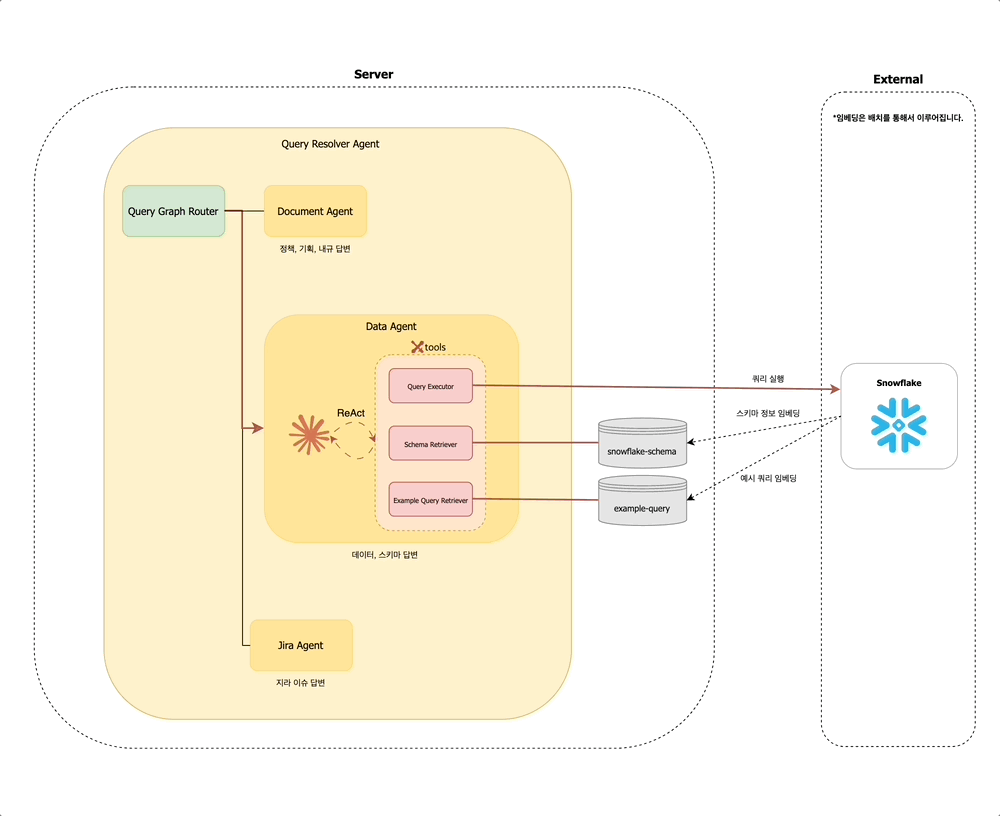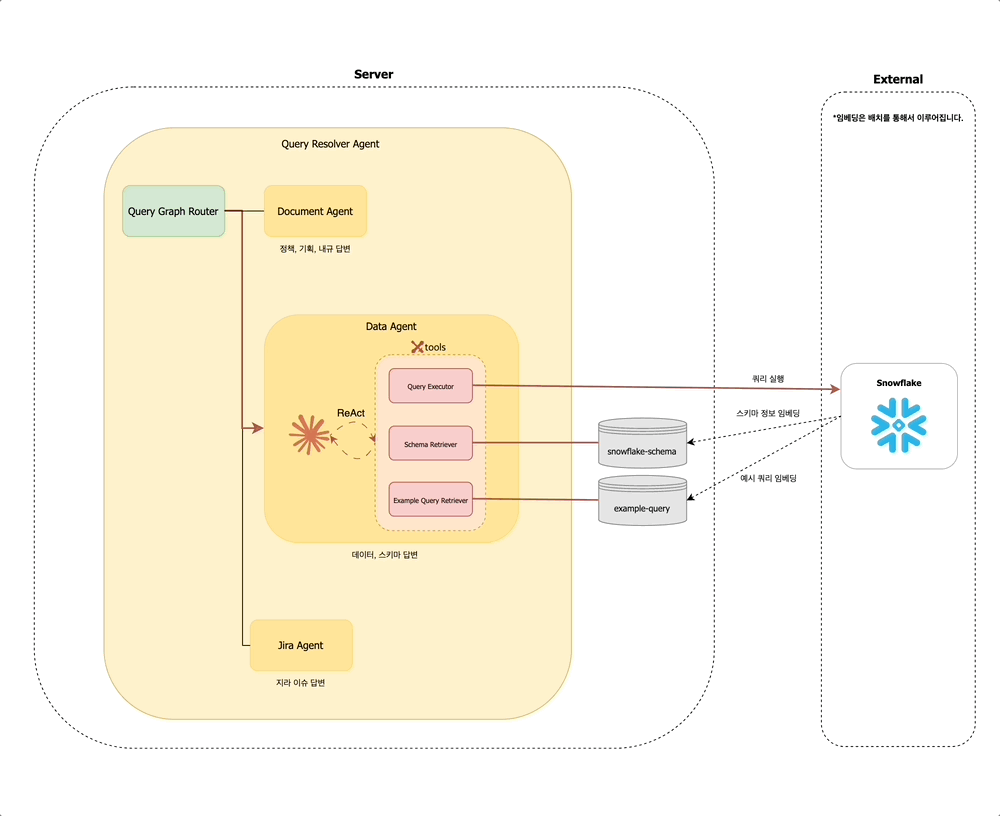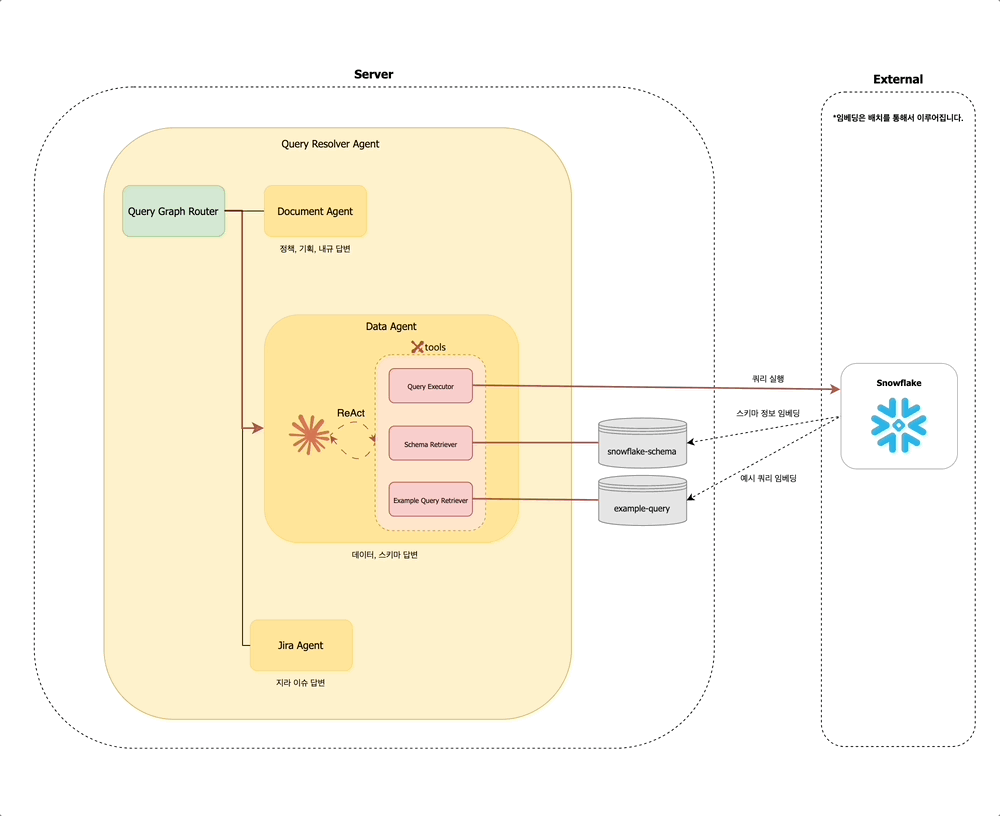
지라 에이전트 (Jira Agent)
지라 에이전트는 지라 서버 API를 호출하여 티켓 정보를 생성, 수정, 조회하는 기능을 수행합니다.
