예약 시스템 개편기: 우리는 왜 '예약 레고'를 만들었나

들어가며
안녕하세요. 비브로스에서 백엔드 개발을 담당하고 있는 김예림입니다.
이번 글에서는 병원 예약 시스템을 전면 개편한 경험을 공유하려 합니다. "예약"이라고 하면 단순히 시간을 골라 버튼을 누르는 것으로 끝날 것 같지만, 실제로는 그 이면에 예상보다 복잡한 문제들이 숨어 있었습니다.
감기 진료 10분, 예방접종 5분, 초음파 50분. 진료 항목마다 소요 시간이 다른데, 이것들을 하나의 시간표 위에 빈틈없이 쌓을 수 있을까요? 마치 레고 블록처럼 크기가 다른 조각들을 빈 공간 없이 채워 넣는 것이 이번 개편의 핵심 목표였습니다.
이 글에서는 다음 문제들을 풀어간 과정을 설계 관점에서 다루겠습니다.
- 진료 항목마다 다른 소요 시간을 어떻게 하나의 시간표에 빈틈없이 쌓을 것인가?
- 두 사람이 동시에 같은 시간을 예약하면 어떻게 할 것인가?
- 예약 수가 맞지 않을 때, 원인을 어떻게 추적할 것인가?
1. 왜 개편이 필요했는가
1.1 고정 시간 간격의 한계
기존 시스템은 특정 시간대에 대해 하나의 고정된 간격만을 설정할 수 있었습니다. 예를 들어 09:00~12:00 시간대를 10분 간격으로 설정하면, 해당 시간대의 모든 예약은 10분 단위로만 가능했습니다.
문제는 실제 진료 시간이 항목마다 크게 다르다는 점입니다.
| 진료 항목 | 실제 소요 시간 | 10분 간격 설정 시 문제 |
|---|---|---|
| 예방접종 | 5분 | 5분 낭비 |
| 일반 진료 | 10분 | 적정 |
| 초음파 검사 | 30분 | 3슬롯 연속 예약 필요 |
병원 입장에서는 딜레마에 빠지게 됩니다. 30분짜리 초음파 검사를 위해 시간대 전체를 30분 간격으로 설정하면, 5분이면 끝나는 예방접종에도 30분 슬롯이 할당되어 25분의 공백이 발생합니다. 반대로 5분 간격으로 설정하면 초음파 검사 시 6개의 연속 슬롯을 수동으로 관리해야 합니다.
결국 하나의 시간대에서 서로 다른 소요 시간의 진료를 유연하게 받을 수 없는 구조적 한계가 있었습니다.
1.2 기존 카운팅 구조의 문제
기존의 예약 카운팅 데이터는 다음과 같은 구조였습니다.
// 기존 카운팅 문서
{
hospitalId: 12345,
unitKey: "진료실A",
date: "2025-01-02",
reservationTime: {
time: "11:00",
count: 3, ← 현장 예약 수
progressCount: 2 ← 온라인 예약 수
}
}
이 구조에는 두 가지 치명적인 문제가 있었습니다.
첫째, Race Condition에 취��약했습니다. 최종 카운트만 저장하기 때문에 두 요청이 동시에 count를 읽고 각각 +1하여 저장하면, 실제로는 2가 증가해야 하지만 1만 증가하는 문제가 발생할 수 있었습니다.
둘째, 디버깅이 사실상 불가능했습니다. "이 카운트가 왜 이 값인가?"에 대한 추적이 불가능했고, 간혹 비정상적인 값이 저장되어도 원인을 파악하기 어려웠습니다. 누가, 언제, 어떤 예약으로 인해 이 숫자가 됐는지 알 수 있는 방법이 없었습니다.
2. 새로운 설계: 가변 슬롯 시스템
2.1 핵심 아이디어: 진료 항목별 시간 간격
새 시스템의 핵심은 진료 항목마다 고유한 시간 간격(timeUnit)을 부여하는 것입니다.
병원은 먼저 진료실에서 취급하는 진료 항목들을 등록하고, 각 항목별로 소요 시간을 설정합니다.
진료 항목 설정 (진료실A):
| 진료 항목 | timeUnit |
|---|---|
| 감기 | 10분 |
| 예방접종 | 5분 |
| 초음파 검사 | 50분 |
그 다음, 예약 스케줄의 각 시간대에 원하는 진료 항목을 추가합니다. ��예를 들어 09:00~17:00 시간대에 "감기"와 "초음파 검사"를 추가하면, 해당 시간대에서는 이 두 항목에 대한 예약만 받을 수 있습니다.