별도의 VectorDB는 구축하지 않았으며, 지라 API를 도구로 직접 사용합니다. 이는 JQL을 활용한 API 호출만으로도 충분히 필요한 데이터를 효과적으로 수집할 수 있기 때문입니다.
지라 에이전트의 동작 방식은 비교적 간단합니다:
- 답변에 필요한 데이터를 수집하기 위해 지라 API 도구를 호출합니다.
- 호출 결과에 따라 추가 호출이 필요한지 혹은 답변을 생성할지 판단합니다.
- 최종 결과를 반환합니다.
여기서 설명을 생략했지만, 사용자가 가벼운 인사를 건네는 등 에이전트로 처리할 필요가 없는 입력을 보내면 Default Agent 노드를 통해 단순 LLM 호출 결과만을 반환합니다.
웹으로의 확장
배경
초기에 사용했던 사용자 인터페이스 "슬랙"은 장점이 명확합니다.
- 이미 구성원 모두가 익숙한 플랫폼이고
- 환경에 구애받지 않고 질문을 할 수 있습니다.
하지만 단점 역시도 명확했습니다.
- 답변이 실시간으로 스트리밍되지 않아서 사용자는 답변을 받기까지 긴 대기 시간을 경험합니다.
- 답변이 너무 긴 경우, 슬랙 API 의 메시지 길이 제한으로 인해 에러가 발생합니다.
- 모델의 답변은 기본적으로 마크다운 형식으로 반환되기에, 슬랙에서 적절히 표시하려면 추가적인 포맷팅 처리가 필요합니다. 이 과정에서 토큰이 추가로 사용되고, 응답 시간이 지연됩니다.
- 답변에 대한 피드백 시스템 구현이 복잡합니다. 예를 들어, 답변에 👎 이모티콘을 붙이는 방식으로 부정적 피드백을 수집하려면, 서버에서 이를 저장하고 피드백 이유를 추가로 수집하는 메커니즘을 별도로 개발해야 합니다.
무엇보다 슬랙에서 관찰된 구성원들의 주요 사용 패턴은 "."을 찍고 스레드로 질의를 이어가는 것이었습니다. 이는 질문이나 답변이 메인 채널에 길게 노출되는 것을 꺼리는 사용자 심리를 반영하는 것으로 보였습니다. 이러한 사용 패턴은 자유로운 똑쿼리 활용을 제한하는 요소로 작용했습니다.
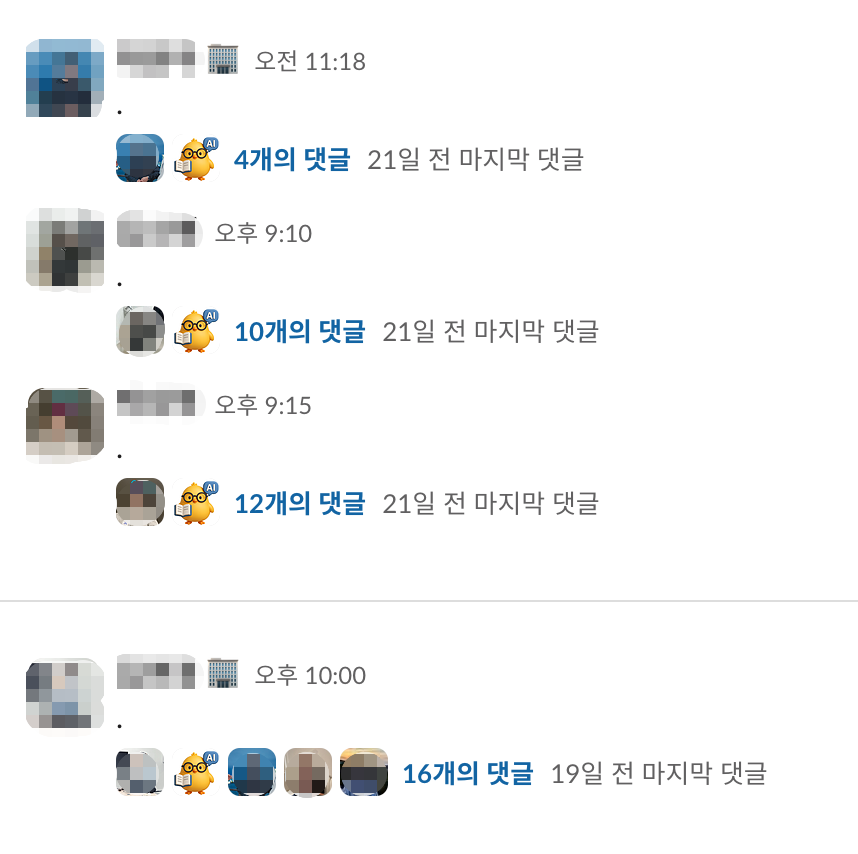
OpenWebUI 도입
OpenWebUI는 다양한 LLM 백엔드(예: OpenAI, Local LLM, HuggingFace 등)와 손쉽게 연동할 수 있는 오픈소스 웹 챗 인터페이스입니다. 웹 기반의 프론트엔드 플랫폼으로, 다음과 같은 주요 기능을 제공합니다:
- 채팅 히스토리 관리 및 공유 기능
- 이미지 및 파일 첨부 지원
- 툴 커맨드 및 플러그인 연동
- 답변 평가 기능
- 슬림하고 직관적인 UI
OpenWebUI를 도입하게 된 가장 큰 이유는, 앞서 언급한 슬랙 기반 인터페이스의 한계를 극복하기 위함이었습니다. 내부 사용자 입장에서는 답변을 실시간으로 스트리밍 받아볼 수 있어 대기 시간에 대한 불편함이 줄고 더 나은 사용자 경험(UX)을 제공할 수 있었습니다. 개발자 입장에서는 OpenWebUI가 자체적으로 제공하는 채팅 관리, 피드백 시스템 등의 기능 덕분에 개발 및 유지보수의 공수를 크게 줄일 수 있었습니다.