스케줄 설정 예시:
09:00 ~ 17:00 → [감기(10분), 초음파(50분)] 동시 2명
이렇게 설정하면 같은 시간대 위에서 크기가 다른 슬롯들이 자연스럽게 공존하게 됩니다. 이것이 "레고처럼 쌓는다"는 콘셉트의 핵심입니다.
위 다이어그램처럼 1열과 2열에서 크기가 다른 블록들이 빈틈없이 공존합니다.
- A(09:00~09:10)와 B(09:00~09:50)는 겹치지만 동시 2명 이내이므로 OK
- C(09:10~09:20)는 B와 겹침, 이 시점 동시 예약이 2명(B+C)이므로 OK
- 만약 D가 09:00~09:10에 예약하면? A+B로 이미 2명이므로 마감
10분짜리 감기 슬롯과 50분짜리 초음파 슬롯이 빈틈없이 같은 시간표 위에 쌓이는 것이 핵심입니다. 기존에는 시간대 전체를 하나의 간격으로 강제해야 했지만, 이제는 진료 항목의 timeUnit에 따라 각자 다른 크기의 블록을 자유롭게 배치할 수 있습니다.
2.2 스케줄 구조: 템플릿 스케줄 + 커스텀 스케줄
스케줄 구조를 설계하기 전에, 먼저 병원들이 실제로 예약 스케줄을 어떻게 운영하고 있는지 살펴볼 필요가 있었습니다.
아래는 기존 시스템에서 병원들이 사용하던 스케줄 설정 화면입니다.
| 단순 운영 패턴 | 복잡 운영 패턴 |
|---|---|
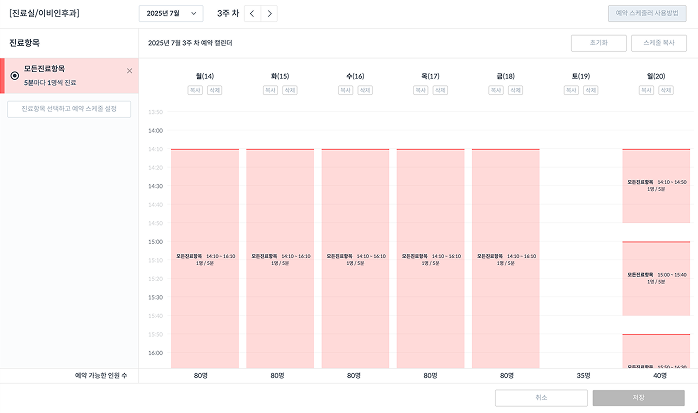 | 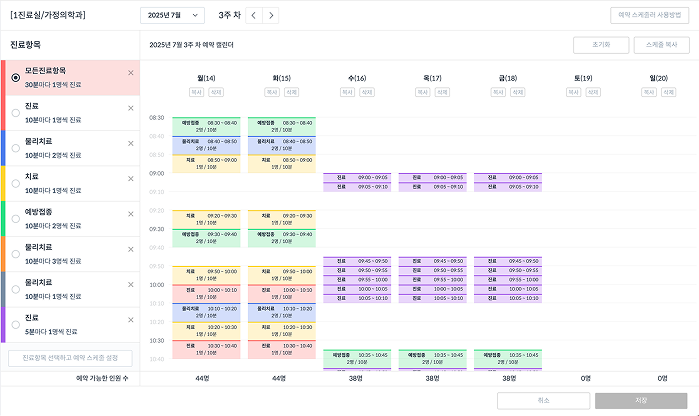 |
왼쪽 병원은 하나의 진료항목만 사용하여 단순하게 운영하고 있지만, 오른쪽 병원은 진료, 물리치료, 예방접종 등 다양한 항목을 요일마다 다르게 조합하고 있습니다. 실제로 병원마다 운영 방식이 천차만별이었고, 매주 비슷한 패턴이 반복되지만 특정 주에는 학회, 휴무 등으로 예외가 생기는 경우��도 빈번했습니다.
이런 현실을 반영하여, 스케줄 관리를 두 가지 계층으로 분리했습니다.