무엇보다도 OpenWebUI는 별도의 복잡한 서버 구축 없이 기존 Agent 서버의 API를 그대로 연동할 수 있었고, 사용자 인증이나 커스텀 툴 설정도 비교적 유연하게 구성할 수 있다는 점에서 이상적인 선택지였습니다. 또한 마크다운 형식의 답변을 자연스럽게 렌더링하여 보여주기 때문에 추가적인 포맷팅 작업이 필요하지 않았습니다.
도입을 위해 진행한 작업은 두 가지였습니다:
- 똑쿼리 서버에서 OpenAI 포맷에 맞는
/chat/completionAPI를 제공하고 - OpenWebUI 측에서 해당 서버와의 연동을 위한 파이프를 구성하는 것
작업 자체의 난이도는 높지 않았지만, 하나의 기술적 허들이 있었다면 ReAct Agent의 메시지 청크 스트리밍 처리 방식이었습니다. 기존 Agent의 스트리밍 방식을 OpenAI 호환 형식으로 변환하는 과정에서 몇 가지 조정이 필요했습니다.
�이에 대한 세부적인 기술 구현 이야기는 추후 기회가 되면 따로 다뤄보겠습니다.
모든 세팅을 마친 결과물은 아래와 같습니다:
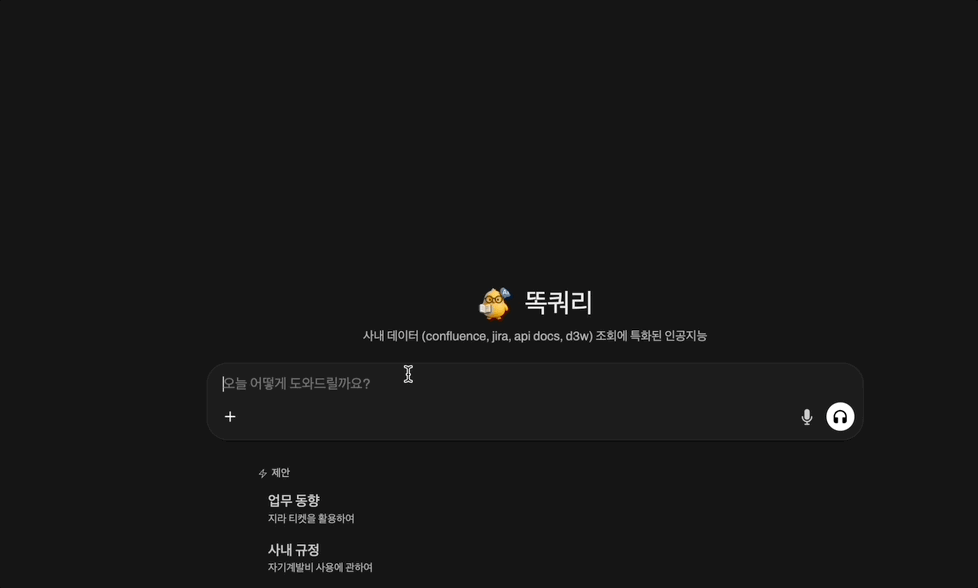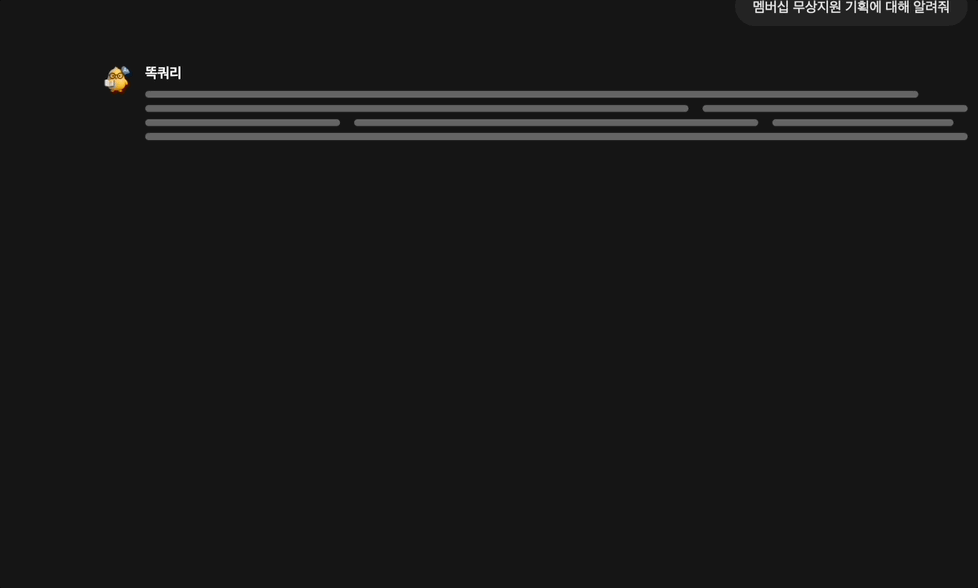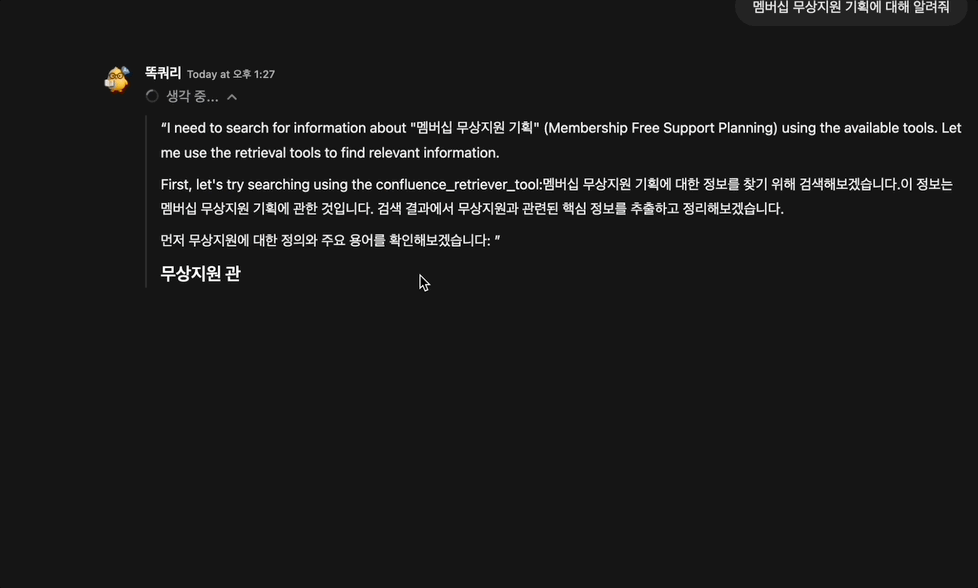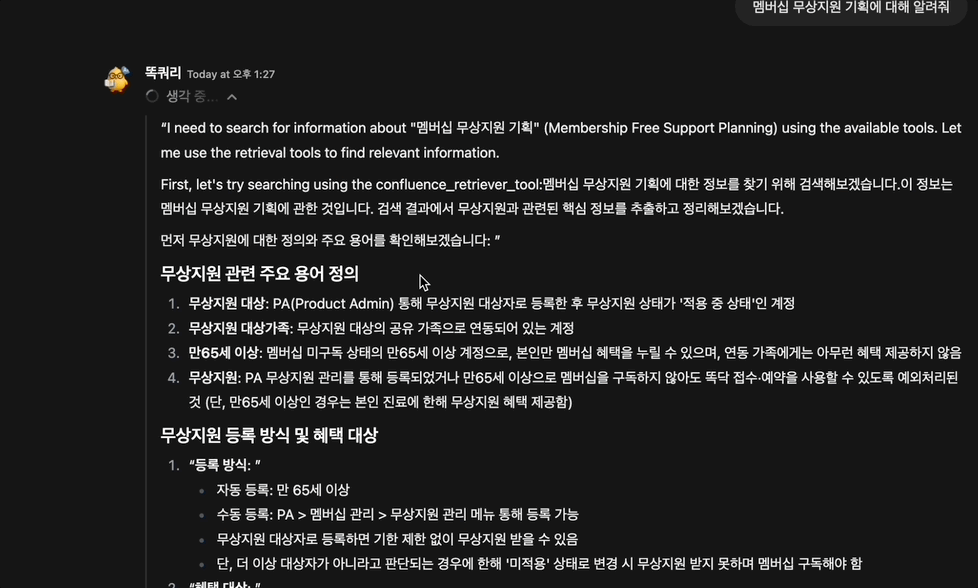
OpenWebUI의 도입에 따라 최종적인 구조도는 다음과 같아졌습니다.
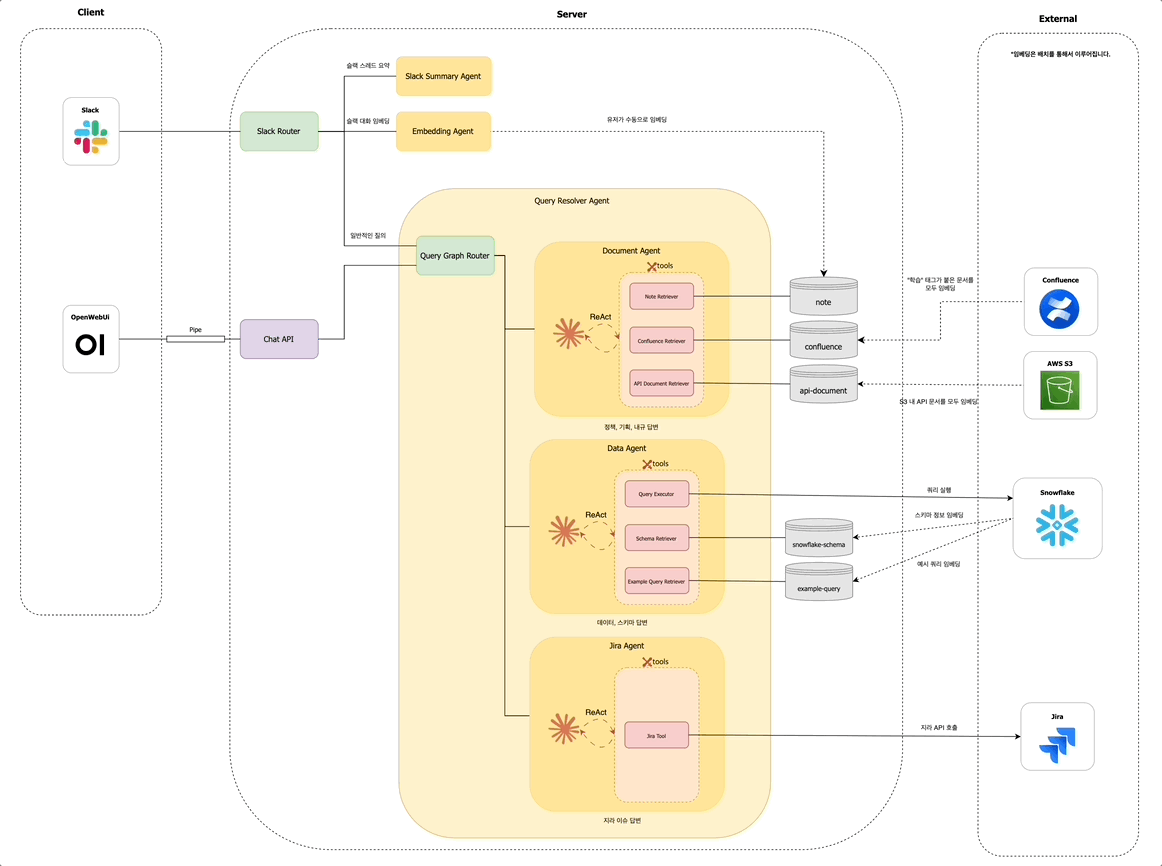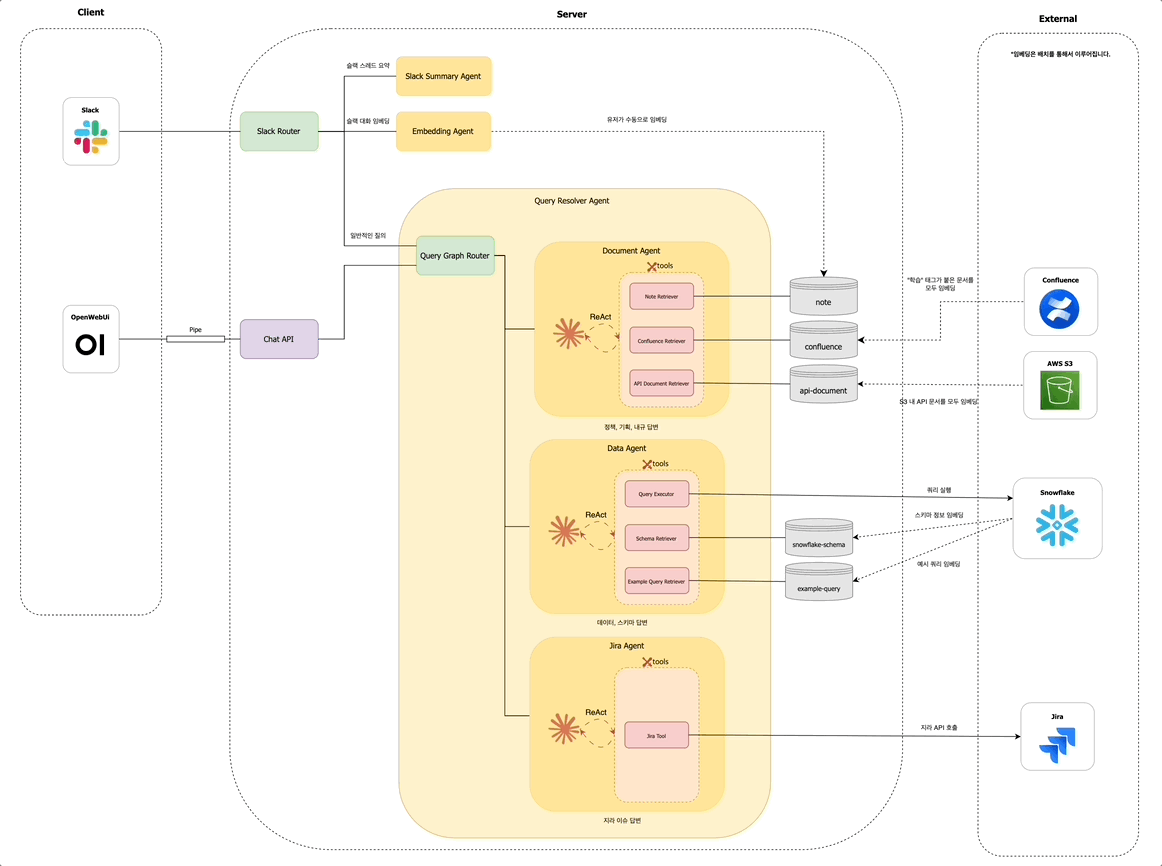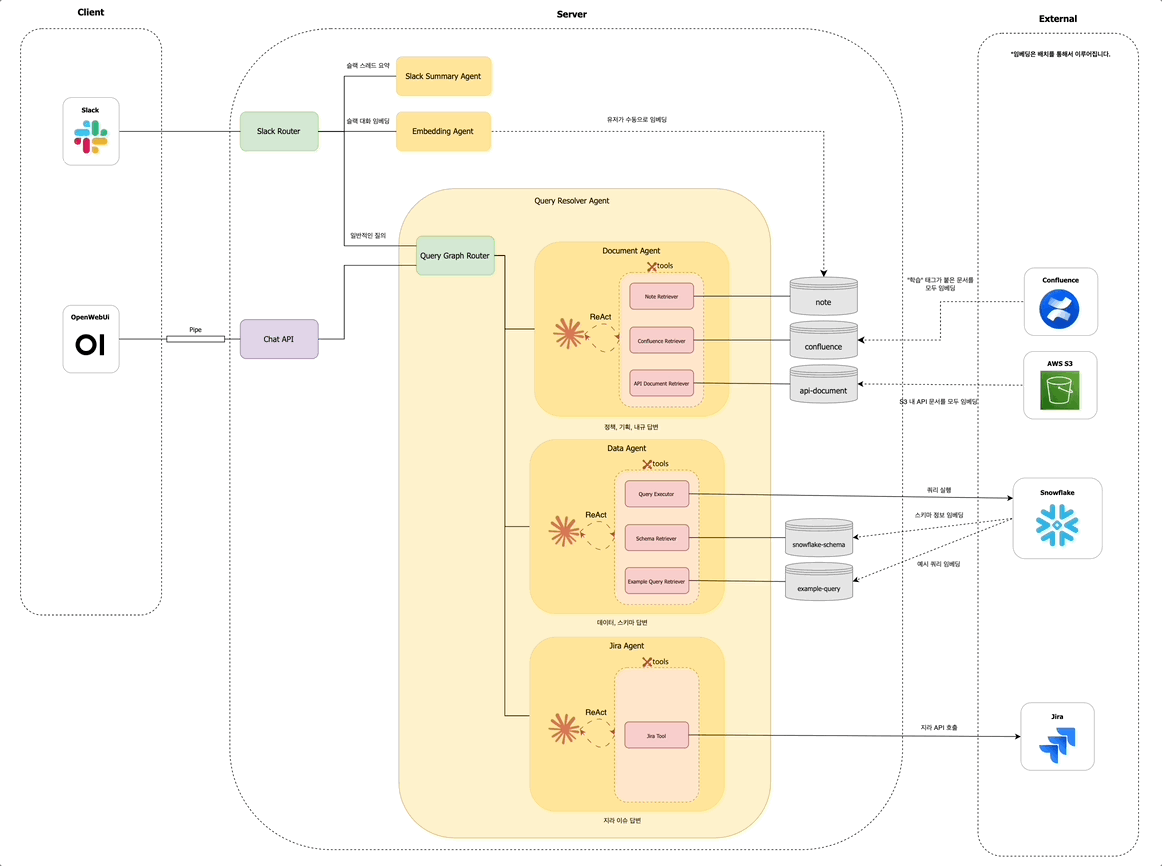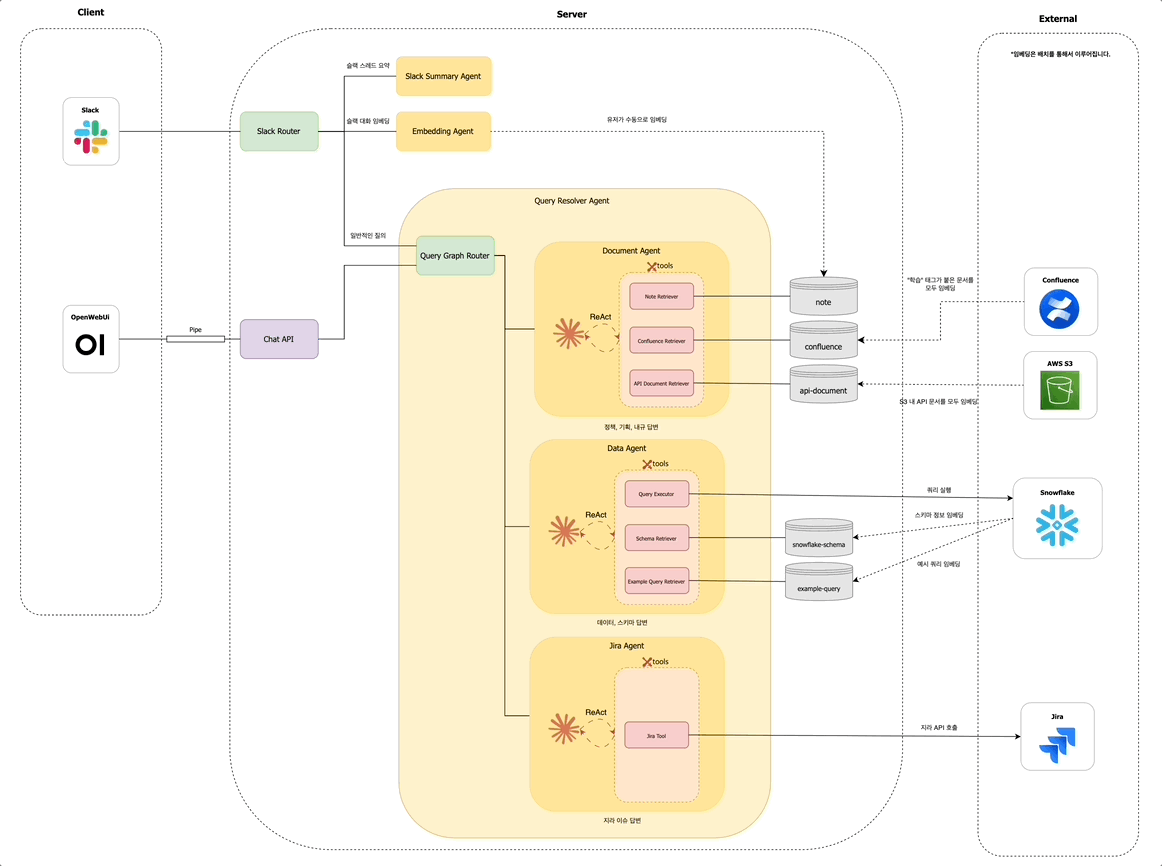
겪었던 문제들
랭그래프 설계 패턴의 고민
랭그래프를 설계하는 패턴은 Routing 패턴, Supervisor 패턴, Custom 패턴 등 다양하게 존재합니다. 각 패턴에는 장단점이 존재하고, 어떤 장점을 취하고 어떤 단점을 수용할지에 따라 적합한 설계 패턴이 달라집니다.