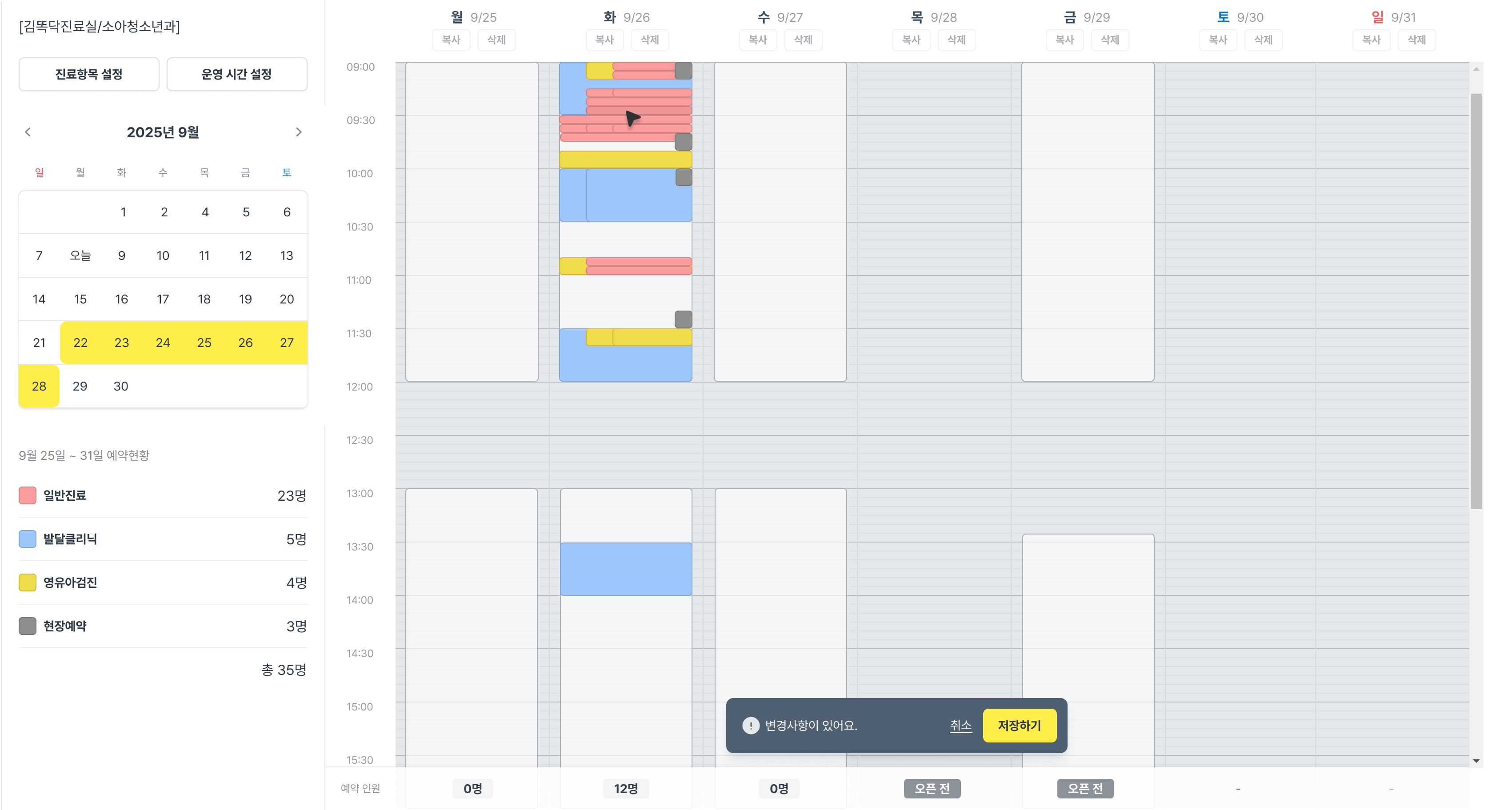
템플릿 스케줄(TemplateSchedule) 은 요일별 반복 패턴입니다. "월요일에는 이런 시간표, 화요일에는 이런 시간표"처럼 병원의 기본 운영 패턴을 정의합니다. 공휴일 패턴도 별도로 설정할 수 있습니다. 위 화면처럼 진료항목별로 색상이 구분되어, 요일마다 어떤 항목을 어떤 시간에 운영하는지 한눈에 파악할 수 있습니다.