똑쿼리는 처음 랭그래프를 도입했을 때, Supervisor 패턴을 사용하였습니다. Supervisor 패턴이란, 여러 하위 에이전트를 호출할 수 있는 "Supervisor Node"가 존재하고 에이전트 호출 결과를 종합하여 최종 결과를 도출하는 방식입니다.
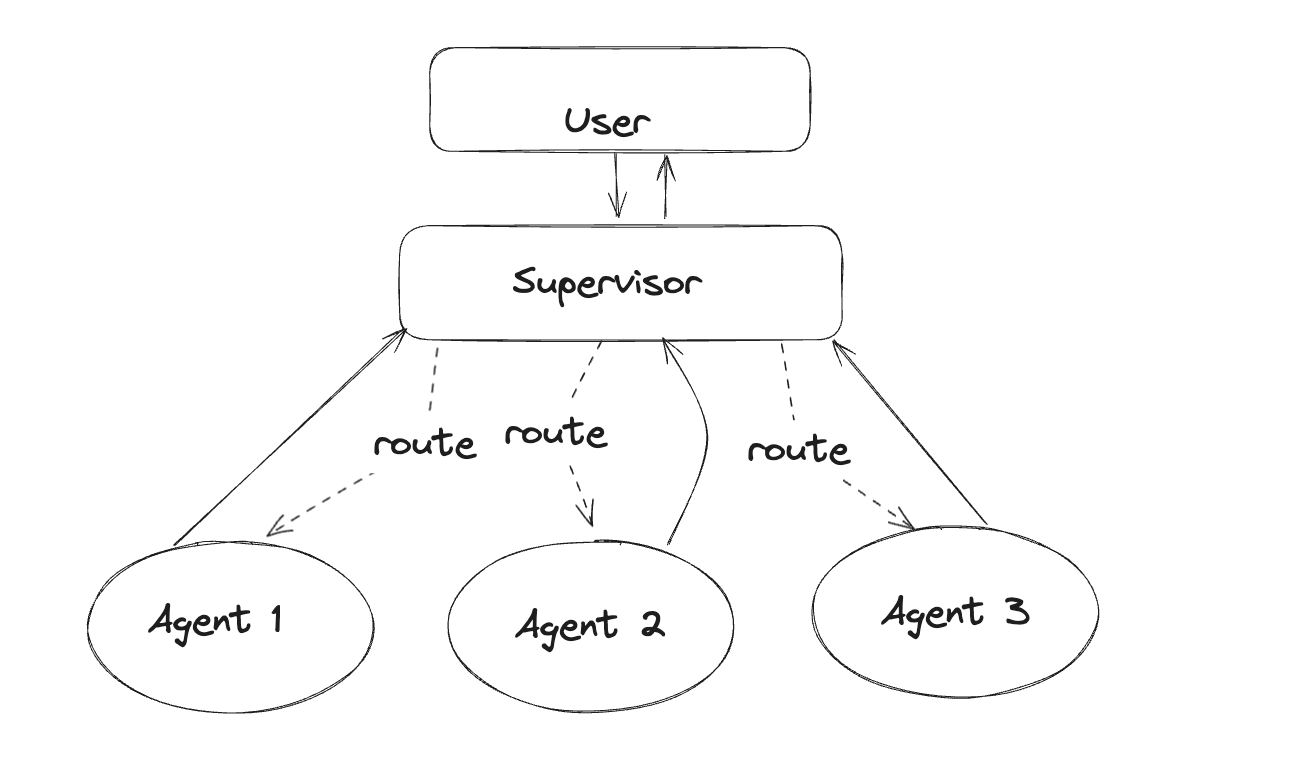
이 패턴의 장점은 여러 에이전트의 결과를 종합할 수 있다는 데에 있습니다. 예를 들어, "활성화 병원이 지금 몇 개야?" 라는 질문에 대해 문서 에이전트에서 "활성화 병원"이 의미하는 바를 찾고, 그 결과를 바탕으로 "데이터 에이전트"를 호출하여 쿼리를 실행해 최종 결론을 도출할 수 있습니다.
구현 역시 어렵지 않습니다. 공식 문서에서 Community Agent로 제공하는 라이브러리 중 langgraph-supervisor를 활용하면 다중 에이전트를 슈퍼바이저 패턴으로 쉽게 묶을 수 있습니다.
처음에는 이상적인 동작을 기대했지만, 막상 적용을 하고나니 이 패턴의 단점이 눈에 들어오기 시작했습니다.
- 하위 에이전트단에서 관련 데이터를 찾을 수 없어서 결과를 찾을 수 없다고 슈퍼바이저에게 전달하면, 슈퍼바이저가 또다시 동일한 하위 에이전트를 불필요하게 호출하는 문제가 존재하였습니다.
- 하위 에이전트의 결과를 슈퍼바이저가 받아서 유저로 전달하는 과정에서 일부 중요 정보를 누락하는 경우가 존재하였습니다.
- 답변이 길어질 경우, 에이전트가 답변을 생성하는 시간과 슈퍼바이저가 하위 에이전트의 답변을 받아 최종 답변을 생성하는 시간이 합쳐져 사용자가 최종 응답을 받기까지 대기 시간이 크게 늘어났습니다.
그렇다고 슈퍼바이저 패턴의 장점이 잘 활용되는 것도 아니었습니다. 실제 사용자 질문은 대부분 "유저의 일주일 가입 방식은 어떻게 돼?"와 같은 단편적인 질문이었고, 슈퍼바이��저의 행동 패턴은 단순히 하위 에이전트 하나를 호출하여 결과를 받고 유저에게 반환하는 식이었습니다.
이런 문제들을 인지하고, 저희는 슈퍼바이저 패턴(Supervisor pattern)으로 설계된 랭그래프를 라우터 패턴(Router pattern)으로 변경하였습니다.
라우터 패턴은 슈퍼바이저 패턴에 비해 간단합니다. 라우터 노드가 존재하고, 질문에 대해 가장 적합한 특정 하위 에이전트로 워크플로우가 직접 흐르도록 합니다. 똑쿼리 내 라우터 노드(Router Node)는 Claude-haiku라는 경량 모델을 사용하여 유저의 질문에 대해 어떤 하위 에이전트를 호출할지 결정하도록 하였습니다.
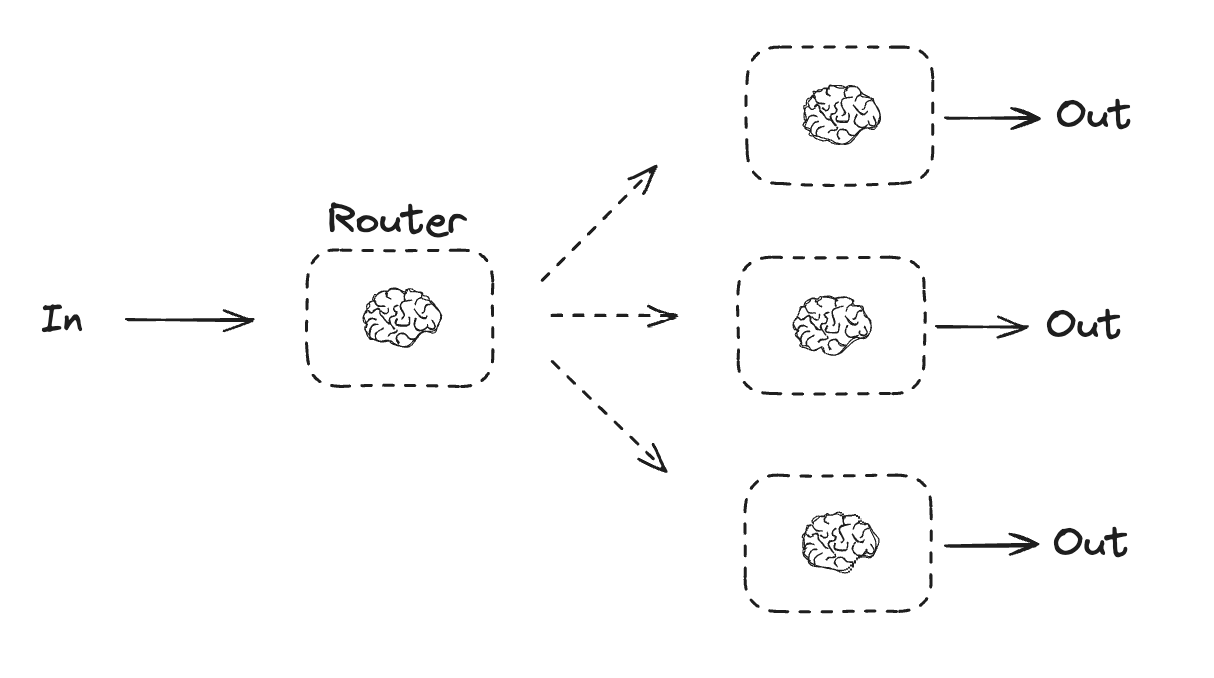
해당 패턴을 적용한 후에는 아래와 같은 이점을 얻을 수 있었습니다.
- 응답 속도가 65.9% 향상되었습니다. (2분 56초 → 1분)
- 하위 에이전트가 불필요하게 다시 호출되는 일이 사라졌습니다.
- 하위 에이전트가 생성한 답변의 모든 내용이 온전히 유저에게 전달될 수 있었습니다.
두 에이전트를 모두 호출하여 결과를 종합하는 행위는 수행할 수 없지만, 이것이 사용자들이 똑쿼리로부터 원하는 답변이 받지 못하는 결과를 초래하는 일은 아직까지 관찰되지 않았습니다. 물론 라우터 패턴의 한계를 직면한 시점에는 또 다른 패턴을 적용할지도 모릅니다.
부정확한 RAG 결과
**RAG(Retrieval-Augmented Generation)**는 LLM 기�반 응용에서 외부 지식을 활용하기 위한 대표적인 방식입니다. RAG는 크게 두 단계로 구성됩니다:
- Retrieval (검색): 사용자의 질문을 기반으로 벡터 DB 등에서 관련 문서를 찾고,
- Generation (생성): 찾은 문서를 바탕으로 답변을 생성합니다.
여기서 임베딩(embedding)은 텍스트를 고차원 벡터로 변환하여 의미 기반 검색을 가능하게 해주는 핵심 요소입니다. 일반적으로 질문과 문서를 각각 임베딩한 뒤, 코사인 유사도 등으로 유사한 문서를 찾아옵니다.
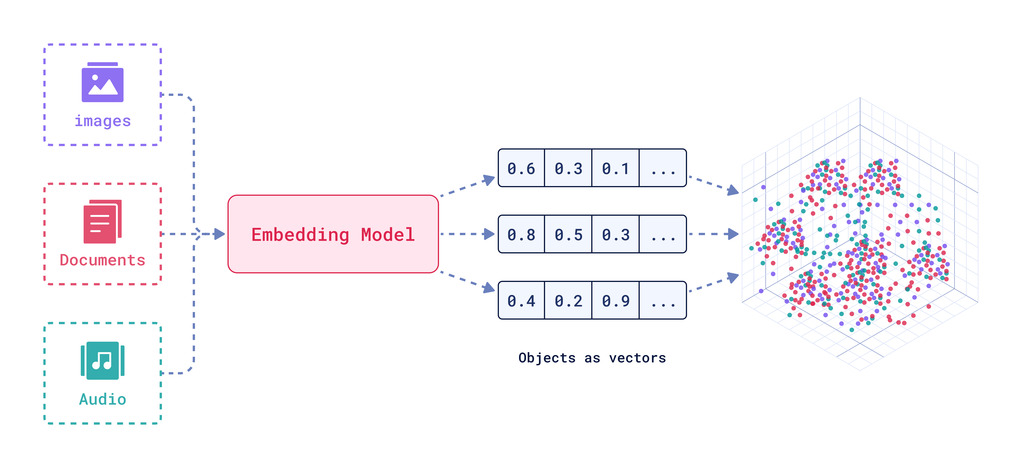
RAG는 지금까지도 Langchain 커뮤니티에서 활발히 사용되고 있지만, 저희는 두 가지 문제를 직면하였습니다.
(1) Retrieval를 통해 항상 정확한 문서를 찾을 수만은 없었습니다.
예를 들어, 아래와 같이 구성된 벡터 데이터베이스를 떠올려봅시다.
| text | vector |
|---|---|
| 멤버십 정책은 ... | [ 0.1, 0.46, ... ] |
| 접수 정책은 ... | [ 0.32, 0.87, ... ] |
| 예약 정책은 ... | [ 0.19, 0.91, ... ] |
사용자가 "멤버십 정책 알려줘" 라고 입력했을 때 Retrieval 단계에서 "멤버십"라는 쿼리로 검색을 한다면 멤버십 정책 문서를 정상적으로 얻을 수 있습니다. 하지만 에이전트가 Retrieval 단계에서 "정책"이라는 쿼리로 검색을 한다면 불필요한 문서를 모두 조회하게 되고, 경우에 따라 멤버십 정책 문서는 조회되지 못할지도 모릅니다.