커스텀 스케줄(CustomSchedule) 은 특정 주(월~일) 단위로 템플릿을 오버라이드합니다. 학회 참석, 임시 휴무, 특별 진료 등 예외 상황에 사용합니다. 캘린더에서 해당 주를 선택한 뒤 요일별로 복사·삭제할 수 있어, 예외 스케줄도 간편하게 관리됩니다.

실제 스케줄 조회 시에는 커스텀이 우선 적용됩니다.
이 구조 덕분에 병원은 한 번만 템플릿을 설정해두면 매주 자동으로 반복되고, 예외가 생기는 주만 커스텀으로 덮어쓰면 됩니다. 또한 커스텀 스케줄에는 낙관적 잠금(__v 버전 필드)을 적용하여, 두 관리자가 동시에 같은 주의 스케줄을 수정할 때 충돌을 감지합니다.
각 시간대(enableTime)에는 시작 시간, 종료 시간, 허용 진료 항목 목록, 동시 예약 가능 인원이 정의됩니다. 하나의 시간대에 여러 진료 항목을 할당할 수 있기 때문에, 같은 시간대에서 예방접종과 일반 진료를 함께 받을 수 있게 됩니다.
3. 예약 가능 시간 찾기
3.1 조회 시점 계산
기존 시스템에서는 스케줄 자체에 timeUnit이 고정되어 있어서, 스케줄이 저장되는 시점에 슬롯이 미리 생성되었습니다. 09:00~12:00을 10분 간격으로 설정하면, 09:00, 09:10, 09:20, ... 이라는 슬롯이 미리 만들어져 있는 구조였습니다.
새 시스템에서는 슬롯을 미리 생성하지 않습니다. 스케줄에는 시간대(09:00~17:00)와 허용 진료 항목 목록만 저장하고, 사용자가 특정 진료 항목으로 예약 가능 시간을 조회하는 시점에 해당 항목의 timeUnit을 가져와서 가능한 시간대를 계산합니다.
이 방식의 장점은 명확합니다. 같은 시간대에 대해 진료 항목마다 다른 시간 간격의 슬롯을 제공할 수 있고, 진료 항목의 timeUnit을 변경하더라도 스케줄을 다시 생성할 필요가 없습니다.
구체적으로, 사용자가 특정 진료 항목의 예약 가능 시간을 조회하면 시스템은 해당 항목의 timeUnit을 가져와서 시간대 범위 안에서 가능한 슬롯을 계산합니다. 시작 시간부터 종료 시간까지 timeUnit 간격으로 순회하며, 슬롯의 종료 시간이 시간대 범위를 넘지 않는 것만 포함합니다. 예를 들어 11:00~12:00에 timeUnit이 50분이면 11:00만 포함되고(11:00+50분=11:50 ≤ 12:00), 11:10은 종료 시간이 12:00을 넘어가므로 제외됩니다.
3.2 시간 겹침 판정
각 슬롯이 예약 가능한지 판단하려면, 해당 슬롯 시간대에 이미 몇 건의 예약이 있는지를 알아야 합니다. 이때 핵심이 되는 것이 시간 겹침 판정입니다.
가변 슬롯 시스템에서는 예약마다 차지하는 시간 범위가 다릅니다. 10:00~10:10 슬롯의 예약 가능 여부를 확인하려면, 이 시간과 겹치는 모든 기존 예약을 찾아야 합니다.
두 시간 구간이 겹치는 조건 (반개구간 [start, end) 기준):
구간 A: [start1, end1)
구간 B: [start2, end2)
겹침 조건: start1 < end2 AND start2 < end1
직관적으로 이해하면 이렇습니다.
- 겹치는 경우: 조회 슬롯(0~10)과 R001(0~50)은
0 < 50 AND 0 < 10이므로 겹침 - 경계가 맞닿는 경우: 조회 슬롯(0~10)과 R002(50~60)은
0 < 60 AND 50 < 10이 거짓이므로 겹치지 않음 - 반개구간
[start, end)기준이므로, 09:00~09:10과 09:10~09:20은 충돌하지 않음
이 공식으로 기존 예약들을 순회하며 겹치는 건수를 세고, 그 수가 동시 예약 가능 인원(concurrentCount)보다 적으면 예약 가능, 같거나 크면 마감으로 판정합니다.
3.3 겹침 탐색의 시간 복잡도: 향후 최적화 방향
현재 구현은 슬롯 하나의 겹침을 확인할 때 reservedTime[] 배열 전체를 순회합니다. 예약 수를 n, 조회할 슬롯 수를 m이라 하면 전체 시간 복잡도는 O(m × n) 입니다.