(2) 찾은 문서가 LLM에게 가장 기억되는 형태로 반환되지 않았습니다.
LLM은 Transformer 기반으로 동작하기에 "Lost in the Middle" 현상을 지니고 있습니다. "Lost in the Middle"은 대규모 언어 모델(LLM)이 긴 문서나 입력에서 중간에 위치한 정보의 중요도를 제대로 반영하지 못하는 현상을 의미합니다. 주로 수천 토큰 이상의 입력을 처리할 때 발생하며, 모델이 문서의 처음과 끝에 있는 정보는 잘 기억하지만, 중간에 있는 내용은 상대적으로 무시하거나 놓치는 경향을 보입니다.
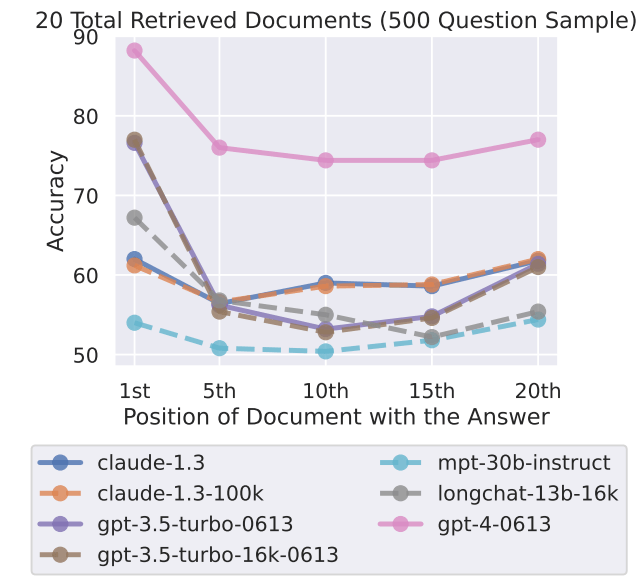
RAG로 첨부되는 문서 역시 중간 문서는 LLM이 제대로 인식하지 못할 가능성이 존재합니다. 이 경우 Retrieval를 통해 조회된 문서가 그대로 모델에게 전달되면, 오히려 검색 스코어가 낮은 문서가 LLM에게 중요하게 인식되어 좋지 못한 답변으로 이어지기도 합니다.
이런 두 가지 RAG의 고전적인 문제는 똑쿼리 서버에서도 동일하게 나타났습니다. 에이전트가 불필요하게 ReAct를 반복하는 시점에 Langsmith를 활용해서 워크플로우의 단계별 흐름을 확인하였고, 이 과정에서 RAG가 올바른 결과 도출의 병목으로 작용하는 것을 관찰하였습니다.
이 문제를 해결하기 위해 두 가지 방안을 적용하였습니다.
(1) MultiQueryRetriever 도입
MultiQueryRetriever는 하나의 질문에 대해 다양한 표현으로 변형된 여러 쿼리를 생성하고, 이를 통해 더 넓고 풍부한 검색 결과를 확보하는 방식입니다.
가령, "멤버십 정책 알려줘" 라는 유저 입력에 대해 "멤버십", "멤버십 정책", "멤버십 상세 정책" 등의 여러 쿼리를 만들어 Retriever를 통해 문서를 검색하는 방식입니다. 여러 쿼리는 LLM 을 통해 생성되고, 저희는 "정책", "테이블"과 같은 일반적인 명사를 쿼리로 활용하지 못하게 프롬프트로 지시하였습니다.
Langchain 라이브러리에서 MultiQueryRetriever를 지원하기에 구현이 어렵지 않습니다.
from langchain.retrievers.multi_query import MultiQueryRetriever
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=base_retriever,
llm=llm,
prompt=prompt,
)
(2) Document Reordering 적용
검색된 문서를 단순히 임베딩 유사도 순서로 정렬하는 대신, LLM 또는 별도의 랭킹 모델을 이용해 재정렬하는 방식입니다. Langchain 커뮤니티 라이브러리에서 제공되는 LongContextReorder 클래스를 사용하여 구현하였습니다.
from langchain_community.document_transformers import LongContextReorder
reorder = LongContextReorder()
def get_relevant_documents(query: str, **kwargs) -> list[Document]:
docs: list[Document] = get_relevant_documents_by_multi_query(query, **kwargs)
reordered_docs: list[Document] = reorder.transform_documents(docs)
return reordered_docs
이를 통해, 결과적으로 보다 넓은 문서 후보를 확보하였으며, 최적의 문서를 생성 모델에 전달하여 정확도와 일관성이 향상된 답변을 사용자에게 제공할 수 있게 되었습니다.
앞으로의 과제
여러 개발들을 거치며 똑쿼리는 분명 기존에 비해 성능적으로, 기능적으로 크게 향상되었습니다. 그럼에도 우리에게 남은 과제는 아직 많습니다.
- 멀티모달 지원 확장: 현재 텍스트 기반 질의응답에 최적화되어 있으나, 이미지, PDF 파일 등 다양한 형식의 데이터를 처리할 수 있는 기능이 아직 미흡합니다. 사용자가 차트나 스크린샷을 업로드하고 이에 대한 분석을 요청하는 시나리오를 지원할 필요가 있습니다.
- 정량적 평가 체계 구축: 리더보드 등의 부재로 모델이 산출한 결과를 정량적으로 평가하는 과정이 아직 없습니다. 답변의 정확성, 관련성, 응답 시간 등을 측정하여 모델 성능을 객관적으로 평가하고 개선할 수 있는 지표가 필요합니다.
- 그래프 결과 피드백 루프 도입: 랭그래프의 각 노드와 워크플로우 단계별 성능을 모니터링하고, 이를 바탕으로 시스템을 자동으로 최적화할 수 있는 피드백 메커니즘을 구현할 필요가 있습니다.
- 사용자 피드백 활용 방안: 사용자들이 똑쿼리 답변에 준 피드백(좋아요/싫어요, 코멘트 등)을 수집하고 이를 모델 개선에 효과적으로 반영할 수 있는 방법론을 개발해야 합니다. 이는 지속적인 학습과 개선을 위한 중요한 데이터 소스가 될 것입니다.
- 고급 랭그래프 기능 도입: 똑쿼리 서버 내 랭그래프에서 Agent-to-Agent(A2A) 통신, Message Passing Control Protocol(MCP) 등의 고급 기능을 도입하여 더 복잡한 추론과 문제 해결 능력을 갖출 수 있습니다.
- LLMOps 체계 구축: LangSmith 또는 Langfuse와 같은 도구를 활용하여 모델 배포, 모니터링, 버전 관리 등을 체계적으로 수행할 수 있는 LLMOps 파이프라인을 구축할 필요가 있습니다.
지금 당장 모든 과제를 수행할 수는 없지만, 구성원들에게 설문 조사를 통해 의견을 수렴하고 기능의 우선순위를 세워 하나씩 수행해나갈 예정입니다. 이러한 개선 과정을 통해 똑쿼리가 비브로스 구성원들의 든든한 개인 비서로 거듭나는 그 날까지 많은 응원 부탁드립니다 :)