현재 진료실 하나의 일일 예약 수(n)는 수십~백여 건 수준이고, 선형 탐색으로도 응답 시간에 문제가 없습니다. 하지만 향후 서비스가 성장하여 예약 수가 크게 증가하거나, 여러 진료실을 한 번에 조회해야 하는 기능이 추가된다면 최적화가 필요할 수 있습니다.
이때 검토해볼 수 있는 자료구조가 Interval Tree입니다. Interval Tree는 구간(interval) 데이터를 효율적으로 저장하고, 특정 구간과 겹치는 모든 구간을 빠르게 찾아주는 이진 탐색 트리 기반의 자료구조입니다.

또 하나 검토해볼 수 있는 알고리즘이 Sweep Line(스위프 라인) 입니다. Interval Tree가 "특정 구간과 겹치는 예약 찾기"에 특화되어 있다면, Sweep Line은 "모든 시점의 동시 예약 수를 한 번에 계산"하는 데 적합합니다.

각 예약의 시작/종료를 이벤트로 변환하고 시간순 정렬한 뒤, 순서대로 스위프하며 카운트를 증감시킵니다. 한 번의 정렬(O(n log n))과 한 번의 순회(O(n))로 모든 시점의 동시 예약 수를 알 수 있어, 슬롯 수(m)에 관계없이 효율적입니다.
| 방식 | 겹침 조회 (슬롯 1개) | 전체 조회 (슬롯 m개) | 적합한 상황 |
|---|---|---|---|
| 선형 탐색 | O(n) | O(m × n) | 소규모 데이터, 단순 구현 |
| Interval Tree | O(log n + k) | O(m × (log n + k)) | 특정 구간의 겹침을 빠르게 조회 |
| Sweep Line | O(n log n) 전처리 후 O(1) | O(n log n + m) | 모든 슬롯을 한 번에 판정 |
k는 실제로 겹치는 예약 수로, 동시 예약 제한(concurrentCount)에 의해 상한이 정해집니다.
현재로서는 선형 탐색이 적합한 선택이라고 판단합니다. 데이터 규모가 작고, 예약 데이터가 MongoDB 문서의 배열로 저장되어 DB에서 가져온 뒤 인메모리에서 처리하는 구조이기 때문입니다. 단순한 구현은 디버깅이 쉽고, 최적화가 필요하지 않은 곳에 복잡한 자료구조를 도입하면 유지보수 부담만 늘어납니다.
다만 향후 예약 데이터가 대폭 증가하거나 다수의 진료실을 통합 조회하는 기능이 필요해진다면, Sweep Line으로 전체 슬롯의 예약 현황을 한 번에 계산하거나, Interval Tree를 인메모리 캐시로 활용하는 방향을 검토해보고 싶습니다.
3.4 전체 흐름
예약 가능 시간 조회의 전체 흐름을 정리하면 다음과 같습니다.

여기서 countOverlappingReservations는 앞서 설명한 시간 겹침 공식을 사용하여 해당 슬롯과 겹치는 기존 예약의 수를 계산합니다. 기존 예약 데이터는 다음 절에서 설명할 ReservationSoldCount의 reservedTime[] 배열을 순회하며, 각 레코드의 startTime/endTime과 슬롯의 시간 범위를 비교합니다.
4. 동시성 제어: 5분 단위 분산 락
예약 가능 시간을 정확히 계산하더라도, 두 사람이 거의 동시에 같은 시간을 예약하면 문제가 발생합니다.
이 문제를 해결하기 위해 Redis 기반 분산 락(RedLock) 을 도입했습니다.
4.1 왜 5분 단위로 분할하는가?
단순히 "10:00~10:30" 전체에 하나의 락을 거는 방식도 가능합니다. 하지만 이렇게 하면 동시간대의 다른 슬롯 예약까지 불필요하게 차단됩니다.
5분은 시스템에서 허용하는 최소 예약 단위입니다. 이 단위로 락을 분할하면 겹치는 구간에서만 정확하게 충돌을 감지하면서, 겹치지 않는 구간의 예약은 병렬로 처리할 수 있습니다.
4.2 락 획득 전략
분산 락의 핵심 규칙은 All-or-Nothing입니다.

락의 TTL(Time To Live)은 60초로 설정했습니다. 예약 처리가 비정상적으로 오래 걸리거나 서버가 다운되더라도 60초 후에는 자동으로 락이 해제되어 다른 요청이 진행될 수 있습니다.
4.3 이중 락 전략
실제로는 예약 과정에서 두 단계의 락이 적용됩니다.
1단계 락은 같은 시간대에 중복 예약 요청이 동시에 처리되는 것을 방지하고, 2단계 락은 예약 카운트 갱신 시 데이터 정합성을 보장합니다. 두 락의 TTL이 다른 이유는 역할의 차이 때문입니다. 요청 락은 전체 예약 흐름(검증, 생성, 카운트, 후처리)을 포괄하므로 60초, 카운트 락은 단순 배열 push 작업이므로 10초면 충분합니다.
5. 개별 레코드 기반 카운팅
앞서 1.2절에서 기존 카운팅 구조의 문제를 살펴보았습니다. 단순 숫자만 저장하면 "이 카운트가 왜 이 값인가?"에 대한 답을 얻을 수 없었습니다. 새 시스템에서는 이를 해결하기 위해 각 예약을 개별 레코드로 저장합니다.
// ReservationSoldCount (일간 예약 현황)
{
hospitalId: "H001",
unitKey: "진료실A",
date: 2025-01-02,
reservedTime: [
{
startTime: "10:00",
endTime: "10:30",
online: 1, ← 온라인(앱) 예약
reservationId: "R001", ← 추적 가능!
createdAt: 2025-01-01T15:30:00
},
{
startTime: "10:00",
endTime: "10:10",
offline: 1, ← 현장 예약
createdAt: 2025-01-02T09:55:00
},
{
startTime: "10:30",
endTime: "10:40",
online: 1,
reservationId: "R002",
createdAt: 2025-01-01T16:00:00
}
]
}
이 구조의 장점은 다음과 같습니다.
추적 가능성. 앱을 통한 온라인 예약의 경우, ��각 레코드에 reservationId가 기록되므로 특정 예약이 카운트에 반영되었는지 바로 확인할 수 있습니다. 현장 예약은 reservationId 없이 offline 카운트만 기록되지만, 시간대와 생성 시각으로 충분히 추적 가능합니다. 기존에는 불가능했던 "이 카운트가 왜 이 값인가?"에 대한 답을 얻을 수 있게 되었습니다.
정확한 취소 처리. 예약 취소 시 해당 reservationId를 가진 레코드만 정확하게 제거합니다. 기존처럼 숫자를 -1 하는 방식이 아니기 때문에, 비정상적인 마이너스 값이 발생할 여지가 없습니다.
온라인/오프라인 구분. 앱을 통한 예약(online)과 현장 접수(offline)를 별도 필드로 관리하여, 채널별 예약 현황을 파악할 수 있습니다.
겹침 기반 카운트 계산. 앞서 설명한 시간 겹침 판정을 이 배열에 적용합니다. 특정 슬롯의 예약 수를 확인할 때, 해당 슬롯과 시간이 겹치는 레코드의 online + offline 값을 합산합니다. 이로써 가변 길이 슬롯 환경에서도 정확한 예약 수를 계산할 수 있습니다.
6. 마치며
이번 예약 시스템 개편을 통해 얻은 교훈을 정리하면 다음과 같습니다.
첫째, 도메인을 정확히 이해해야 합니다. "예약"이라는 단순해 보이는 기능도, 가변 시간 슬롯, 동시성 제어, 예약 이력 추적 등 고려할 요소가 많았습니다. 병원마다 다른 진료 항목과 소요 시간이라는 도메인 특성을 깊이 이해한 것이 올바른 설계의 출발점이었습니다.
둘째, 최종 상태만 저장하면 디버깅이 어렵습니다. 단순 카운트에서 개별 레코드 방식으로의 전환은 데이터 크기를 다소 늘렸지만, 문제 발생 시의 추적 용이성과 데이터 정합성 면에서 훨씬 나은 선택이었습니다.
셋째, 락 전략은 세밀할수록 좋습니다. 시간 범위 전체에 하나의 락을 거는 대신 5분 단위로 분할한 것은 불필요한 대기를 줄이면서도 정확한 충돌 감지를 가능하게 했습니다.
앞으로도 사용자 피드백을 반영하며 지속적으로 개선해 나갈 예정입니다.
긴 글 읽어주셔서 감사합니다.